- Troubleshooting Principles
- Structured Troubleshooting Approaches
- Troubleshooting Example Using Six Different Approaches
- Summary
- Review Questions
This chapter is from the book
This chapter is from the book
This chapter is from the book
Structured Troubleshooting Approaches
Troubleshooting is not an exact science, and a particular problem can be diagnosed and sometimes even solved in many different ways. However, when you perform structured troubleshooting, you make continuous progress, and usually solve the problem faster than it would take using an ad hoc approach. There are many different structured troubleshooting approaches. For some problems, one method might work better, whereas for others, another method might be more suitable. Therefore, it is beneficial for the troubleshooter to be familiar with a variety of structured approaches and select the best method or combination of methods to solve a particular problem.
A structured troubleshooting method is used as a guideline through a troubleshooting process. The key to all structured troubleshooting methods is systematic elimination of hypothetical causes and narrowing down on the possible causes. By systematically eliminating possible problem causes, you can reduce the scope of the problem until you manage to isolate and solve the problem. If at some point you decide to seek help or hand the task over to someone else, your findings can be of help to that person and your efforts are not wasted. Commonly used troubleshooting approaches include the following:
The top-down approach: Using this approach, you work from the Open Systems Interconnection (OSI) model’s application layer down to the physical layer. The OSI seven-layer networking model and TCP/IP four-layer model are shown side by side in Figure 1-3 for your reference.
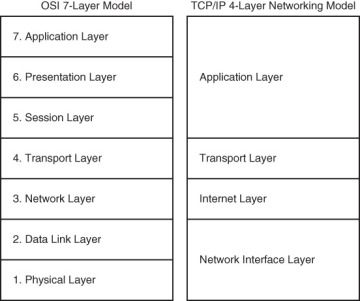
Figure 1-3 The OSI and TCP/IP Networking Models
- The bottom-up approach: This approach starts from the OSI model’s physical layer and moves up toward the application layer.
- The divide-and-conquer approach: Using this approach, you start in the middle of the OSI model’s stack (usually the network layer), and then, based on your findings, you move up or down the OSI stack.
- The follow-the-path approach: This approach is based on the path that packets take through the network from source to destination.
- The spot-the-differences approach: As the name implies, this approach compares network devices or processes that are operating correctly to devices or processes that are not operating as expected and gathers clues by spotting significant differences. In case the problem occurred after a change on a single device was implemented, the spot-the differences approach can pinpoint the problem cause by focusing on the difference between the device configurations, before and after the problem was reported.
- The move-the-problem approach: The strategy of this troubleshooting approach is to physically move components and observe whether the problem moves with the moved components.
)
The sections that follow describe each of these methods in more detail.
The Top-Down Troubleshooting Approach
The top-down troubleshooting method uses the OSI model as a guiding principle. One of the most important characteristics of the OSI model is that each layer depends on the underlying layers for its operation. This implies that if you find a layer to be operational, you can safely assume that all underlying layers are fully operational as well.
Let’s assume that you are researching a problem of a user that cannot browse a particular website and you find that you can establish a TCP connection on port 80 from this host to the server and get a response from the server (see Figure 1-4). In this situation, it is reasonable to conclude that the transport layer and all layers below must be fully functional between the client and the server and that this is most likely a client or server problem (most likely at application, presentation, or session layer) and not a network problem. Be aware that in this example it is reasonable to conclude that Layers 1 through 4 must be fully operational, but it does not definitively prove this. For instance, nonfragmented packets might be routed correctly, whereas fragmented packets are dropped. The TCP connection to port 80 might not uncover such a problem.
)
Figure 1-4 Application Layer Failure
Essentially, the goal of the top-down approach is to find the highest OSI layer that is still working. All devices and processes that work on that layer or layers below are then eliminated from the scope of the troubleshooting. It might be clear that this approach is most effective if the problem is on one of the higher OSI layers. It is also one of the most straightforward troubleshooting approaches, because problems reported by users are typically defined as application layer problems, so starting the troubleshooting process at that layer is a natural thing to do. A drawback or impediment to this approach is that you need to have access to the client’s application layer software to initiate the troubleshooting process, and if the software is only installed on a small number of machines, your troubleshooting options might be limited.
