Algorithms (Video Lectures): 24-part Lecture Series
- By Robert Sedgewick, Kevin Wayne
- Published Sep 8, 2015 by Addison-Wesley Professional.
Online Video
- Your Price: $89.99
- About this video
Accessible from your Account page after purchase. Requires the free QuickTime Player software.
Videos can be viewed on: Windows 8, Windows XP, Vista, 7, and all versions of Macintosh OS X including the iPad, and other platforms that support the industry standard h.264 video codec.
Register your product to gain access to bonus material or receive a coupon.
Description
- Copyright 2016
- Edition: 1st
- Online Video
- ISBN-10: 0-13-438443-1
- ISBN-13: 978-0-13-438443-6
24+ Hours of Video Instruction
These Algorithms Video Lectures cover the essential information that every serious programmer needs to know about algorithms and data structures, with emphasis on applications and scientific performance analysis of Java implementations.
Description
This collection of video lectures provides a comprehensive exploration of fundamental data types, algorithms, and data structures, with an emphasis on applications and scientific performance analysis of Java implementations. The instructors offer readings related to these lectures that you can find in Algorithms, Fourth Edition, the leading textbook on algorithms today. These lectures provide another perspective on the material presented in the book and generally cover the material in the same order, though some book topics have been combined, rearranged, or omitted in the lectures.
Don't have the book? Purchase Algorithms, Deluxe Edition, which includes the print book and full access to the lecture videos.
You also can find related resources on the instructors' web site, including the following:
- Full Java implementations
- Test data
- Exercises and answers
- Dynamic visualizations
- Lecture slides
- Programming assignments with checklists
- Other links to related material
Customer Reviews
"This is the best explanation of algorithms I've seen in years. It covers many topics ina thorough manner that makes learning this subject delightful. Dr. Sedgewick'steaching style is engaging. I highly recommend this series."
About the Instructors
Robert Sedgewick is the William O. Baker Professor of Computer Science at Princeton University. He is a Director of Adobe Systems and has served on the research staffs at Xerox PARC, IDA, and INRIA. He earned his PhD from Stanford University under Donald E. Knuth.
Kevin Wayne also teaches in the Department of Computer Science at Princeton University. His research focuses on theoretical computer science, especially optimization and the design, analysis, and implementation of computer algorithms. Wayne received his PhD from Cornell University.
Skill Level
All Levels
What You Will Learn
These videos survey the most important computer algorithms in use today. The algorithms described in these lectures represent a body of knowledge developed of the last 50 years that has become indispensable. These lectures present:
- Implementations of useful algorithms
- Detailed information on performance characteristics
- Examples of clients and applications
The early lectures cover our fundamental approach to studying algorithms, including data types for stacks, queues, and other low-level abstractions. Then we cover these major topics:
- Sorting algorithms, highlighting the classic Quicksort and Mergesort algorithms.
- Searching algorithms, including search methods based on balanced search trees and hashing.
- String-processing algorithms, from tries and substring search to regular expression search and data compression.
- Graph algorithms, starting with graph search, shortest paths, and minimum spanning trees, and working up to maximum flow/minimum cut and applications.
- Reductions, linear programming, and intractability.
Who Should Take This Course
The study of algorithms and data structures is fundamental to any computer-science curriculum, but it is not just for programmers and computer science students. These lectures are intended for:
- Any student (from high school to graduate level) having a good introduction to programming, with an interest in majoring in any science or engineering discipline (including computer science).
- Anyone using a computer to address large problems that require an understanding of efficient algorithms.
- Anyone interested in preparing for a career in industry involving software or computer applications.
Course Requirements
- Basic familiarity with Java
- Some background in programming
Table of Contents
Lecture 1: Union-Find. We illustrate our basic approach to developing and analyzing algorithms by considering the dynamic connectivity problem. We introduce the union-find data type and consider several implementations (quick find, quick union, weighted quick union, and weighted quick union with path compression). Finally, we apply the union-find data type to the percolation problem from physical chemistry.
