
This chapter is from the book
This chapter is from the book
This chapter is from the book
18.3 Copying
Consider again our incomplete vector:
class vector {
int sz; // the size
double* elem; // a pointer to the elements
public:
vector(int s) // constructor
:sz{s}, elem{new double[s]} { /* . . . */ } // allocates memory
~vector() // destructor
{ delete[] elem; } // deallocates memory
// . . .
};
Let’s try to copy one of these vectors:
void f(int n)
{
vector v(3); // define a vector of 3 elements
v.set(2,2.2); // set v[2] to 2.2
vector v2 = v; // what happens here?
// . . .
}
Ideally, v2 becomes a copy of v (that is, = makes copies); that is, v2.size()==v.size() and v2[i]==v[i] for all is in the range [0:v.size()). Furthermore, all memory is returned to the free store upon exit from f(). That’s what the standard library vector does (of course), but it’s not what happens for our still-far-too-simple vector. Our task is to improve our vector to get it to handle such examples correctly, but first let’s figure out what our current version actually does. Exactly what does it do wrong? How? And why? Once we know that, we can probably fix the problems. More importantly, we have a chance to recognize and avoid similar problems when we see them in other contexts.

The default meaning of copying for a class is “Copy all the data members.” That often makes perfect sense. For example, we copy a Point by copying its coordinates. But for a pointer member, just copying the members causes problems. In particular, for the vectors in our example, it means that after the copy, we have v.sz==v2.sz and v.elem==v2.elem so that our vectors look like this:
)
That is, v2 doesn’t have a copy of v’s elements; it shares v’s elements. We could write
v.set(1,99); // set v[1] to 99 v2.set(0,88); // set v2[0] to 88 cout << v.get(0) << ' ' << v2.get(1);
The result would be the output 88 99. That wasn’t what we wanted. Had there been no “hidden” connection between v and v2, we would have gotten the output 0 0, because we never wrote to v[0] or to v2[1]. You could argue that the behavior we got is “interesting,” “neat!” or “sometimes useful,” but that is not what we intended or what the standard library vector provides. Also, what happens when we return from f() is an unmitigated disaster. Then, the destructors for v and v2 are implicitly called; v’s destructor frees the storage used for the elements using
delete[] elem;
and so does v2’s destructor. Since elem points to the same memory location in both v and v2, that memory will be freed twice with likely disastrous results (§17.4.6).
18.3.1 Copy constructors
So, what do we do? We’ll do the obvious: provide a copy operation that copies the elements and make sure that this copy operation gets called when we initialize one vector with another.
Initialization of objects of a class is done by a constructor. So, we need a constructor that copies. Unsurprisingly, such a constructor is called a copy constructor. It is defined to take as its argument a reference to the object from which to copy. So, for class vector we need
vector(const vector&);
This constructor will be called when we try to initialize one vector with another. We pass by reference because we (obviously) don’t want to copy the argument of the constructor that defines copying. We pass by const reference because we don’t want to modify our argument (§8.5.6). So we refine vector like this:
class vector {
int sz;
double* elem;
public:
vector(const vector&) ; // copy constructor: define copy
// . . .
};
The copy constructor sets the number of elements (sz) and allocates memory for the elements (initializing elem) before copying element values from the argument vector:
vector:: vector(const vector& arg)
// allocate elements, then initialize them by copying
:sz{arg.sz}, elem{new double[arg.sz]}
{
copy(arg.elem,arg.elem+sz,elem); // std::copy(); see §B.5.2
}
Given this copy constructor, consider again our example:
vector v2 = v;
This definition will initialize v2 by a call of vector’s copy constructor with v as its argument. Again given a vector with three elements, we now get
)
Given that, the destructor can do the right thing. Each set of elements is correctly freed. Obviously, the two vectors are now independent so that we can change the value of elements in v without affecting v2 and vice versa. For example:
v.set(1,99); // set v[1] to 99 v2.set(0,88); // set v2[0] to 88 cout << v.get(0) << ' ' << v2.get(1);
This will output 0 0.
Instead of saying
vector v2 = v;
we could equally well have said
vector v2 {v};
When v (the initializer) and v2 (the variable being initialized) are of the same type and that type has copying conventionally defined, those two notations mean exactly the same thing and you can use whichever notation you like better.
18.3.2 Copy assignments
We handle copy construction (initialization), but we can also copy vectors by assignment. As with copy initialization, the default meaning of copy assignment is memberwise copy, so with vector as defined so far, assignment will cause a double deletion (exactly as shown for copy constructors in §18.3.1) plus a memory leak. For example:
void f2(int n)
{
vector v(3); // define a vector
v.set(2,2.2);
vector v2(4);
v2 = v; // assignment: what happens here?
// . . .
}
We would like v2to be a copy of v (and that’s what the standard library vector does), but since we have said nothing about the meaning of assignment of our vector, the default assignment is used; that is, the assignment is a memberwise copy so that v2’s sz and elem become identical to v’s sz and elem, respectively. We can illustrate that like this:
)
When we leave f2(), we have the same disaster as we had when leaving f() in §18.3 before we added the copy constructor: the elements pointed to by both v and v2 are freed twice (using delete[]). In addition, we have leaked the memory initially allocated for v2’s four elements. We “forgot” to free those. The remedy for this copy assignment is fundamentally the same as for the copy initialization (§18.3.1). We define an assignment that copies properly:
class vector {
int sz;
double* elem;
public:
vector& operator=(const vector&) ; // copy assignment
// . . .
};
vector& vector::operator=(const vector& a)
// make this vector a copy of a
{
double* p = new double[a.sz]; // allocate new space
copy(a.elem,a.elem+a.sz,elem); // copy elements
delete[] elem; // deallocate old space
elem = p; // now we can reset elem
sz = a.sz;
return *this; // return a self-reference (see §17.10)
}
Assignment is a bit more complicated than construction because we must deal with the old elements. Our basic strategy is to make a copy of the elements from the source vector:
double* p = new double[a.sz]; // allocate new space
copy(a.elem,a.elem+a.sz,elem); // copy elements
Then we free the old elements from the target vector:
delete[] elem; // deallocate old space
Finally, we let elem point to the new elements:
elem = p; // now we can reset elem sz = a.sz;
We can represent the result graphically like this:
)
We now have a vector that doesn’t leak memory and doesn’t free (delete[]) any memory twice.

