This chapter is from the book
This chapter is from the book
This chapter is from the book
15.3. Implementation Platform
15.3.1. Selection Criteria
The kinds of choices discussed in this section are important. We want to introduce them now, and we want them all in one place so that you can refer to them later. Many of them will only seem natural to you after you’ve worked with graphics for a while. So read this section now, set it aside, and then read it again in a month.
In your studies of computer graphics you will likely learn many APIs and software design patterns. For example, Chapters 2, 4, 6, and 16 teach the 2D and 3D WPF APIs and some infrastructure built around them.
Teaching that kind of content is expressly not a goal of this chapter. This chapter is about creating algorithms for sampling light. The implementation serves to make the algorithms concrete and provide a test bed for later exploration. Although learning a specific platform is not a goal, learning the issues to consider when evaluating a platform is a goal; in this section we describe those issues.
We select one specific platform, a subset of the G3D Innovation Engine [http://g3d.sf.net] Version 9, for the code examples. You may use this one, or some variation chosen after considering the same issues weighed by your own goals and computing environment. In many ways it is better if your platform—language, compiler, support classes, hardware API—is not precisely the same as the one described here. The platform we select includes only a minimalist set of support classes. This keeps the presentation simple and generic, as suits a textbook. But you’re developing software on today’s technology, not writing a textbook that must serve independent of currently popular tools.
Since you’re about to invest a lot of work on this renderer, a richer set of support classes will make both implementation and debugging easier. You can compile our code directly against the support classes in G3D. However, if you have to rewrite it slightly for a different API or language, this will force you to actually read every line and consider why it was written in a particular manner. Maybe your chosen language has a different syntax than ours for passing a parameter by value instead of reference, for example. In the process of redeclaring a parameter to make this syntax change, you should think about why the parameter was passed by value in the first place, and whether the computational overhead or software abstraction of doing so is justified.
To avoid distracting details, for the low-level renderers we’ll write the image to an array in memory and then stop. Beyond a trivial PPM-file writing routine, we will not discuss the system-specific methods for saving that image to disk or displaying it on-screen in this chapter. Those are generally straightforward, but verbose to read and tedious to configure. The PPM routine is a proof of concept, but it is for an inefficient format and requires you to use an external viewer to check each result. G3D and many other platforms have image-display and image-writing procedures that can present the images that you’ve rendered more conveniently.
For the API-based hardware rasterizer, we will use a lightly abstracted subset of the OpenGL API that is representative of most other hardware APIs. We’ll intentionally skip the system-specific details of initializing a hardware context and exploiting features of a particular API or GPU. Those transient aspects can be found in your favorite API or GPU vendor’s manuals.
Although we can largely ignore the surrounding platform, we must still choose a programming language. It is wise to choose a language with reasonably high-level abstractions like classes and operator overloading. These help the algorithm shine through the source code notation.
It is also wise to choose a language that can be compiled to efficient native code. That is because even though performance should not be the ultimate consideration in graphics, it is a fairly important one. Even simple video game scenes contain millions of polygons and are rendered for displays with millions of pixels. We’ll start with one triangle and one pixel to make debugging easier and then quickly grow to hundreds of each in this chapter. The constant overhead of an interpreted language or a managed memory system cannot affect the asymptotic behavior of our program. However, it can be the difference between our renderer producing an image in two seconds or two hours . . . and debugging a program that takes two hours to run is very unpleasant.
Computer graphics code tends to combine high-level classes containing significant state, such as those representing scenes and objects, with low-level classes (a.k.a. “records”, “structs”) for storing points and colors that have little state and often expose that which they do contain directly to the programmer. A real-time renderer can easily process billions of those low-level classes per second. To support that, one typically requires a language with features for efficiently creating, destroying, and storing such classes. Heap memory management for small classes tends to be expensive and thwart cache efficiency, so stack allocation is typically the preferred solution. Language features for passing by value and by constant reference help the programmer to control cloning of both large and small class instances.
Finally, hardware APIs tend to be specified at the machine level, in terms of bytes and pointers (as abstracted by the C language). They also often require manual control over memory allocation, deallocation, types, and mapping to operate efficiently.