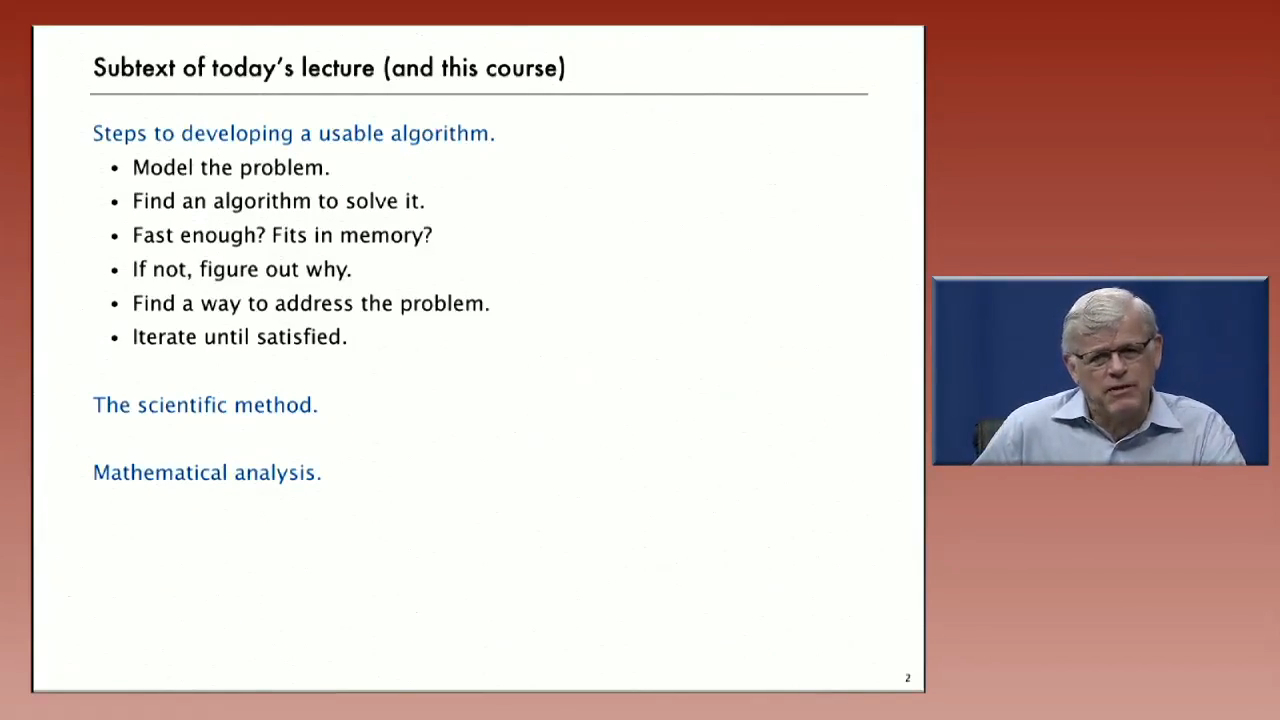
Lecture 2: Analysis of Algorithms. The basis of our approach for analyzing the performance of algorithms is the scientific method. We begin by performing computational experiments to measure the running times of our programs. We use these measurements to develop hypotheses about performance. Next, we create mathematical models to explain their behavior. Finally, we consider analyzing the memory usage of our Java programs.
Lecture 3: Stacks and Queues. We consider two fundamental data types for storing collections of objects: the stack and the queue. We implement each using either a singly-linked list or a resizing array. We introduce two advanced Java featuresgenerics and iteratorsthat simplify client code. Finally, we consider various applications of stacks and queues ranging from parsing arithmetic expressions to simulating queueing systems.
