- 1.1 Our First Program
- 1.2 Variables
- 1.3 Operators
- 1.4 Expressions and Statements
- 1.5 Functions
- 1.6 Error Handling
- 1.7 I/O
- 1.8 Arrays, Pointers, and References
- 1.9 Structuring Software Projects
- 1.10 Exercises
This chapter is from the book
This chapter is from the book
This chapter is from the book
1.8 Arrays, Pointers, and References
1.8.1 Arrays
The intrinsic array support of C++ has certain limitations and some strange behaviors. Nonetheless, we feel that every C++ programmer should know it and be aware of its problems. An array is declared as follows:
int x[10];
The variable x is an array with 10 int entries. In standard C++, the size of the array must be constant and known at compile time. Some compilers (e.g., g++) support run-time sizes.
Arrays are accessed by square brackets: x[i] is a reference to the i-th element of x. The first element is x[0]; the last one is x[9]. Arrays can be initialized at the definition:
float v[]= {1.0, 2.0, 3.0}, w[]= {7.0, 8.0, 9.0};
In this case, the array size is deduced.
C++11 The list initialization in C++11 forbids the narrowing of the values. This will rarely make a difference in practice. For instance, the following:
int v []= {1.0, 2.0, 3.0}; // Error in C++11: narrowing
was legal in C++03 but not in C++11 since the conversion from a floating-point literal to int potentially loses precision. However, we would not write such ugly code anyway.
Operations on arrays are typically performed in loops; e.g., to compute x = v – 3w as a vector operation is realized by
float x[3];
for (int i= 0; i < 3; ++i)
x[i]= v[i] - 3.0 * w[i];
We can also define arrays of higher dimensions:
float A[7][9]; // a 7 by 9 matrix int q[3][2][3]; // a 3 by 2 by 3 array
The language does not provide linear algebra operations upon the arrays. Implementations based on arrays are inelegant and error prone. For instance, a function for a vector addition would look like this:
void vector_add(unsigned size, const double v1[], const double v2[],
double s[])
{
for (unsigned i= 0; i < size; ++i)
s[i]= v1[i] + v2[i];
}
Note that we passed the size of the arrays as the first function parameter whereas array parameters don’t contain size information.17 In this case, the function’s caller is responsible for passing the correct size of the arrays:
int main ()
{
double x[]= {2, 3, 4}, y[]= {4, 2, 0}, sum[3];
vector_add(3, x, y, sum);
...
}
Since the array size is known during compilation, we can compute it by dividing the byte size of the array by that of a single entry:
vector_add(sizeof x / sizeof x[0], x, y, sum);
With this old-fashioned interface, we are also unable to test whether our arrays match in size. Sadly enough, C and Fortran libraries with such interfaces where size information is passed as function arguments are still realized today. They crash at the slightest user mistake, and it can take enormous effort to trace back the reasons for crashing. For that reason, we will show in this book how we can realize our own math software that is easier to use and less prone to errors. Hopefully, future C++ standards will come with more higher mathematics, especially a linear-algebra library.
Arrays have the following two disadvantages:
Indices are not checked before accessing an array, and we can find ourselves outside the array when the program crashes with segmentation fault/violation. This is not even the worst case; at least we see that something goes wrong. The false access can also mess up our data; the program keeps running and produces entirely wrong results with whatever consequence you can imagine. We could even overwrite the program code. Then our data is interpreted as machine operations leading to any possible nonsense.
The size of the array must be known at compile time.18 This is a serious problem when we fill an array with data from a file:
ifstream ifs("some_array.dat"); ifs ≫ size; float v[size]; // Error: size not known at compile timeThis does not work when the number of entries in the file varies.
The first problem can only be solved with new array types and the second one with dynamic allocation. This leads us to pointers.
1.8.2 Pointers
A pointer is a variable that contains a memory address. This address can be that of another variable provided by the address operator (e.g., &x) or dynamically allocated memory. Let’s start with the latter as we were looking for arrays of dynamic size.
int* y= new int[10];
This allocates an array of 10 int. The size can now be chosen at run time. We can also implement the vector-reading example from the preceding section:
ifstream ifs("some_array.dat");
int size;
ifs ≫ size;
float* v= new float[size];
for (int i= 0; i < size; ++i)
ifs ≫ v[i];
Pointers bear the same danger as arrays: accessing data out of range, which can cause program crashes or silent data invalidation. When dealing with dynamically allocated arrays, it is the programmer’s responsibility to store the array size.
