This chapter is from the book
This chapter is from the book
This chapter is from the book
6.8 Summary
This chapter introduced Actor-Critic algorithms. We saw that these algorithms have two components, an actor and a critic. The actor learns a policy π and the critic learns the value function Vπ. The learned 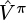 is used in combination with actual rewards to generate a reinforcing signal for the policy. The reinforcing signal is often the advantage function.
is used in combination with actual rewards to generate a reinforcing signal for the policy. The reinforcing signal is often the advantage function.
Actor-Critic algorithms combine ideas from policy-based and value-based methods that were introduced in earlier chapters. Optimizing the actor is similar to REINFORCE but with a learned reinforcing signal instead of a Monte-Carlo estimate generated from the current trajectory of rewards. Optimizing the critic is similar to DQN in that it uses the bootstrapped temporal difference learning technique.
This chapter discussed two ways to estimate the advantage function—n-step returns and GAE. Each method allows users to control the amount of bias and variance in the advantage by choosing how much to weight the actual trajectory of rewards compared to the value function estimate . The n-step advantage estimate has a hard cutoff controlled by n, whereas GAE has a soft cutoff controlled by the parameter λ.
The chapter ended with a discussion of two approaches to designing neural network architectures for Actor-Critic algorithms—either by sharing parameters or by keeping the Actor and Critic networks entirely separate.