Software System Decomposition
- Avoid Functional Decomposition
- Volatility-Based Decomposition
- Identifying Volatility
Discover why the common ways of decomposition are flawed to the core and learn powerful and helpful techniques to leverage when designing a software system.
This chapter is from the book
This chapter is from the book
This chapter is from the book
Software architecture is the high-level design and structure of the software system. While designing the system is quick and inexpensive compared with building the system, it is critical to get the architecture right. Once the system is built, if the architecture is defective, wrong, or just inadequate for your needs, it is extremely expensive to maintain or extend the system.
The essence of the architecture of any system is the breakdown of the concept of the system as a whole into its comprising components, be it a car, a house, a laptop, or a software system. A good architecture also prescribes how these components interact at run-time. The act of identifying the constituent components of a system is called system decomposition.
The correct decomposition is critical. A wrong decomposition means wrong architecture, which in turn inflicts a horrendous pain in the future, often leading to a complete rewrite of the system.
In years past, these building blocks were C++ objects and later COM, Java, or .NET components. In a modern system and in this book, services (as in service-orientation) are the most granular unit of the architecture. However, the technology used to implement the components and their details (such as interfaces, operations, and class hierarchies) are detailed design aspects, not system decomposition. In fact, such details can change without ever affecting the decomposition and therefore the architecture.
Unfortunately, the majority, if not the vast majority, of all software systems are not designed correctly and arguably are designed in the worst possible way. The design flaws are a direct result of the incorrect decomposition of the systems. This chapter therefore starts by explaining why the common ways of decomposition are flawed to the core and then discusses the rationale behind The Method’s decomposition approach. You will also see some powerful and helpful techniques to leverage when designing the system.
Avoid Functional Decomposition
Functional decomposition decomposes a system into its building blocks based on the functionality of the system. For example, if the system needs to perform a set of operations, such as invoicing, billing, and shipping, you end up with the Invoicing service, the Billing service, and the Shipping service.
Problems with Functional Decomposition
The problems with functional decomposition are many and acute. At the very least, functional decomposition couples services to the requirements because the services are a reflection of the requirements. Any change in the required functionality imposes a change on the functional services. Such changes are inevitable over time and impose a painful future change to your system by requiring a new decomposition after the fact to reflect the new requirements. In addition to costly changes to the system, functional decomposition precludes reuse and leads to overly complex systems and clients.
Precluding Reuse
Consider a simple functionally decomposed system that uses three services A, B, and C, which are called in the order of A then B then C. Because functional decomposition is also decomposition based on time (call A and then call B), it effectively precludes individual reuse of services. Suppose another system also needs a B service (such as Billing). Built into the fabric of B is the notion that it was called after an A and before a C service (such as first Invoicing, and only then Billing against an invoice, and finally Shipping). Any attempt to lift the B service from the first system and drop it in the second system will fail because, in the second system, no one is doing A before it and C after it. When you lift the B service, the A and the C services are hanging off it. B is not an independent reusable service at all—A, B, and C are a clique of tightly coupled services.
Too Many or Too Big
One way of performing functional decomposition is to have as many services as there are variations of the functionalities. This decomposition leads to an explosion of services, since a decently sized system may have hundreds of functionalities. Not only do you have too many services, but these services often duplicate a lot of the common functionality, each customized to their case. The explosion of services inflicts a disproportional cost in integration and testing and increases overall complexity.
Another functional decomposition approach is to lump all possible ways of performing the operations into mega services. This leads to bloating in the size of the services, making them overly complex and impossible to maintain. Such god monoliths become ugly dumping grounds for all related variations of the original functionality, with intricate relationships inside and between the services.
Functional decomposition, therefore, tends to make services either too big and too few or too small and too many. You often see both afflictions side by side in the same system.
Clients Bloat and Coupling
Functional decomposition often leads to flattening of the system hierarchy. Since each service or building block is devoted to a specific functionality, someone must combine these discrete functionalities into a required behavior. That someone is often the client. When the client is the one orchestrating the services, the system becomes a flat two-tier system: clients and services, and any notion of additional layering is gone. Suppose your system needs to perform three operations (or functionalities): A, B and C, in that order. As illustrated in Figure 2-1, the client must stitch the services together.