Furthermore, the programmer is responsible for releasing the memory when it is not needed anymore. This is done by:
delete[] v;
Since arrays as function parameters are compatible with pointers, the vector_add function from Section 1.8.1 works with pointers as well:
int main (int argc, char* argv[])
{
const int size= 3;
double *x= new double[size], *y= new double[size],
*sum= new double[3];
for (unsigned i= 0; i < size; ++i)
x[i]= i+2, y[i]= 4-2*i;
vector_add(size, x, y, sum);
...
}
With pointers, we cannot use the sizeof trick; it would only give us the byte size of the pointer itself, which is of course independent of the number of entries. Other than that, pointers and arrays are interchangeable in most situations: a pointer can be passed as an array argument (as in the preceding listing) and an array as a pointer argument. The only place where they are really different is the definition: whereas defining an array of size n reserves space for n entries, defining a pointer only reserves the space to hold an address.
Since we started with arrays, we took the second step before the first one regarding pointer usage. The simple use of pointers is allocating one single data item:
int* ip= new int;
Releasing this memory is performed by:
delete ip;
Note the duality of allocation and release: the single-object allocation requires a single-object release and the array allocation demands an array release. Otherwise the run-time system might handle the deallocation incorrectly and crash at this point or corrupt some data. Pointers can also refer to other variables:
int i= 3; int* ip2= &i;
The operator & takes an object and returns its address. The opposite operator is * which takes an address and returns an object:
int j= *ip2;
This is called Dereferencing. Given the operator priorities and the grammar rules, the meaning of the symbol * as dereference or multiplication cannot be confused—at least not by the compiler.
C++11 Pointers that are not initialized contain a random value (whatever bits are set in the corresponding memory). Using uninitialized pointers can cause any kind of error. To say explicitly that a pointer is not pointing to something, we should set it to
int* ip3= nullptr; // >= C++11
int* ip4{}; // ditto
or in old compilers:
int* ip3= 0; // better not in C++11 and later int* ip4= NULL; // ditto
C++11 The address 0 is guaranteed never to be used for applications, so it is safe to indicate this way that the pointer is empty (not referring to something). Nonetheless, the literal 0 does not clearly convey its intention and can cause ambiguities in function overloading. The macro NULL is not better: it just evaluates to 0. C++11 introduces nullptr as a keyword for a pointer literal. It can be assigned to or compared with all pointer types. As nullptr cannot be confused with types that aren’t pointers and it is self-explanatory, this is the preferred notation. The initialization with an empty braced list also sets a nullptr.
Very frequent errors with pointers are Memory Leaks. For instance, our array y became too small and we want to assign a new array:
int* y= new int[10]; // some stuff y= new int[15];
Initially we allocated space for 10 int values. Later we needed more and allocated 15 int locations. But what happened to the memory that we allocated before? It is still there but we have no access to it anymore. We cannot even release it because this requires the address of that memory block. This memory is lost for the rest of our program execution. Only when the program is finished will the operating system be able to free it. In our example, we only lost 40 bytes out of several gigabytes that we might have. But if this happens in an iterative process, the unused memory grows continuously until at some point the whole (virtual) memory is exhausted.
Even if the wasted memory is not critical for the application at hand, when we write high-quality scientific software, memory leaks are unacceptable. When many people are using our software, sooner or later somebody will criticize us for it and eventually discourage other people from using it. Fortunately, tools are available to help us find memory leaks, as demonstrated in Section B.3.
The demonstrated issues with pointers are not intended to be “fun killers.”. And we do not discourage the use of pointers. Many things can only be achieved with pointers: lists, queues, trees, graphs, et cetera. But pointers must be used with care to avoid all the really severe problems mentioned above. There are three strategies to minimize pointer-related errors:
Use standard containers from the standard library or other validated libraries. std::vector from the standard library provides us all the functionality of dynamic arrays, including resizing and range check, and the memory is released automatically.
Encapsulate dynamic memory management in classes. Then we have to deal with it only once per class.19 When all memory allocated by an object is released when the object is destroyed, it does not matter how often we allocate memory. If we have 738 objects with dynamic memory, then it will be released 738 times. The memory should be allocated in the object construction and deallocated in its destruction. This principle is called Resource Acquisition Is Initialization (RAII). In contrast, if we called new 738 times, partly in loops and branches, can we be sure that we have called delete exactly 738 times? We know that there are tools for this, but these are errors that are better prevented than fixed.20 Of course, the encapsulation idea is not idiot-proof, but it is much less work to get it right than sprinkling (raw) pointers all over our program. We will discuss RAII in more detail in Section 2.4.2.1.