To satisfy the demands of high-level abstraction, reasonable performance for hundreds to millions of primitives and pixels, and direct manipulation of memory, we work within a subset of C++. Except for some minor syntactic variations, this subset should be largely familiar to Java and Objective C++ programmers. It is a superset of C and can be compiled directly as native (nonmanaged) C#. For all of these reasons, and because there is a significant tools and library ecosystem built for it, C++ happens to be the dominant language for implementing renderers today. Thus, our choice is consistent with showing you how renderers are really implemented.
Note that many hardware APIs also have wrappers for higher-level languages, provided by either the API vendor or third parties. Once you are familiar with the basic functionality, we suggest that it may be more productive to use such a wrapper for extensive software development on a hardware API.
15.3.2. Utility Classes
This chapter assumes the existence of obvious utility classes, such as those sketched in Listing 15.4. For these, you can use equivalents of the WPF classes, the Direct3D API versions, the built-in GLSL, Cg, and HLSL shading language versions, or the ones in G3D, or you can simply write your own. Following common practice, the Vector3 and Color3 classes denote the axes over which a quantity varies, but not its units. For example, Vector3 always denotes three spatial axes but may represent a unitless direction vector at one code location and a position in meters at another. We use a type alias to at least distinguish points from vectors (which are differences of points).
Listing 15.4: Utility classes.
1#defineINFINITY (numeric_limits<float>::infinity()) 2 3classVector2{public:floatx, y; ... }; 4classVector3{public:floatx, y, z; ... }; 5typedefVector2 Point2; 6typedefVector3 Point3; 7classColor3{public:floatr, g, b; ... }; 8classRadiance3 Color3; 9classPower3 Color3; 10 11classRay{ 12private: 13Point3m_origin; 14Vector3m_direction; 15 16public: 17Ray(constPoint3& org,constVector3& dir) : 18 m_origin(org), m_direction(dir) {} 19 20constPoint3& origin()const{returnm_origin; } 21constVector3& direction()const{returnm_direction; } 22 ... 23 };
Observe that some classes, such as Vector3, expose their representation through public member variables, while others, such as Ray, have a stronger abstraction that protects the internal representation behind methods. The exposed classes are the workhorses of computer graphics. Invoking methods to access their fields would add significant syntactic distraction to the implementation of any function. Since the byte layouts of these classes must be known and fixed to interact directly with hardware APIs, they cannot be strong abstractions and it makes sense to allow direct access to their representation. The classes that protect their representation are ones whose representation we may (and truthfully, will) later want to change. For example, the internal representation of Triangle in this listing is an array of vertices. If we found that we computed the edge vectors or face normal frequently, then it might be more efficient to extend the representation to explicitly store those values.
For images, we choose the underlying representation to be an array of Radiance3, each array entry representing the radiance incident at the center of one pixel in the image. We then wrap this array in a class to present it as a 2D structure with appropriate utility methods in Listing 15.5.
Listing 15.5: An Image class.
1classImage{ 2private: 3intm_width; 4intm_height; 5 std::vector<Radiance3> m_data; 6 7 int PPMGammaEncode(floatradiance,floatdisplayConstant)const; 8 9public: 10 11 Image(intwidth,intheight) : 12 m_width(width), m_height(height), m_data(width * height) {} 13 14intwidth()const{returnm_width; } 15 16intheight()const{returnm_height; } 17 18voidset(intx,inty,constRadiance3& value) { 19 m_data[x + y * m_width] = value; 20 } 21 22constRadiance3& get(intx,inty) const { 23returnm_data[x + y * m_width]; 24 } 25 26voidsave(conststd::string& filename,floatdisplayConstant=15.0f)const; 27 };
Under C++ conventions and syntax, the & following a type in a declaration indicates that the corresponding variable or return value will be passed by reference. The m_ prefix avoids confusion between member variables and methods or parameters with similar names. The std::vector class is the dynamic array from the standard library.
One could imagine a more feature-rich image class with bounds checking, documentation, and utility functions. Extending the implementation with these is a good exercise.
The set and get methods follow the historical row-major mapping from a 2D to a 1D array. Although we do not need it here, note that the reverse mapping from a 1D index i to the 2D indices (x, y) is
x = i % width; y = i / width
where % is the C++ integer modulo operation.
 When width is a power of two, that is, width = 2k, it is possible to perform both the forward and reverse mappings using bitwise operations, since
When width is a power of two, that is, width = 2k, it is possible to perform both the forward and reverse mappings using bitwise operations, since
)
)
)
for fixed-point values. Here we use » as the operator to shift the bits of the left operand to the right by the value of the right operand, and & as the bitwise AND operator.