Lecture 4: Elementary Sorts. We introduce the sorting problem and Java's Comparable interface. We study two elementary sorting methods (selection sort andinsertion sort) and a variation of one of them (shellsort). We also consider two algorithms for uniformly shuffling an array. We conclude with an application of sorting to computing the convex hull via the Graham scan algorithm.
Lecture 5: Mergesort. We study the mergesort algorithm and show that it guarantees to sort any array of N items with at most NlgN compares. We also consider a nonrecursive, bottom-up version. We prove that any compare-based sorting algorithm must make at least NlgN compares in the worst case. We discuss using different orderings for the objects that we are sorting and the related concept of stability.
Lecture 6: Quicksort. We introduce and implement the randomized quicksort algorithm and analyze its performance. We also consider randomized quickselect, a quicksort variant which finds the kth smallest item in linear time. Finally, consider 3-way quicksort, a variant of quicksort that works especially well in the presence of duplicate keys.
Lecture 7: Priority Queues. We introduce the priority queue data type and an efficient implementation using the binary heap data structure. This implementation also leads to an efficient sorting algorithm known as heapsort. We conclude with an applications of priority queues where we simulate the motion of N particles subject to the laws of elastic collision.
Lecture 8: Elementary Symbol Tables. We define an API for symbol tables (also known as associative arrays) and describe two elementary implementations using a sorted array (binary search) and an unordered list (sequential search). When the keys are Comparable, we define an extended API that includes the additional methods min, max floor, ceiling, rank, and select. To develop an efficient implementation of this API, we study the binary search tree data structure and analyze its performance
Lecture 9: Balanced Search Trees. In this lecture, our goal is to develop a symbol table with guaranteed logarithmic performance for search and insert (and many other operations). We begin with 2-3 trees, which are easy to analyze but hard to implement. Next, we consider red-black binary search trees, which we view as a novel way to implement 2-3 trees as binary search trees. Finally, we introduce B-trees, a generalization of 2-3 trees that are widely used to implement file systems.
Lecture 10: Geometric Applications of BSTs. We start with 1d and 2d range searching, where the goal is to find all points in a given 1d or 2d interval. To accomplish this, we consider kd-trees, a natural generalization of BSTs when the keys are points in the plane (or higher dimensions). We also consider intersection problems, where the goal is to find all intersections among a set of line segments or rectangles.
Lecture 11: Hash Tables. We begin by describing the desirable properties of hash functions and how to implement them in Java, including a fundamental tenet known as the uniform hashing assumption that underlies the potential success of a hashing application. Then, we consider two strategies for implementing hash tablesseparate chaining and linear probing. Both strategies yield constant-time performance for search and insert under the uniform hashing assumption. We conclude with applications of symbol tables including sets, dictionary clients, indexing clients, and sparse vectors.
Lecture 12: Undirected Graphs. We define an undirected graph API and consider the adjacency-matrix and adjacency-lists representations. We introduce two classic algorithms for searching a graphdepth-first search and breadth-first search. We also consider the problem of computing connected components and conclude with related problems and applications.
Lecture 13: Directed Graphs. In this lecture we study directed graphs. We begin with depth-first search and breadth-first search in digraphs and describe applications ranging from garbage collection to web crawling. Next, we introduce a depth-first search based algorithm for computing the topological order of an acyclic digraph. Finally, we implement the Kosaraju-Sharir algorithm for computing the strong components of a digraph.
Lecture 14: Minimum Spanning Trees. In this lecture we study the minimum spanning tree problem. We begin by considering a generic greedy algorithm for the problem. Next, we consider and implement two classic algorithms for the problemKruskal's algorithm and Prim's algorithm. We conclude with some applications and open problems.
Lecture 15: Shortest Paths. In this lecture we study shortest-paths problems. We begin by analyzing some basic properties of shortest paths and a generic algorithm for the problem. We introduce and analyze Dijkstra's algorithm for shortest-paths problems with nonnegative weights. Next, we consider an even faster algorithm for DAGs, which works even if the weights are negative. We conclude with the Bellman-Ford-Moore algorithm for edge-weighted digraphs with no negative cycles. We also consider applications ranging from content-aware fill to arbitrage.