Use smart pointers, which we will introduce in the next section (§1.8.3).
Pointers serve two purposes:
Referring to objects
Managing dynamic memory
The problem with so-called Raw Pointers is that we have no notion whether a pointer is only referring to data or also in charge of releasing the memory when it is not needed any longer. To make this distinction explicit at the type level, we can use Smart Pointers.
C++11 1.8.3 Smart Pointers
Three new smart-pointer types are introduced in C++11: unique_ptr, shared_ptr, and weak_ptr. The already-existing smart pointer from C++03 named auto_ptr is generally considered as a failed attempt on the way to unique_ptr since the language was not ready at the time. It was therefore removed in C++17. All smart pointers are defined in the header <memory>. If you cannot use C++11 features on your platform (e.g., in embedded programming), the smart pointers in Boost are a decent replacement.
C++11 1.8.3.1 Unique Pointer
This pointer’s name indicates Unique Ownership of the referred data. It can be used essentially like an ordinary pointer:
#include <memory>
int main ()
{
unique_ptr<double> dp{new double};
*dp= 7;
...
cout ≪ " The value of *dp is " ≪ *dp ≪ endl;
}
The main difference from a raw pointer is that the memory is automatically released when the pointer expires. Therefore, it is a bug to assign addresses that are not allocated dynamically:
double d= 7.2;
unique_ptr<double> dd{&d}; // Error : causes illegal deletion
The destructor of pointer dd will try to delete d. To guarantee the uniqueness of the memory ownership, a unique_ptr cannot be copied:
unique_ptr<double> dp2{dp}; // Error : no copy allowed
dp2= dp; // ditto
However, we can transfer the memory location to another unique_ptr:
unique_ptr<double> dp2{move(dp)}, dp3;
dp3= move(dp2);
using move. The details of move semantics will be discussed in Section 2.3.5. In our example, the ownership of the referred memory is first passed from dp to dp2 and then to dp3. dp and dp2 are nullptr afterward, and the destructor of dp3 will release the memory. In the same manner, the memory’s ownership is passed when a unique_ptr is returned from a function. In the following example, dp3 takes over the memory allocated in f():
std::unique_ptr<double> f()
{ return std::unique_ptr <double>{ new double }; }
int main ()
{
unique_ptr<double> dp3;
dp3 = f();
}
In this case, move() is not needed since the function result is a temporary that will be moved (again, details in §2.3.5).
Unique pointer has a special implementation21 for arrays. This is necessary for properly releasing the memory (with delete[]). In addition, the specialization provides array-like access to the elements:
unique_ptr<double[]> da{new double[3]};
for (unsigned i= 0; i < 3; ++i)
da[i]= i+2;
In return, the operator* is not available for arrays.
An important benefit of unique_ptr is that it has absolutely no overhead over raw pointers: neither in time nor in memory.
Further reading: An advanced feature of unique pointers is to provide its own Deleter; for details see [40, §5.2.5f], [62, §34.3.1], or an online reference (e.g., cppreference.com).
C++11 1.8.3.2 Shared Pointer
As its name indicates, a shared_ptr manages memory that is shared between multiple parties (each holding a pointer to it). The memory is automatically released as soon as no shared_ptr is referring the data any longer. This can simplify a program considerably, especially with complicated data structures. An extremely important application area is concurrency: the memory is automatically freed when all threads have terminated their access to it. In contrast to a unique_ptr, a shared_ptr can be copied as often as desired, e.g.:
shared_ptr<double> f()
{
shared_ptr<double> p1{new double};
shared_ptr<double> p2{new double}, p3= p1;
cout ≪ "p3.use_count() = " ≪ p3.use_count() ≪ endl;
return p3;
}
int main ()
{
shared_ptr<double> p= f();
cout ≪ "p.use_count() = " ≪ p.use_count() ≪ endl;
}
In this example, we allocated memory for two double values: in p1 and in p2. The pointer p1 is copied into p3 so that both point to the same memory, as illustrated in Figure 1–1.
)
Figure 1–1: Shared pointer in memory
We can see this from the output of use_count:
p3.use_count() = 2 p.use_count() = 1
When f returns, the pointers are destroyed and the memory referred to by p2 is released (without ever being used). The second allocated memory block still exists since p from the main function is still referring to it.