This is one reason that many graphics APIs historically required power-of-two image dimensions (another is MIP mapping). One can always express a number that is not a power of two as the sum of multiple powers of two. In fact, that’s what binary encoding does! For example, 640 = 512 + 128, so x + 640y = x + (y«9) + (y«7).
Familiarity with the bit-manipulation methods for mapping between 1D and 2D arrays is important now so that you can understand other people’s code. It will also help you to appreciate how hardware-accelerated rendering might implement some low-level operations and why a rendering API might have certain constraints. However, this kind of micro-optimization will not substantially affect the performance of your renderer at this stage, so it is not yet worth including.
Our Image class stores physically meaningful values. The natural measurement of the light arriving along a ray is in terms of radiance, whose definition and precise units are described in Chapter 26. The image typically represents the light about to fall onto each pixel of a sensor or area of a piece of film. It doesn’t represent the sensor response process.
Displays and image files tend to work with arbitrarily scaled 8-bit display values that map nonlinearly to radiance. For example, if we set the display pixel value to 64, the display pixel does not emit twice the radiance that it does when we set the same pixel to 32. This means that we cannot display our image faithfully by simply rescaling radiance to display values. In fact, the relationship involves an exponent commonly called gamma, as described briefly below and at length in Section 28.12.
Assume some multiplicative factor d that rescales the radiance values in an image so that the largest value we wish to represent maps to 1.0 and the smallest maps to 0.0. This fills the role of the camera’s shutter and aperture. The user will select this value as part of the scene definition. Mapping it to a GUI slider is often a good idea.
Historically, most images stored 8-bit values whose meanings were illspecified. Today it is more common to specify what they mean. An image that actually stores radiance values is informally said to store linear radiance, indicating that the pixel value varies linearly with the radiance (see Chapter 17). Since the radiance range of a typical outdoor scene with shadows might span six orders of magnitude, the data would suffer from perceptible quantization artifacts were it reduced to eight bits per channel. However, human perception of brightness is roughly logarithmic. This means that distributing precision nonlinearly can reduce the perceptual error of a small bit-depth approximation. Gamma encoding is a common practice for distributing values according to a fractional power law, where 1/γ is the power. This encoding curve roughly matches the logarithmic response curve of the human visual system. Most computer displays accept input already gamma-encoded along the sRGB standard curve, which is about γ = 2.2. Many image file formats, such as PPM, also default to this gamma encoding. A routine that maps a radiance value to an 8-bit display value with a gamma value of 2.2 is:
1intImage::PPMGammaEncode(floatradiance,floatd)const{ 2return int(pow(std::min(1.0f, std::max(0.0f, radiance * d)), 3 1.0f / 2.2f) * 255.0f); 4 }
Note that x1/2.2 ≈ 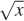 . Because they are faster than arbitrary exponentiation on most hardware, square root and square are often employed in real-time rendering as efficient γ = 2.0 encoding and decoding methods.
. Because they are faster than arbitrary exponentiation on most hardware, square root and square are often employed in real-time rendering as efficient γ = 2.0 encoding and decoding methods.
The save routine is our bare-bones method for exporting data from the renderer for viewing. It saves the image in human-readable PPM format [P+10] and is implemented in Listing 15.6.
Listing 15.6: Saving an image to an ASCII RGB PPM file.
1voidImage::save(conststd::string& filename,floatd)const{ 2 FILE* file = fopen(filename.c_str(),"wt"); 3 fprintf(file,"P3 %d %d 255\n", m_width, m_height); 4for(inty = 0; y < m_height; ++y) { 5 fprintf(file,"\n# y = %d\n", y); 6for(intx = 0; x < m_width; ++x) { 7constRadiance3& c(get(x, y)); 8 fprintf(file,"%d %d %d\n", 9 PPMGammaEncode(c.r, d), 10 PPMGammaEncode(c.g, d), 11 PPMGammaEncode(c.b, d)); 12 } 13 } 14 fclose(file); 15 }
This is a useful snippet of code beyond its immediate purpose of saving an image. The structure appears frequently in 2D graphics code. The outer loop iterates over rows. It contains any kind of per-row computation (in this case, printing the row number). The inner loop iterates over the columns of one row and performs the per-pixel operations. Note that if we wished to amortize the cost of computing y * m_width inside the get routine, we could compute that as a perrow operation and merely accumulate the 1-pixel offsets in the inner loop. We do not do so in this case because that would complicate the code without providing a measurable performance increase, since writing a formatted text file would remain slow compared to performing one multiplication per pixel.
