
- What You Will Learn
- The Challenge of Big Data
- Today's Big Data Explosion
- Background for This Book
- Why the Focus on Database Sharding?
- Summary
This chapter is from the book
This chapter is from the book
This chapter is from the book
Why the Focus on Database Sharding?
You will notice as you read this book that much of the focus is on database sharding, a technique and architecture for horizontal shared-nothing partitioning of database data across independent nodes or servers. From extensive experience and research, we have found that, regardless of what DBMS you use, database sharding is the only effective means for scaling a database. This applies to all types of databases, including the traditional relational database management system (RDBMS), NoSQL platforms, Big Data engines, Cloud databases, or databases of the so-called NewSQL paradigm. If you look closely at any of these offerings, particularly if they advertise a scalable platform, you will see that some sort of horizontal partitioning of data across nodes is used. Thus, database sharding is the answer, used in one way or another for virtually every leading database platform. Figure 1.2 shows the concept of database sharding, breaking a large monolithic database into multiple, smaller, sharded database instances across multiple servers.
){kind=link}
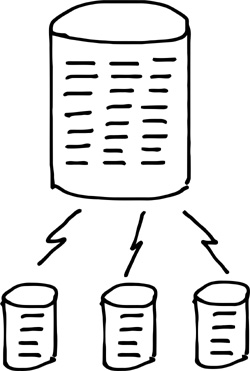
Figure 1.2 Database sharding
Understanding the underlying principles of how database sharding works is the answer to controlling your own destiny regarding the ultimate performance of your Big Data implementation. The basic concepts behind sharding and how it works are not difficult, and once you grasp them you can implement amazing levels of scalability. Ultimately this book is about making you successful with your database tier, and the more you know about this concept, the more power you will have over defining, predicting, optimizing, and controlling the performance of your own databases.