The Bottom-Up Troubleshooting Approach
The bottom-up troubleshooting approach also uses the OSI model as its guiding principle with the physical layer (bottom layer of the OSI seven-layer network model) as the starting point. In this approach, you work your way layer by layer up toward the application layer and verify that relevant network elements are operating correctly. You try to eliminate more and more potential problem causes so that you can narrow down the scope of the potential problems.
Let’s assume that you are researching a problem of a user that cannot browse a particular website and while you are verifying the problem, you find that the user’s workstation is not even able to obtain an IP address through the DHCP process (see Figure 1-5). In this situation it is reasonable to suspect lower layers of the OSI model and take a bottom-up troubleshooting approach.
)
Figure 1-5 Failure at Lower OSI Layers
A benefit of the bottom-up approach is that all the initial troubleshooting takes place on the network, so access to clients, servers, or applications is not necessary until a very late stage in the troubleshooting process. In certain environments, especially those where many old and outdated devices and technologies are still in use, many network problems are hardware related. The bottom-up approach is very effective under those circumstances. A disadvantage of this method is that, in large networks, it can be a time-consuming process because a lot of effort will be spent on gathering and analyzing data and you always start from the bottom layer. The best bottom-up approach is to first reduce the scope of the problem using a different strategy and then switch to the bottom-up approach for clearly bounded parts of the network topology.
The Divide-and-Conquer Troubleshooting Approach
The divide-and-conquer troubleshooting approach strikes a balance between the top-down and bottom-up troubleshooting approaches. If it is not clear which of the top-down or bottom-up approaches will be more effective for a particular problem, an alternative is to start in the middle (usually from the network layer) and perform some tests such as ping and trace. Ping is an excellent connectivity testing tool. If the test is successful, you can assume that all lower layers are functional, and so you can start a bottom-up troubleshooting starting from the network layer. However, if the test fails, you can start a top-down troubleshooting starting from the network layer.
Let’s assume that you are researching a problem of a user who cannot browse a particular website and that while you are verifying the problem you find that the user’s workstation can successfully ping the server’s IP address (see Figure 1-6). In this situation, it is reasonable to assume that the physical, data link, and network layers of the OSI model are in good working condition, and so you examine the upper layers, starting from the transport layer in a bottom-up approach.
)
Figure 1-6 Successful Ping Shifts the Focus to Upper OSI Layers (Divide-and-Conquer Approach)
Whether the result of the initial test is positive or negative, the divide-and-conquer approach usually results in a faster elimination of potential problems than what you would achieve by implementing a full top-down or bottom-up approach. Therefore, the divide-and-conquer method is considered highly effective and possibly the most popular troubleshooting approach.
The Follow-the-Path Troubleshooting Approach
The follow-the-path approach is one of the most basic troubleshooting techniques, and it usually complements one of the other troubleshooting methods such as the top-down or the bottom-up approach. The follow-the-path approach first discovers the actual traffic path all the way from source to destination. Next, the scope of troubleshooting is reduced to just the links and devices that are actually in the forwarding path. The principle of this approach is to eliminate the links and devices that are irrelevant to the troubleshooting task at hand.
Let’s assume that you are researching a problem of a user who cannot browse a particular website and that while you are verifying the problem you find that a trace (tracert) from the user’s PC command prompt to the server’s IP address succeeds only as far as the first hop, which is the L3 Switch v (Layer 3 or Multilayer Switch v) in Figure 1-7. Based on your understanding of the network link bandwidths and the routing protocol used on this network, you mark the links on the best path between the user workstation and the server on the diagram with numbers 1 through 7, as shown in Figure 1-7.