Lecture 16: Maximum Flow and Minimum Cut. In this lecture we introduce the maximum flow and minimum cut problems. We begin with the Ford-Fulkerson algorithm. To analyze its correctness, we establish the maxflow-mincut theorem. Next, we consider an efficient implementation of the Ford-Fulkerson algorithm, using the shortest augmenting path rule. Finally, we consider applications, including bipartite matching and baseball elimination.
Lecture 17: Radix Sorts. In this lecture we consider specialized sorting algorithms for strings and related objects.
We begin with a subroutine to sort integers in a small range. We then consider two classic radix sorting algorithmsLSD and MSD radix sorts. Next, we consider an especially efficient variant, which is a hybrid of MSD radix sort and quicksort known as 3-way radix quicksort. We conclude with suffix sorting and related applications.
Lecture 18: Tries. In this lecture we consider specialized algorithms for symbol tables with string keys. Our goal is a data structure that is as fast as hashing and even more flexible than binary search trees. We begin with multiway tries; next we consider ternary search tries. Finally, we consider character-based operations, including prefix match and longest prefix, and related applications.
Lecture 19: Substring Search. In this lecture we consider algorithms for searching for a substring in a piece of text. We begin with a brute-force algorithm, whose running time is quadratic in the worst case. Next, we consider the ingenious Knuth-Morris-Pratt algorithm whose running time is guaranteed to be linear in the worst case. Then, we introduce the Boyer-Moore algorithm, whose running time is sublinear on typical inputs. Finally, we consider the Rabin-Karp fingerprint algorithm, which uses hashing in a clever way to solve the substring search and related problems.
Lecture 20: Regular Expressions. A regular expression is a method for specifying a set of strings. Our topic for this lecture is the famous grep algorithm that determines whether a given text contains any substring from the set. We examine an efficient implementation that makes use of our digraph reachability implementation from Lectures 1 and 2.
Lecture 21: Data Compression. We study and implement several classic data compression schemes, including run-length coding, Huffman compression, and LZW compression. We develop efficient implementations from first principles using a Java library for manipulating binary data that we developed for this purpose, based on priority queue and symbol table implementations from earlier lectures.
Lecture 22: Reductions. In this lecture our goal is to develop ways to classify problems according to their computational requirements. We introduce the concept of reduction as a technique for studying the relationship among problems. People use reductions to design algorithms, establish lower bounds, and classify problems in terms of their computational requirements.
Lecture 23: Linear Programming. The quintessential problem-solving model is known as linear programming, and the simplex method for solving it is one of the most widely used algorithms. In this lecture, we give an overview of this central topic in operations research and describe its relationship to algorithms that we have considered.
Lecture 24: Intractability. Is there a universal problem-solving model to which all problems that we would like to solve reduce and for which we know an efficient algorithm? You may be surprised to learn that we do not know the answer to this question. In this lecture we introduce the complexity classes P, NP, and NP-complete; pose the famous P = NP question; and consider implications in the context of algorithms that we have treated in this course.
Extras
Companion Site
You can find errata, programming assignments and other supplementary resources at the Instructors' Web site
Products related to these video lectures include:
Algorithms, Fourth Edition: The fourth edition of Robert Sedgewick and Kevin Wayne's Algorithms is the leading textbook on algorithms today and is widely used in colleges and universities worldwide.
Algorithms, Deluxe Edition: Book and 24-part Lecture Series: This version of Algorithms, Fourth Edition, includes access to the Algorithms Video Lectures.
Introduction to Analysis of Algorithms: Provides basic information on methods and models for mathematically analyzing algorithms that will appeal to practitioners, researchers, and students alike.