- Programming Example: Moving to a DL Framework
- The Problem of Saturated Neurons and Vanishing Gradients
- Initialization and Normalization Techniques to Avoid Saturated Neurons
- Cross-Entropy Loss Function to Mitigate Effect of Saturated Output Neurons
- Different Activation Functions to Avoid Vanishing Gradient in Hidden Layers
- Variations on Gradient Descent to Improve Learning
- Experiment: Tweaking Network and Learning Parameters
- Hyperparameter Tuning and Cross-Validation
- Concluding Remarks on the Path Toward Deep Learning
This chapter is from the book
This chapter is from the book
This chapter is from the book
Initialization and Normalization Techniques to Avoid Saturated Neurons
We now explore how we can prevent or address the problem of saturated neurons. Three techniques that are commonly used—and often combined—are weight initialization, input standardization, and batch normalization.
Weight Initialization
The first step in avoiding saturated neurons is to ensure that our neurons are not saturated to begin with, and this is where weight initialization is important. It is worth noting that, although we use the same type of neurons in our different examples, the actual parameters for the neurons that we have shown are much different. In the XOR example, the neurons in the hidden layer had three inputs including the bias, whereas for the digit classification example, the neurons in the hidden layer had 785 inputs. With that many inputs, it is not hard to imagine that the weighted sum can swing far in either the negative or positive direction if there is just a little imbalance in the number of negative versus positive inputs if the weights are large. From that perspective, it kind of makes sense that if a neuron has a large number of inputs, then we want to initialize the weights to a smaller value to have a reasonable probability of still keeping the input to the activation function close to 0 to avoid saturation. Two popular weight initialization strategies are Glorot initialization (Glorot and Bengio, 2010) and He initialization (He et al., 2015b). Glorot initialization is recommended for tanh- and sigmoid-based neurons, and He initialization is recommended for ReLU-based neurons (described later). Both of these take the number of inputs into account, and Glorot initialization also takes the number of outputs into account. Both Glorot and He initialization exist in two flavors, one that is based on a uniform random distribution and one that is based on a normal random distribution.
We have previously seen how we can initialize the weights from a uniform random distribution in TensorFlow by using an initializer, as was done in Code Snippet 5-4. We can choose a different initializer by declaring any one of the supported initializers in Keras. In particular, we can declare a Glorot and a He initializer in the following way:
initializer = keras.initializers.glorot_uniform() initializer = keras.initializers.he_normal()
Parameters to control these initializers can be passed to the initializer constructor. In addition, both the Glorot and He initializers come in the two flavors uniform and normal. We picked uniform for Glorot and normal for He because that is what was described in the publications where they were introduced.
If you do not feel the need to tweak any of the parameters, then there is no need to declare an initializer object at all, but you can just pass the name of the initializer as a string to the function where you create the layer. This is shown in Code Snippet 5-5, where the kernel_initializer argument is set to 'glorot_uniform'.
Code Snippet 5-5 Setting an Initializer by Passing Its Name as a String
model = keras.Sequential([
keras.layers.Flatten(input_shape=(28, 28)),
keras.layers.Dense(25, activation='tanh',
kernel_initializer='glorot_uniform',
bias_initializer='zeros'),
keras.layers.Dense(10, activation='sigmoid',
kernel_initializer='glorot_uniform',
bias_initializer='zeros')])
We can separately set bias_initializer to any suitable initializer, but as previously stated, a good starting recommendation is to just initialize the bias weights to 0, which is what the 'zeros' initializer does.
Input Standardization
In addition to initializing the weights properly, it is important to preprocess the input data. In particular, standardizing the input data to be centered around 0 and with most values close to 0 will reduce the risk of saturating neurons from the start. We have already used this in our implementation; let us discuss it in a little bit more detail. As stated earlier, each pixel in the MNIST dataset is represented by an integer between 0 and 255, where 0 represents the blank paper and a higher value represents pixels where the digit was written.1 Most of the pixels will be either 0 or a value close to 255, where only the edges of the digits are somewhere in between. Further, a majority of the pixels will be 0 because a digit is sparse and does not cover the entire 28×28 image. If we compute the average pixel value for the entire dataset, then it turns out that it is about 33. Clearly, if we used the raw pixel values as inputs to our neurons, then there would be a big risk that the neurons would be far into the saturation region. By subtracting the mean and dividing by the standard deviation, we ensure that the neurons get presented with input data that is in the region that does not lead to saturation.
Batch Normalization
Normalizing the inputs does not necessarily prevent saturation of neurons for hidden layers, and to address that problem Ioffe and Szegedy (2015) introduced batch normalization. The idea is to normalize values inside of the network as well and thereby prevent hidden neurons from becoming saturated. This may sound somewhat counterintuitive. If we normalize the output of a neuron, does that not result in undoing the work of that neuron? That would be the case if it truly was just normalizing the values, but the batch normalization function also contains parameters to counteract this effect. These parameters are adjusted during the learning process. Noteworthy is that after the initial idea was published, subsequent work indicated that the reason batch normalization works is different than the initial explanation (Santurkar et al., 2018).
There are two main ways to apply batch normalization. In the original paper, the suggestion was to apply the normalization on the input to the activation function (after the weighted sum). This is shown to the left in Figure 5-3.
){kind=link}
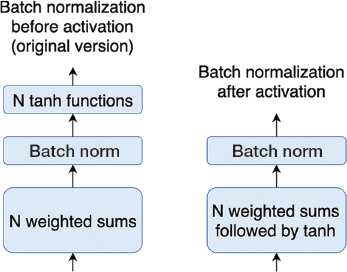
FIGURE 5-3 Left: Batch normalization as presented by Ioffe and Szegedy (2015). The layer of neurons is broken up into two parts. The first part is the weighted sums for all neurons. Batch normalization is applied to these weighted sums. The activation function (tanh) is applied to the output of the batch normalization operation. Right: Batch normalization is applied to the output of the activation functions.
This can be implemented in Keras by instantiating a layer without an activation function, followed by a BatchNormalization layer, and then apply an activation function without any new neurons, using the Activation layer. This is shown in Code Snippet 5-6.
Code Snippet 5-6 Batch Normalization before Activation Function
keras.layers.Dense(64),
keras.layers.BatchNormalization(),
keras.layers.Activation('tanh'),
However, it turns out that batch normalization also works well if done after the activation function, as shown to the right in Figure 5-3. This alternative implementation is shown in Code Snippet 5-7.
Code Snippet 5-7 Batch Normalization after Activation Function
keras.layers.Dense(64, activation='tanh'), keras.layers.BatchNormalization(),