Functional-Concurrent Programming
- 26.1 Correctness and Performance Issues with Blocking
- 26.2 Callbacks
- 26.3 Higher-Order Functions on Futures
- 26.4 Function flatMap on Futures
- 26.5 Illustration: Parallel Server Revisited
- 26.6 Functional-Concurrent Programming Patterns
- 26.7 Summary
Actions with side effects can be registered as callbacks, but the full power of this approach comes from applying functional transformations to futures to produce new futures, a coding style this book refers to as functional-concurrent programming.
This chapter is from the book
This chapter is from the book
This chapter is from the book
Functional tasks can be handled as futures, which implement the basic synchronization needed to wait for completion and to retrieve computed values (or exceptions). As synchronizers, however, futures suffer from the same drawbacks as other blocking operations, including performance costs and the risk of deadlocks. As an alternative, futures are often enriched with higher-order methods that process their values asynchronously, without blocking. Actions with side effects can be registered as callbacks, but the full power of this approach comes from applying functional transformations to futures to produce new futures, a coding style this book refers to as functional-concurrent programming.
26.1 Correctness and Performance Issues with Blocking
In Chapter 25, we looked at futures as data-carrying synchronizers. Futures can be used to simplify concurrent programming, especially compared to error-prone, do-it-yourself, lock-based strategies (e.g., Listings 22.3 and 22.4).
However, because they block threads, all synchronizers suffer from the same weaknesses—and that includes futures. Earlier, we discussed the possibility of misusing synchronizers in such a way that threads end up waiting for each other in a cycle, resulting in a deadlock. Synchronization deadlocks can happen with futures as well and can actually be quite sneaky—running the server of Listing 25.2 on a single thread pool is a mistake that is easy to make.
Before going back to this server example, consider first, as an illustration, a naive implementation of a parallel quick-sort:
Scala
Listing 26.1: Deadlock-prone parallel quick-sort; see also Lis. 26.5.
// DON'T DO THIS!
def quickSort(list: List[Int], exec: ExecutorService): List[Int] =
list match
case Nil => list
case pivot :: others =>
val (low, high) = others.partition(_ < pivot)
val lowFuture = exec.submit(() => quickSort(low, exec))
val highSorted = quickSort(high, exec)
lowFuture.get() ::: pivot :: highSorted
This method follows the same pattern as the previous implementation of quick-sort in Listing 10.1. The only difference is that the function uses a separate thread to sort the low values, while the current thread sorts the high values, thus sorting both lists in parallel. After both lists have been sorted, the sorted low values are retrieved using method get, and the two lists are concatenated around the pivot as before. This is the same pattern used in the server example to fetch a customized ad in the background except that the task used to create the future is the function itself, recursively.
At first, the code appears to be working well enough. You can use quickSort to successfully sort a small list of numbers:
Scala
val exec = Executors.newFixedThreadPool(3) quickSort(List(1, 6, 8, 6, 1, 8, 2, 8, 9), exec) // List(1, 1, 2, 6, 6, 8, 8, 8, 9)
However, if you use the same three-thread pool in an attempt to sort the list [5,4,1,3,2], the function gets stuck and fails to terminate. Looking at a thread dump would show that all three threads are blocked on a call lowFuture.get in a deadlock.
Figure 26.1 displays the state of the computation at this point as a tree. Each sorting task is split into three branches: low, pivot, and high. The thread that first invokes quickSort is called main here. It splits the list into a pivot (5), a low list ([4,1,3,2]), and a high list ([]). It quickly sorts the empty list itself, and then blocks, waiting for the sorting of list [4,1,3,2] to complete. Similar steps are taking place with the thread in charge of sorting list [4,1,3,2], and so on, recursively. In the end, the three workers from the thread pool are blocked on three sorting tasks: [1,3,2], [2], and []. This last task—sorting the empty list at the bottom left of Figure 26.1—sits in the queue of the thread pool, as there is no thread left to run it.
){kind=link}
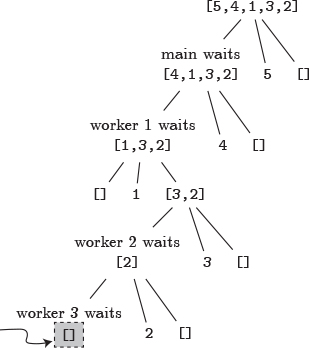
Figure 26.1 Deadlock as a result of tasks created by tasks.
This faulty implementation of quick-sort works adequately on computations with short low lists, even if the high lists are long. You can use it to sort the already sorted list [1,2,...,100] on a three-thread pool, for instance. However, the function fails when low lists are long, even if high lists are short. On the same three-thread pool, it cannot sort the list [5,4,1,3,2], or even the list [4,3,2,1].
Tasks that recursively create more tasks on the same thread pool are a common source of deadlocks. In fact, that problem is so prevalent that special thread pools were designed to handle it (see Section 27.3). Recursive tasks will get you in trouble easily, but as soon as tasks wait for completion of other tasks on the same thread pool, the risk of deadlock is present, even without recursion. This is why the server in Listing 25.2 uses two separate thread pools. Its handleConnection function—stripped here of code that is not relevant to the discussion—involves the following steps:
Scala
Listing 26.2: Ad-fetching example; contrast with Lis. 26.3, 26.6, and 26.7.
val futureAd: Future[Ad] = exec.submit(() => fetchAd(request)) // a Java future val data: Data = dbLookup(request) val page: Page = makePage(data, futureAd.get()) connection.write(page)
With a single pool of N threads, you could end up with N simultaneous connections, and thus N concurrent runs of function handleConnection. Each run would submit an ad-fetching task to the pool, with no thread to execute it. All the runs would then be stuck, forever waiting on futureAd.get.
Avoiding these deadlock situations is typically not easy. You may have to add many threads to a pool to make sure that deadlocks cannot happen, but large numbers of threads can be detrimental to performance. It is quite possible—likely, even—that most runs will block only a small subset of threads, nowhere near a deadlock situation, and leave too many active threads that use CPU resources. Some situations are hopeless: In the worst case, the naive quick-sort example would need as many threads as there are values in the list to guarantee that a computation remains free of deadlock.
Even if you find yourself in a better situation and deadlocks can be avoided with a pool of moderate size, waiting on futures still incurs a non-negligible cost. Blocking—on any kind of synchronizer, including locks—requires parking a thread, saving its execution stack, and later restoring the stack and restarting the thread. A parked thread also tends to see its data in a processor-level cache overwritten by other computations, resulting in cache misses when the thread resumes execution. This can have drastic consequences on performance.
Avoiding deadlocks should, of course, be your primary concern, but these performance costs cannot always be ignored. Thus, they constitute another incentive to reduce thread blocking. Several strategies have been proposed to minimize blocking, and some are described in detail in Chapter 27. For now, we will focus on a functional-concurrent programming style that uses futures through higher-order functions without blocking. It departs from the more familiar reliance on synchronizers and as such takes some getting used to. Once mastered, it is a powerful way to arrange concurrent programs.