The PPM format is slow for loading and saving, and consumes lots of space when storing images. For those reasons, it is rarely used outside academia. However, it is convenient for data interchange between programs. It is also convenient for debugging small images for three reasons. The first is that it is easy to read and write. The second is that many image programs and libraries support it, including Adobe Photoshop and xv. The third is that we can open it in a text editor to look directly at the (gamma-corrected) pixel values.
After writing the image-saving code, we displayed the simple pattern shown in Figure 15.2 as a debugging aid. If you implement your own image saving or display mechanism, consider doing something similar. The test pattern alternates dark blue pixels with ones that form a gradient. The reason for creating the single-pixel checkerboard pattern is to verify that the image was neither stretched nor cropped during display. If it was, then one or more thin horizontal or vertical lines would appear. (If you are looking at this image on an electronic display, you may see such patterns, indicating that your viewing software is indeed stretching it.) The motivation for the gradient is to determine whether gamma correction is being applied correctly. A linear radiance gradient should appear as a nonlinear brightness gradient, when displayed correctly. Specifically, it should primarily look like the brighter shades. The pattern on the left is shown without gamma correction. The gradient appears to have linear brightness, indicating that it is not displayed correctly. The pattern on the right is shown with gamma correction. The gradient correctly appears to be heavily shifted toward the brighter shaders.
)
Figure 15.2: A pattern for testing the Image class. The pattern is a checkerboard of 1-pixel squares that alternate between 1/10 W/(m2 sr) in the blue channel and a vertical gradient from 0 to 10. (a) Viewed with deviceGamma = 1.0 and displayConstant = 1.0, which makes dim squares appear black and gives the appearance of a linear change in brightness. (b) Displayed more correctly with deviceGamma = 2.0, where the linear radiance gradient correctly appears as a nonlinear brightness ramp and the dim squares are correctly visible. (The conversion to a printed image or your online image viewer may further affect the image.)
Note that we made the darker squares blue, yet in the left pattern—without gamma correction—they appear black. That is because gamma correction helps make darker shades more visible, as in the right image. This hue shift is another argument for being careful to always implement gamma correction, beyond the tone shift. Of course, we don’t know the exact characteristics of the display (although one can typically determine its gamma exponent) or the exact viewing conditions of the room, so precise color correction and tone mapping is beyond our ability here. However, the simple act of applying gamma correction arguably captures some of the most important aspects of that process and is computationally inexpensive and robust.
Inline Exercise 15.3:
Two images are shown below. Both have been gamma-encoded with γ = 2.0 for printing and online display. The image on the left is a gradient that has been rendered to give the impression of linear brightness. It should appear as a linear color ramp. The image on the right was rendered with linear radiance (it is the checkerboard on the right of Figure 15.2 without the blue squares). It should appear as a nonlinear color ramp. The image was rendered at 200 × 200 pixels. What equation did we use to compute the value (in [0, 1]) of the pixel at (x, y) for the gradient image on the left?
)
15.3.3. Scene Representation
Listing 15.7 shows a Triangle class. It stores each triangle by explicitly storing each vertex. Each vertex has an associated normal that is used exclusively for shading; the normals do not describe the actual geometry. These are sometimes called shading normals. When the vertex normals are identical to the normal to the plane of the triangle, the triangle’s shading will appear consistent with its actual geometry. When the normals diverge from this, the shading will mimic that of a curved surface. Since the silhouette of the triangle will still be polygonal, this effect is most convincing in a scene containing many small triangles.
Listing 15.7: Interface for a Triangle class.
1classTriangle{ 2private: 3Point3m_vertex[3]; 4Vector3m_normal[3]; 5BSDFm_bsdf; 6 7public: 8 9constPoint3& vertex(inti)const{returnm_vertex[i]; } 10constVector3& normal(inti)const{returnm_normal[i]; } 11constBSDF& bsdf()const{returnm_bsdf; } 12 ... 13 };
We also associate a BSDF class value with each triangle. This describes the material properties of the surface modeled by the triangle. It is described in Section 15.4.5. For now, think of this as the color of the triangle.