){kind=link}
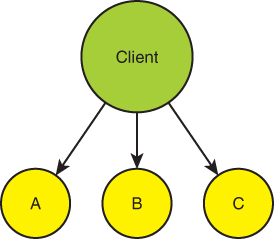
FIGURE 2-1 Bloated client orchestrating functionality
By bloating the client with the orchestration logic, you pollute the client code with the business logic of the system. The client is no longer just about invoking operations on the system or presenting information to users. The client is now intimately aware of all internal services, how to call them, how to handle their errors, how to compensate for the failure of B after the success of A, and so on. Calling the services is almost always synchronous because the client proceeds along the expected sequence of A then B then C, and it is difficult otherwise to ensure the order of the calls while remaining responsive to the outside world. Furthermore, the client is now coupled to the required functionality. Any change in the operations, such as calling B' instead of B, forces the client to reflect that change. The hallmark of a bad design is when any change to the system affects the client. Ideally, the client and services should be able to evolve independently. Decades ago, software engineers discovered that it was a bad idea to include business logic with the client. Yet, when designed as in Figure 2-1, you are forced to pollute the client with the business logic of sequencing, ordering, error compensation, and duration of the calls. Ultimately, the client is no longer the client—it has become the system.
What if there are multiple clients (e.g., rich clients, web pages, mobile devices), each trying to invoke the same sequence of functional services? You are destined to duplicate that logic across the clients, making maintenance of all those clients wasteful and expensive. As the functionality changes, you now are forced to keep up with that change across multiple clients, since all of them will be affected. Often, once that is the case, developers try to avoid any changes to the functionality of the services because of the cascading effect it will have on the clients. With the multiplicity of clients, each with its own version of the sequencing tailored to its needs, it becomes even more challenging to change or interchange services, thus precluding reuse of the same behavior across the clients. Effectively, you end up maintaining multiple complex systems, trying to keep them all in sync. Ultimately, this leads to both stifling of innovation and increased time to market when the changes are forced through development and production.
As an example of the problems with functional decomposition discussed thus far, consider Figure 2-2. It is the visualization of cyclomatic complexity analysis of a system I reviewed. The design methodology used was functional decomposition.
)
FIGURE 2-2 Complexity analysis of a functional design
Cyclomatic complexity measures the number of independent paths through the code of a class or service. The more the internals are convoluted and coupled, the higher the cyclomatic complexity score. The tool used to generate Figure 2-2 measured and rated the various classes in the system. In the visualization, the more complex the class is, the larger and darker it is in color. At first glance, you see three very large and very complex classes. How easy would it be to maintain MainForm? Is this just a form, a UI element, a clean conduit from the user to the system, or is it the system? Observe the complexity required to set up MainForm in the size and shade of FormSetup. Not to be outdone, Resources is very complex, since it is very complex to change the resources used in MainForm. Ideally, Resources should have been trivial, comprising simple lists of images and strings. The rest of the system is made up of dozens of small, simple classes, each devoted to a particular functionality. The smaller classes are literally in the shadow of the three massive ones. However, while each of the small classes may be trivial, the sheer number of the smaller classes is a complexity issue all on its own, involving intricate integration across that many classes. The result is both too many components and too big components as well as a bloated client.
Multiple Points of Entry
Another problem with the decomposition of Figure 2-1 is that it requires multiple points of entry to the system. The client (or clients) needs to enter the system in three places: once for the A, then for the B, then for the C service. This means there are multiple places to worry about authentication, authorization, scalability, instance management, transaction propagation, identities, hosting, and so on. When you need to change the way you perform any one of these aspects, you will need to change it in multiple places across services and clients. Over time, these multiple changes make adding new and different clients very expensive.
Services Bloating and Coupling
As an alternative to sequencing the functional services as in Figure 2-1, you can opt for what, on the face of it, appears as a lesser evil by having the functional services call each other, as shown in Figure 2-3.
){kind=link}
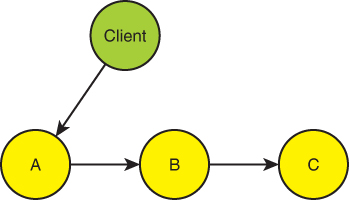
FIGURE 2-3 Chaining functional services
The advantage of doing so is that you get to keep the clients simple and even asynchronous: the clients issue the call to the A service. The A service then calls B, and B calls C.
The problem now is that the functional services are coupled to each other and to the order of the functional calls. For example, you can call the Billing service only after the Invoicing service but before the Shipping service. In the case of Figure 2-3, built into the A service is the knowledge that it needs to call the B service. The B service can be called only after the A service and before the C service. A change in the required ordering of the calls is likely to affect all services up and down the chain because their implementation will have to change to reflect the new required order.