)
Figure 1-7 The Follow-the-Path Approach Shifts the Focus to Link 3 and Beyond Toward the Server
In this situation it is reasonable to shift your troubleshooting approach to the L3 Switch v and the segments beyond, toward the server along the best path. The follow-the-path approach can quickly lead you to the problem area. You can then try and pinpoint the problem to a device, and ultimately to a particular physical or logical component that is either broken, misconfigured, or has a bug.
The Compare-Configurations Troubleshooting Approach
Another common troubleshooting approach is called the compare-configurations approach, also referred to as the spotting-the-differences approach. By comparing configurations, software versions, hardware, or other device properties between working and nonworking situations and spotting significant differences between them, this approach attempts to resolve the problem by changing the nonoperational elements to be consistent with the working ones. The weakness of this method is that it might lead to a working situation, without clearly revealing the root cause of the problem. In some cases, you are not sure whether you have implemented a solution or a workaround.
Example 1-1 shows two routing tables; one belongs to Branch2’s edge router, experiencing problems, and the other belongs to Branch1’s edge router, with no problems. If you compare the content of these routing tables, as per the compare-configurations (spotting-the-differences) approach, a natural deduction is that the branch with problems is missing a static entry. The static entry can be added to see whether it solves the problem.
Example 1-1 Spot-the-Differences: One Malfunctioning and One Working Router
------------- Branch1 is in good working order ---------- Branch1# show ip route <...output omitted...> 10.0.0.0/24 is subnetted, 1 subnets C 10.132.125.0 is directly connected, FastEthernet4 C 192.168.36.0/24 is directly connected, BVI1 S* 0.0.0.0/0 [254/0] via 10.132.125.1 ------------- Branch2 has connectivity problems ---------- Branch2# show ip route <...output omitted...> 10.0.0.0/24 is subnetted, 1 subnets C 10.132.126.0 is directly connected, FastEthernet4 C 192.168.37.0/24 is directly connected, BVI1
The compare-configurations approach (spotting-the-differences) is not a complete approach; it is, however, a good technique to use undertaking other approaches. One benefit of this approach is that it can easily be used by less-experienced troubleshooting staff to at least shed more light on the case. When you have an up-to-date and accessible set of baseline configurations, diagrams, and so on, spotting the difference between the current configuration and the baseline might help you solve the problem faster than any other approach.
The Swap-Components Troubleshooting Approach
Also called move-the-problem, the swap-components approach is a very elementary troubleshooting technique that you can use for problem isolation: You physically swap components and observe whether the problem stays in place, moves with the component, or disappears entirely. Figure 1-8 shows two PCs and three laptops connected to a LAN switch, among which laptop B has connectivity problems. Assuming that hardware failure is suspected, you must discover whether the problem is on the switch, the cable, or the laptop. One approach is to start gathering data by checking the settings on the laptop with problems, examining the settings on the switch, comparing the settings of all the laptops, and the switch ports, and so on. However, you might not have the required administrative passwords for the PCs, laptops, and the switch. The only data that you can gather is the status of the link LEDs on the switch and the laptops and PCs. What you can do is obviously limited. A common way to at least isolate the problem (if it is not solved outright) is cable or port swapping. Swap the cable between a working device and laptop B (the one that is having problems). Move the laptop from one port to another using a cable that you know for sure is good. Based on these simple moves, you can isolate whether the problem is cable, switch, or laptop related.
)
Figure 1-8 Swap-the-Component: Laptop B Is Having Network Problems
Just by executing simple tests in a methodical way, the swap-components approach enables you to isolate the problem even if the information that you can gather is minimal. Even if you do not solve the problem, you have scoped it to a single element, and you can now focus further troubleshooting on that element. Note that in the previous example if you determine that the problem is cable related, it is unnecessary to obtain the administrative password for the switch, PCs, and laptops. The drawbacks of this method are that you are isolating the problem to only a limited set of physical elements and not gaining any real insight into what is happening, because you are gathering only very limited indirect information. This method assumes that the problem is with a single component. If the problem lies within multiple devices, you might not be able to isolate the problem correctly.