
From the book
From the book
From the book
1.6 Using Language Workbenches
The two styles of DSL I’ve shown so far—internal and external—are the traditional ways of thinking about DSLs. They may not be as widely understood and used as they should be, but they have a long history and moderately wide usage. As a result, the rest of this book concentrates on getting you started with these approaches using tools that are mature and easy to obtain.
But there is a whole new category of tools on the horizon that could change the game of DSLs significantly—the tools I call language workbenches. A language workbench is an environment designed to help people create new DSLs, together with high-quality tooling required to use those DSLs effectively.
One of the big disadvantages of using an external DSL is that you’re stuck with relatively limited tooling. Setting up syntax highlighting in a text editor is about as far as most people go. While you can argue that the simplicity of a DSL and the small size of the scripts means that may be enough, there’s also an argument for the kind of sophisticated tooling that modern IDEs support. Language workbenches make it easy to define not just a parser, but also a custom editing environment for that language.
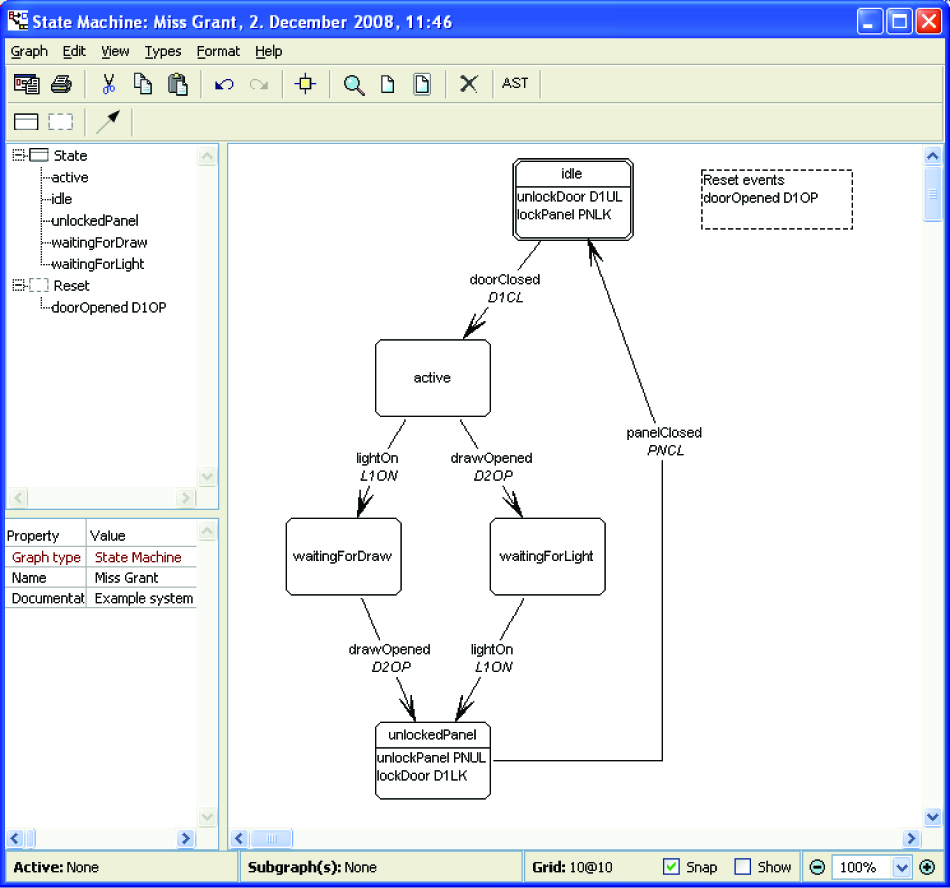
All of this is valuable, but the truly interesting aspect of language workbenches is that they allow a DSL designer to go beyond the traditional text-based source editing to different forms of language. The most obvious example of this is support for diagrammatic languages, which would allow me to specify the secret panel state machine directly with a state transition diagram.
A tool like this not only allows you to define diagrammatic languages; it also allows you to look at a DSL script from different perspectives. In Figure 1.7 we see a diagram, but it also displays lists of states and events and a table to enter the event codes (which could be omitted from the diagram if there’s too much clutter there).
{kind=link}
)
Figure 1.7 The secret panel state machine in the MetaEdit language workbench (source: MetaCase)
This kind of multipane visual editing environment has been available for a while in lots of tools, but it’s been a lot of effort to build something like this for yourself. One promise of language workbenches is that they make it quite easy to do this; indeed I was able to put together an example similar to Figure 1.7 quite quickly on my first play with the MetaEdit tool. The tool allows me to define the Semantic Model (159) for state machines, define the graphical and tabular editors in Figure 1.7, and write a code generator from the Semantic Model.
However, while such tools certainly look good, many developers are naturally suspicious of such doodleware tools. There are some very pragmatic reasons why a textual source representation makes sense. As a result, other tools head in that direction, providing post-IntelliJ-style capabilities—such as syntax-directed editing, autocompletion, and the like—for textual languages.
My suspicion is that, if language workbenches really take off, the languages they’ll produce won’t be anything like what we consider a programming language. One of the common benefits of such tools is that they allow non-programmers to program. I often sniff at that notion by pointing out that this was the original intent of COBOL. Yet I must also acknowledge a programming environment that has been extremely successful in providing programming tools to nonprogrammers who program without thinking of themselves as programmers—spreadsheets.
Many people don’t think about spreadsheets as a programming environment, yet it can be argued that they are the most successful programming environment we currently know. As a programming environment, spreadsheets have some interesting characteristics. One of these is the close integration of tooling into the programming environment. There’s no notion of a tool-independent text representation that’s processed by a parser. The tools and the language are closely intertwined and designed together.
A second interesting element is something I call illustrative programming. When you look at a spreadsheet, the thing that’s most visible isn’t the formulae that do all the calculations; rather, it’s the numbers that form a sample calculation. These numbers are an illustration of what the program does when it executes. In most programming languages, it’s the program that’s front-and-center, and we only see its output when we make a test run. In a spreadsheet, the output is front-and-center and we only see the program when we click in one of the cells.
Illustrative programming isn’t a concept that’s got much attention; I even had to make up a word to talk about it. It could be an important part of what makes spreadsheets so accessible to lay programmers. It also has disadvantages; for one thing, the lack of focus on program structure leads to lots of copy-paste programming and poorly structured programs.
Language workbenches support developing new kinds of programming platforms like this. As a result, I think the DSLs they produce are likely to be closer to a spreadsheet than to the DSLs that we usually think of (and that I talk about in this book).
I think that language workbenches have a remarkable potential. If they fulfill this they could entirely change the face of software development. Yet this potential, however profound, is still somewhat in the future. It’s still early days for language workbenches, with new approaches appearing regularly and older tools still subject to deep evolution. That is why I don’t have that much to say about them here, as I think they will change quite dramatically during the hoped-for lifetime of this book. But I do have a chapter on them at the end, as I think they are well worth keeping an eye on.