When implementing the assignment, you could consider simplifying the code by freeing the memory for the old elements before creating the copy, but it is usually a very good idea not to throw away information before you know that you can replace it. Also, if you did that, strange things would happen if you assigned a vector to itself:
vector v(10);
v = v; // self-assignment
Please check that our implementation handles that case correctly (if not with optimal efficiency).
18.3.3 Copy terminology
Copying is an issue in most programs and in most programming languages. The basic issue is whether you copy a pointer (or reference) or copy the information pointed to (referred to):
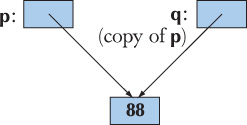
- Shallow copy copies only a pointer so that the two pointers now refer to the same object. That’s what pointers and references do.
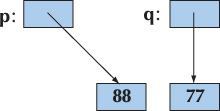
- Deep copy copies what a pointer points to so that the two pointers now refer to distinct objects. That’s what vectors, strings, etc. do. We define copy constructors and copy assignments when we want deep copy for objects of our classes.
Here is an example of shallow copy:
int* p = new int{77};
int* q = p; // copy the pointer p
*p = 88; // change the value of the int pointed to by p and q
We can illustrate that like this:
In contrast, we can do a deep copy:
int* p = new int{77};
int* q = new int{*p}; // allocate a new int, then copy the value pointed to by p
*p = 88; // change the value of the int pointed to by p
We can illustrate that like this:
Using this terminology, we can say that the problem with our original vector was that it did a shallow copy, rather than copying the elements pointed to by its elem pointer. Our improved vector, like the standard library vector, does a deep copy by allocating new space for the elements and copying their values. Types that provide shallow copy (like pointers and references) are said to have pointer semantics or reference semantics (they copy addresses). Types that provide deep copy (like string and vector) are said to have value semantics (they copy the values pointed to). From a user perspective, types with value semantics behave as if no pointers were involved — just values that can be copied. One way of thinking of types with value semantics is that they “work just like integers” as far as copying is concerned.
18.3.4 Moving
If a vector has a lot of elements, it can be expensive to copy. So, we should copy vectors only when we need to. Consider an example:
vector fill(istream& is)
{
vector res;
for (double x; is>>x; ) res.push_back(x);
return res;
}
void use()
{
vector vec = fill(cin);
// ... use vec ...
}
Here, we fill the local vector res from the input stream and return it to use(). Copying res out of fill() and into vec could be expensive. But why copy? We don’t want a copy! We can never use the original (res) after the return. In fact, res is destroyed as part of the return from fill(). So how can we avoid the copy? Consider again how a vector is represented in memory:
)
We would like to “steal” the representation of res to use for vec. In other words, we would like vec to refer to the elements of res without any copy.
After moving res’s element pointer and element count to vec, res holds no elements. We have successfully moved the value from res out of fill() to vec. Now, res can be destroyed (simply and efficiently) without any undesirable side effects:
)
We have successfully moved 100,000 doubles out of fill() and into its caller at the cost of four single-word assignments.
How do we express such a move in C++ code? We define move operations to complement the copy operations:
class vector {
int sz;
double* elem;
public:
vector(vector&& a); // move constructor
vector& operator=(vector&&); // move assignment
// . . .
};
The funny && notation is called an “rvalue reference.” We use it for defining move operations. Note that move operations do not take const arguments; that is, we write (vector&&) and not (const vector&&). Part of the purpose of a move operation is to modify the source, to make it “empty.” The definitions of move operations tend to be simple. They tend to be simpler and more efficient than their copy equivalents. For vector, we get
vector::vector(vector&& a)
:sz{a.sz}, elem{a.elem} // copy a’s elem and sz
{
a.sz = 0; // make a the empty vector
a.elem = nullptr;
}
vector& vector::operator=(vector&& a) // move a to this vector
{
delete[] elem; // deallocate old space
elem = a.elem; // copy a’s elem and sz
sz = a.sz;
a.elem = nullptr; // make a the empty vector
a.sz = 0;
return *this; // return a self-reference (see §17.10)
}
By defining a move constructor, we make it easy and cheap to move around large amounts of information, such as a vector with many elements. Consider again:
vector fill(istream& is)
{
vector res;
for (double x; is>>x; ) res.push_back(x);
return res;
}
The move constructor is implicitly used to implement the return. The compiler knows that the local value returned (res) is about to go out of scope, so it can move from it, rather than copying.

The importance of move constructors is that we do not have to deal with pointers or references to get large amounts of information out of a function. Consider this flawed (but conventional) alternative:
vector* fill2(istream& is)
{
vector* res = new vector;
for (double x; is>>x; ) res->push_back(x);
return res;
}
void use2()
{
vector* vec = fill(cin);
// ... use vec ...
delete vec;
}
Now we have to remember to delete the vector. As described in §17.4.6, deleting objects placed on the free store is not as easy to do consistently and correctly as it might seem.