If possible, a shared_ptr should be created with make_shared:
shared_ptr<double> p1= make_shared<double>();
Then the internal and the user data are stored together in memory—as shown in Figure 1–2—and the memory caching is more efficient. make_shared also provides better exception safety because we have only one memory allocation. As it is obvious that make_shared returns a shared pointer, we can use automatic type detection (§3.4.1) for simplicity:
){kind=link}
auto p1= make_shared<double>();
We have to admit that a shared_ptr has some overhead in memory and run time. On the other hand, the simplification of our programs thanks to shared_ptr is in most cases worth some small overhead.
Further reading: For deleters and other details of shared_ptr see the library reference [40, §5.2], [62, §34.3.2], or an online reference.
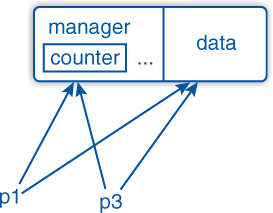
Figure 1–2: Shared pointer in memory after make_shared
C++11 1.8.3.3 Weak Pointer
A problem that can occur with shared pointers is Cyclic References that impede the memory to be released. Such cycles can be broken by weak_ptrs. They do not claim ownership of the memory, not even a shared one. At this point, we only mention them for completeness and suggest that you read appropriate references when their need is established: [40, §5.2.2], [62, §34.3.3], or cppreference.com.
For managing memory dynamically, there is no alternative to pointers. To only refer to other objects, we can use another language feature called Reference (surprise, surprise), which we introduce in the next section.
1.8.4 References
The following code introduces a reference:
int i= 5; int& j= i; j= 4; std::cout ≪ "i = " ≪ i ≪ '\n';
The variable j is referring to i. Changing j will also alter i and vice versa, as in the example. i and j will always have the same value. One can think of a reference as an alias: it introduces a new name for an existing object or subobject. Whenever we define a reference, we must directly declare what it refers to (other than pointers). It is not possible to refer to another variable later.
References are even more useful for function arguments (§1.5), for referring to parts of other objects (e.g., the seventh entry of a vector), and for building views (e.g., §5.2.3).
C++11 As a compromise between pointers and references, C++11 offers a reference_wrapper class which behaves similarly to references but avoids some of their limitations. For instance, it can be used within containers; see §4.4.8.
1.8.5 Comparison between Pointers and References
The main advantage of pointers over references is the ability of dynamic memory management and address calculation. On the other hand, references are forced to refer to existing locations.22 Thus, they do not leave memory leaks (unless you play really evil tricks), and they have the same notation in usage as the referred object. Unfortunately, it is almost impossible to construct containers of references (use reference_wrapper instead).
In short, references are not fail-safe but are much less error-prone than pointers. Pointers should only be used when dealing with dynamic memory, for instance, when we create data structures like lists or trees dynamically. Even then we should do this via well-tested types or encapsulate the pointer(s) within a class whenever possible. Smart pointers take care of memory allocation and should be preferred over raw pointers, even within classes. The pointer–reference comparison is summarized in Table 1-9.
Table 1–9: Comparison between Pointers and References
Feature |
Pointers |
References |
|---|---|---|
Referring to defined location |
✓ |
|
Mandatory initialization |
✓ |
|
Avoidance of memory leaks |
✓ |
|
Object-like notation |
✓ |
|
Memory management |
✓ |
|
Address calculation |
✓ |
|
Build containers thereof |
✓ |
1.8.6 Do Not Refer to Outdated Data!
Function-local variables are only valid within the function’s scope, for instance:
double& square_ref(double d) // Error: returns stale reference
{
double s= d * d;
return s; // Error: s will be out of scope
}
Here, our function result refers the local variable s which does not exist after the function end. The memory where it was stored is still there and we might be lucky (mistakenly) that it is not overwritten yet. But this is nothing we can count on. Finally, such situation-dependent errors are worse than permanent ones: on the one hand, they are harder to debug, and on the other, they can go unnoticed despite extensive testing and cause greater damage later in real usage.
References to variables that no longer exist are called Stale References. Sadly enough, we have seen such examples even in some web tutorials.
The same applies to pointers:
double* square_ptr(double d) // Error: returns dangling pointer
{
double s= d * d;
return &s; // Error : s will be out of scope
}
This pointer holds the address of a local variable that has already gone out of scope. This is called a Dangling Pointer.
