
Like this article? We recommend
Like this article? We recommend
Like this article? We recommend
STL-Style Iteration
At the 1968 Olympics, Dick Fosbury took the athletics world by surprise with an unusual high-jump technique. Instead of using any of the known jumping styles, he jumped arching his back and facing the sky. Fosbury's style was so surprising, an ad hoc committee was formed to determine the legitimacy of its use in the competition. The committee authorized Fosbury's jumping style, and he went on to win the gold medal, making history in the process. Today, virtually all high jumpers use Fosbury's style.
The STL did something similar with the Iterator pattern. Its approach was so fresh, it could be argued that STL iterators aren't really quite the same as the Iterator pattern. STL approached iteration from a different and much more fertile perspective. The classic Iterator pattern is preoccupied with providing sequential access to containers, leaving algorithms to fend for themselves. The STL focuses on defining algorithms in their most general, universal form. Iterators tie data structures and algorithms together.
Before the STL, containers offered GoF-style iteration, and some offered index-based access. Alexander Stepanov realized that it all started with algorithms. Algorithms dictate structure over the data they manipulate. Stepanov further realized that structure must be defined in a way that's decoupled from containers. Achieving such decoupling avoids the typical combinatorial explosion of adding algorithm versions for each new container type.
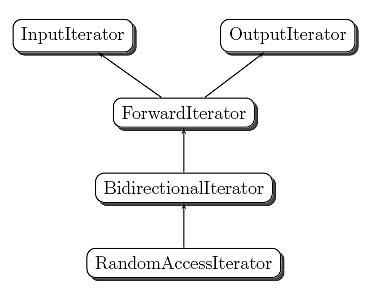
When m algorithms are coupled with n containers, there must be m [ts] n algorithm implementations. When m algorithms and n containers are decoupled, there must only be m + n algorithm implementations, which is a much lighter maintenance burden. Decoupling algorithms and containers drove the STL iterator design. It became apparent that different algorithms required different iteration strategies. Some required forward iteration, others bidirectional iteration, some random access iteration, etc. This led to the STL providing a hierarchy of iterator concepts.
"Iterator concepts" is kind of new but rather yawnworthy: sky's blue, water's wet, and different algorithms work best with different iteration primitives. The remarkable fact is not that there are different categories of iterators. It's that there are only a few of them. You see, if 50 algorithms required 30 different categories of iterators, that design would be unwieldy. Conceptual categories are like function parameters: If there are too many of them, then probably something went wrong. STL has shown that a very generous collection of algorithms can be implemented with only five iterator categories:
- Input iterators, modeling one-pass input such as reading from files or network streams
- Output iterators, modeling one-pass output such as writing to sequential files or network streams
- Forward iterators, modeling access to singly-linked lists
- Bidirectional iterators, modeling access to doubly-linked lists and (somewhat unexpectedly) UTF-encoded strings
- Random access iterators, modeling array access
The conceptual hierarchy of the five iterator categories is quite simple: input and output are the most primitive, and each of the more capable categories specializes the previous one, as shown in Figure 1.
{kind=link}
)
Figure 1 The iterator concept hierarchy in STL.
Building on Pointers
Distinguishing various categories of iterators and placing them in a conceptual hierarchy marks a definite departure of STL from the classic Iterator mold. Another distinguishing characteristic of STL is that it builds on C++'s pointers instead of defining a named API.
To access the value referenced by an STL iterator (or C++ pointer), named iter, you dereference it with the notation *iter. To advance iter to the next value, you increment it with ++iter or iter++. To copy an iterator, you simply assign iter to another variable. Finally, to determine when the range of values has been exhausted, you compare the iterator to an end-of-the-range iterator kept separately. Unlike the GoF iterator, a C++ iterator does not know when it has exhausted the range, just as a pointer traversing an array has no knowledge of the extent of the array.
Bidirectional iterators also define --iter allowing you to move one position to the left, and random access iterators define addition of an integer (e.g., iter = iter + 5), indexed access (e.g., iter[5]), and distance between iterators (e.g., int to_go = end - iter). Thanks to this setup, built-in pointers enjoyed random access iterator status—the most powerful of all—by default, without having to do anything. If you were a pointer, you were born into RandomAccessIterator royalty.
All of the above primitives take constant time. It would be possible to make iter += n work with a non-random iterator by evaluating ++iter n times, but that would take O(n) time, which in turn would wreak havoc with algorithms that rely on iter += n as a constant-time primitive.
STL's adoption of pointer-like syntax and semantics, as opposed to the traditional approach using named interface functions, was a brilliant strategic move helping rapid adoption of the library. STL algorithms worked with pointers straight out of the box, so they could be used with existing arrays without much fuss. Even better, code that used iterators looked like nicely crafted code using pointers, so people could easily relate to such code and write more of it. It all made so much sense that the usually conservative ANSI/ISO standardization committee serendipitously decided to integrate STL into C++98 without the usual lengthy committee process—and the rest, as they say, is history. To many people, STL is one of the finest libraries of containers and algorithms around. That the STL achieved such a feat in a language lacking support for Lambda functions is akin to a boxer, one arm tied behind his back, beating the champion of a heavier weight class.
Problems with STL Iterators
Time has passed, experience with the STL has grown, and people naturally started seeing issues with it and looking into ways to improve it. STL's quest—that of defining the most general and most widely applicable definitions of algorithms—has remained as worthy as ever, but it became increasingly clear that there may be more than one path to that goal.