The representation of the triangle is concealed by making the member variables private. Although the implementation shown contains methods that simply return those member variables, you will later use this abstraction boundary to create a more efficient implementation of the triangle. For example, many triangles may share the same vertices and bidirectional scattering distribution functions (BSDFs), so this representation is not very space-efficient. There are also properties of the triangle, such as the edge lengths and geometric normal, that we will find ourselves frequently recomputing and could benefit from storing explicitly.
Listing 15.8 shows our implementation of an omnidirectional point light source. We represent the power it emits at three wavelengths (or in three wavelength bands), and the center of the emitter. Note that emitters are infinitely small in our representation, so they are not themselves visible. If we wish to see the source appear in the final rendering we need to either add geometry around it or explicitly render additional information into the image. We will do neither explicitly in this chapter, although you may find that these are necessary when debugging your illumination code.
Listing 15.8: Interface for a uniform point luminaire—a light source.
1classLight{ 2public: 3Point3position; 4 5/** Over the entire sphere. */6Power3power; 7 };
Listing 15.9 describes the scene as sets of triangles and lights. Our choice of arrays for the implementation of these sets imposes an ordering on the scene. This is convenient for ensuring a reproducible environment for debugging. However, for now we are going to create that ordering in an arbitrary way, and that choice may affect performance and even our image in some slight ways, such as resolving ties between which surface is closest at an intersection. More sophisticated scene data structures may include additional structure in the scene and impose a specific ordering.
Listing 15.9: Interface for a scene represented as an unstructured list of triangles and light sources.
1classScene{ 2public: 3 std::vector<Triangle> triangleArray; 4 std::vector<Light> lightArray; 5 };
Listing 15.10 represents our camera. The camera has a pinhole aperture, an instantaneous shutter, and artificial near and far planes of constant (negative) z values. We assume that the camera is located at the origin and facing along the –z-axis.
Listing 15.10: Interface for a pinhole camera at the origin.
1classCamera{ 2public: 3floatzNear; 4floatzFar; 5floatfieldOfViewX; 6 7Camera() : zNear(-0.1f), zFar(-100.0f), fieldOfViewX(PI / 2.0f) {} 8 };
We constrain the horizontal field of view of the camera to be fieldOfViewX. This is the measure of the angle from the center of the leftmost pixel to the center of the rightmost pixel along the horizon in the camera’s view in radians (it is shown later in Figure 15.3). During rendering, we will compute the aspect ratio of the target image and implicitly use that to determine the vertical field of view. We could alternatively specify the vertical field of view and compute the horizontal field of view from the aspect ratio.
){kind=link}
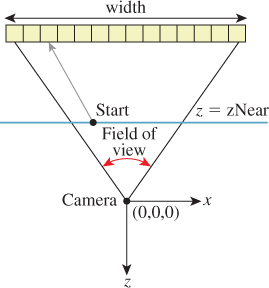
Figure 15.3: The ray through a pixel center in terms of the image resolution and the camera’s horizontal field of view.
15.3.4. A Test Scene
We’ll test our renderers on a scene that contains one triangle whose vertices are
Point3(0,1,-2), Point3(-1.9,-1,-2), and Point3(1.6,-0.5,-2),
and whose vertex normals are
Vector3( 0.0f, 0.6f, 1.0f).direction(), Vector3(-0.4f,-0.4f, 1.0f).direction(), and Vector3( 0.4f,-0.4f, 1.0f).direction().
We create one light source in the scene, located at Point3(1.0f,3.0f,1.0f) and emitting power Power3(10, 10, 10). The camera is at the origin and is facing along the –z-axis, with y increasing upward in screen space and x increasing to the right. The image has size 800 × 500 and is initialized to dark blue.
This choice of scene data was deliberate, because when debugging it is a good idea to choose configurations that use nonsquare aspect ratios, nonprimary colors, asymmetric objects, etc. to help find cases where you have accidentally swapped axes or color channels. Having distinct values for the properties of each vertex also makes it easier to track values through code. For example, on this triangle, you can determine which vertex you are examining merely by looking at its x-coordinate.
On the other hand, the camera is the standard one, which allows us to avoid transforming rays and geometry. That leads to some efficiency and simplicity in the implementation and helps with debugging because the input data maps exactly to the data rendered, and in practice, most rendering algorithms operate in the camera’s reference frame anyway.