Returning references or pointers can be correct in member functions when referring to member data (see Section 2.6) or to static variables.
By “objects with reference semantic” we mean objects that don’t contain all their data but refer to external data that is not replicated when the object is copied; in other words, objects that have, at least partially, the behavior of a pointer and thus the risk of referring to something that doesn’t exist anymore. In Section 4.1.2 we will introduce iterators, which are classes from the standard library or from users with a pointer-like behavior, and the danger of referring to already destroyed objects.
Compilers are fortunately getting better and better at detecting such errors, and all current compilers should warn us of obviously stale references or dangling pointers as in the examples above. But the situation is not always so obvious, especially when we have a user class with reference semantics.
1.8.7 Containers for Arrays
As alternatives to the traditional C arrays, we want to introduce two container types that can be used in similar ways but cause fewer problems.
1.8.7.1 Standard Vector
Arrays and pointers are part of the C++ core language. In contrast, std::vector belongs to the standard library and is implemented as a class template. Nonetheless, it can be used very similarly to arrays. For instance, the example from Section 1.8.1 of setting up two arrays v and w looks for vectors as follows:
#include <vector>
int main ()
{
std::vector <float> v(3), w(3);
v[0]= 1; v[1]= 2; v[2]= 3;
w[0]= 7; w[1]= 8; w[2]= 9;
}
The size of the vector does not need to be known at compile time. Vectors can even be resized during their lifetime, as will be shown in Section 4.1.3.1.
C++11 The element-wise setting is not particularly concise. C++11 allows the initialization with initializer lists:
std::vector<float> v= {1, 2, 3}, w= {7, 8, 9};
In this case, the size of the vector is implied by the length of the list. The vector addition shown before can be implemented more reliably:
void vector_add(const vector<float>& v1, const vector<float>& v2,
vector<float>& s)
{
assert(v1.size() == v2.size());
assert(v1.size() == s.size());
for (unsigned i= 0; i < v1.size(); ++i)
s[i]= v1[i] + v2[i];
}
In contrast to C arrays and pointers, the vector arguments know their sizes and we can now check whether they match. Note that the array size can be deduced with templates, which we’ll show later in Section 3.3.2.1.
Vectors are copyable and can be returned by functions. This allows us to use a more natural notation:
vector<float> add(const vector<float>& v1, const vector<float>& v2)
{
assert(v1.size() == v2.size());
vector<float> s(v1.size());
for (unsigned i= 0; i < v1.size(); ++i)
s[i]= v1[i] + v2[i];
return s;
}
int main ()
{
std::vector<float> v= {1 , 2, 3}, w= {7, 8, 9}, s= add(v, w);
}
This implementation is potentially more expensive than the preceding one where the target vector is passed in as a reference. We will later discuss the possibilities of optimization: on both the compiler and user sides. In our experience, it is more important to start with a productive interface and deal with performance later. It is easier to make a correct program fast than to make a fast program correct. Thus, aim first for a good program design. In almost all cases, the favorable interface can be realized with sufficient performance.
The container std::vector is not a vector in the mathematical sense. There are no arithmetic operations. Nonetheless, the container proved very useful in scientific applications to handle nonscalar intermediate results.
1.8.7.2 valarray
A valarray is a one-dimensional array with element-wise operations; even the multiplication is performed element-wise. Operations with a scalar value are performed respectively with each element of the valarray. Thus, the valarray of a floating-point number is a vector space.
The following example demonstrates some operations:
#include <iostream>
#include <valarray>
int main ()
{
std::valarray<float> v= {1, 2, 3}, w= {7, 8, 9},
s= v + 2.0f * w;
v= sin (s);
for (float x : v)
std::cout ≪ x ≪ ' ';
std::cout ≪ '\n';
}
Note that a valarray<float> can only operate with itself or float. For instance, 2 * w would fail since it is an unsupported multiplication of int with valarray<float>.
A strength of valarray is the ability to access slices of it. This allows us to Emulate matrices and higher-order tensors, including their respective operations. Nonetheless, due to the lack of direct support of most linear-algebra operations, valarray is not widely used in the numeric community. We also recommend using established C++ libraries for linear algebra. Hopefully, future standards will contain one.
To complete the topic of dynamic memory management, we refer to Section A.2.8 where Garbage Collection is briefly described. The bottom line is that a C++ programmer can pretty well live without it and no compiler supports it (yet?) anyway.