Ad Hoc Pairing
STL's use of pointers as the basic model for abstraction meant that most of the time you need two iterators, not one, to do anything useful. A lone iterator is insufficient because you can't move it in any direction without ensuring (or, more dangerously, assuming) that it stays within its bounds. (This is reminiscent of C-style coding, where you'd need to pass arrays around as a pointer and a length.)
The need to pass most iterators around in pairs begs for an abstraction that puts them together as a cohesive unit. Without such an abstraction, code using iterators has to overcome many difficulties. For example iterator-based code is not composable. STL expects the two iterators describing a range as two distinct parameters, so you can't pass the result of a function straight into an STL function; you need to create named variables at every step along the way.
Traversal and Access
In the STL, *iter must be a reference to T and may or may not allow updates, depending on whether T is a const type. Sometimes, changing the referenced value is not even an option, as the underlying data source may be a read-only container or even an input stream.
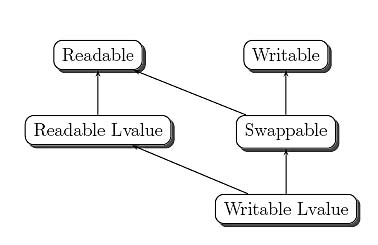
Abrahams et al. [3] draw on existing experience with the STL to propose an extension to it that separates traversal and access into orthogonal concepts. Their suggestion is to classify iterators additionally in a second hierarchy of categories. These new categories are orthogonal to the classic iterator categories in Figure 1. In brief:
- Readable iterators: You can write value = *iter.
- Writable iterators: You can write *iter = value.
- Swappable iterators: You can write iter_swap(iter1, iter2).
- lvalue iterators: You can write address = &(*iter); that is, you can take the address at which the iterated element lies in memory
Figure 2 illustrates the relationships among these categories. Any of them can be combined with one classic category in Figure 1. For example, you could define and use a bidirectional swappable iterator.
{kind=link}
)
Figure 2 The iterator access hierarchy proposed for the STL by Abrahams et al. [3]
Lack of Safety
STL iterators are unsafe in several ways. Correct pairing of iterators bracketing a range is left entirely to the user, and wrong pairings are easy to produce and expensive to check. It's also expensive to check against advancing an iterator beyond a range's bounds. In fact, none of iterator's primitives naturally support checking. Why? Because iterators are modeled after pointers, and pointers are also not naturally checkable. (Iterators also have invalidation problems—when a container changes, it may pull the rug out from under the iterators currently referring to elements of that container, but that is less of an iterator interface issue and more of a memory model issue.)
"Safe" STL implementations painstakingly address safety issues by implementing an alternative design based on "fat iterators"—pairs of iterators—to then emulate ordinary STL iterators. Such implementations are in fact mute witnesses that the abstractions from pointers come with pointers' specific problems. It would be desirable to have a design that does not need expensive logic and data to provide even a minimal level of checking.
Quirks
Various quirks of C++ make the task of defining and using iterators unduly difficult. Defining a correct iterator is notoriously hard, to the extent that Boost defined a special library to help with just that [2]. This in spite of the fact that an iterator really needs to define only three basic operations (compare, advance, and dereference). Code using iterators can be pretty complex, too. For example, naysayers commonly bring up examples like this:
vector<int> v = ...;
for (vector<int>::iterator i = v.begin();
i != v.end(); ++i)
{
... use *i ...
}
which is syntactically noisier than old-style iteration using an index, or even than the name-based GoF-style iteration. (I am not under the illusion that for_each fixes that problem, and please don't send me angry email about this.)
There are quite a few other iterator-related annoyances of increasing subtlety. Input and forward iterators are syntactically identical but subtly different semantically—copying a forward iterator saves iteration state, but copying an input iterator just creates a new view of the same iteration state. This makes for more puzzling runtime errors.
In an attempt to improve iterator usage, Adobe [4] and Boost [12] independently defined an abstraction called range that pairs two iterators together. Of course, the iterators must belong to the same logical collection (or stream). Then, algorithms can use a range whenever a pair of iterators is expected, which makes pairing errors both less likely and easier to spot. When calling an algorithm with ranges, you write:
vector<int> v; ... // implicitly take the "all" range of v sort(v);
instead of the customary:
sort(v.begin(), v.end());
If you use algorithms a lot, such ranges will simplify much of your code. Composition with ranges is significantly easier, too. Although these improvements are not insignificant, Adobe/Boost ranges can't address all of the deficiencies in the STL's design.
One subtle problem with STL generalizing C++ pointers—if you allow me a little speculation—is that its detailed design is inextricably tied to C++. That makes STL difficult to understand without actually knowing C++ to a good bit of depth; the putative newcomer who wants to get the gist of the STL without absorbing C++ will meet a wall of detail—some important, much incidental—that is liable to discourage further study. To this day, the STL is unfortunately still provincial: although revered among C++ programmers, it is virtually absent from the larger programming community. Even languages that came to the fore after the STL continue to obsess with perfecting the obsolete "straddle" high-jump technique. Why? I think it's not impossible that the authors of those languages or APIs thumbed with puzzlement through some STL examples, with this result: "This is odd… We can do this already… This is too verbose… Look at this one, it's just bizarre…. Aw, forget it. Let's just make Find a method of Array."