But Figure 2-3 does not reveal the full picture. The B service of Figure 2-3 is drastically different from that of Figure 2-1. The original B service performed only the B functionality. The B service in Figure 2-3 must be aware of the C service, and the B contract must contain the parameters that will be required by the C service to perform its functionality. These details were the responsibility of the client in Figure 2-1. The problem is compounded by the A service, which must now accommodate in its service contract the parameters required for calling the B and the C services for them to perform their respective business functionality. Any change to the B and C functionality is reflected in a change to the implementation of the A service, which is now coupled to them. This kind of bloating and coupling is depicted in Figure 2-4.
)
FIGURE 2-4 Chaining functionality leads to bloated services.
Sadly, even Figure 2-4 does not tell the whole truth. Suppose the A service performed the A functionality successfully and then proceeded to calling the B service to perform the B functionality. The B service, however, encountered an error and failed to execute properly. If A called B synchronously, then A must be intimately aware of the internal logic and state of B in order to recover its error. This means the B functionality must also reside in the A service. If A called B asynchronously, then the B service must now somehow reach back to the A service and undo the A functionality or contain the rollback of A within itself. In other words, the A functionality also resides in the B service. This creates tight coupling between the B service and the A service and bloats the B service with the need to compensate for the success of the A service. This situation is shown in Figure 2-5.
)
FIGURE 2-5 Additional bloating and coupling due to compensation
The issue is compounded in the C service. What if both the A and B functionalities succeeded and completed, but the C service failed to perform its business function? The C service must reach back to both the B and the A services to undo their operations. This creates far more bloating in the C service and couples it to the A and B services. Given the coupling and bloating in Figure 2-5, what will it take to replace the B service with a B' service that performs the functionality differently than B? What will be the adverse effects on the A and C services? Again, what degree of reuse exists in Figure 2-5 when the functionality in the services is asked for in other contexts, such as calling the B service after the D service and before the E service? Are A, B, and C three distinct services or just one fused mess?
Reflecting on Functional Decomposition
Functional decomposition holds an almost irresistible allure. It looks like a simple and clear way of designing the system, requiring you to simply list the required functionalities and then create a component in your architecture for each. Functional decomposition (and its kin, the domain decomposition discussed later) is how most systems are designed. Most people choose functional decomposition naturally, and it is likely what your computer science professor showed you in school. The prevalence of functional decomposition in poorly designed systems makes a near-perfect indicator of something to avoid. At all costs, you must resist the temptations of functional decomposition.
Nature of the Universe (TANSTAAFL)
You can prove that functional decomposition is precluded from ever working without using a single software engineering argument. The proof has to do with the very nature of the universe, specifically, the first law of thermodynamics. Stripping away the math, the first law of thermodynamics simply states that you cannot add value without sweating. A colloquial way of saying the same is: “There ain’t no such thing as a free lunch.”
Design, by its very nature, is a high-added-value activity. You are reading this book instead of yet another programming book because you value design, or put differently, you think design adds value, or even a lot of value.
The problem with functional decomposition is that it endeavors to cheat the first law of thermodynamics. The outcome of a functional decomposition, namely, system design, should be a high-added-value activity. However, functional decomposition is easy and straightforward: given a set of requirements that call for performing the A, B, and C functionalities, you decompose into the A, B, and C services. “No sweat!” you say. “Functional decomposition is so easy that a tool could do it.” However, precisely because it is a fast, easy, mechanistic, and straightforward design, it also manifests a contradiction to the first law of thermodynamics. Since you cannot add value without effort, the very attributes that make functional decomposition so appealing are those that preclude functional decomposition from adding value.
The Anti-Design Effort
It will be an uphill struggle to convince colleagues and managers to do anything other than functional decomposition. “We have always done it that way,” they will say. There are two ways to counter that argument. The first is replying, “And how many times have we met the deadline or the budget to which we committed? What were our quality and complexity like? How easy was it to maintain the system?”
The second is to perform an anti-design effort. Inform the team that you are conducting a design contest for the next-generation system. Split the team into halves, each in a separate conference room. Ask the first half to produce the best design for the system. Ask the second half to produce the worst possible design: a design that will maximize your inability to extend and maintain the system, a design that will disallow reuse, and so on. Let them work on it for one afternoon and then bring them together. When you compare the results, you will usually see they have produced the same design. The labels on the components may differ, but the essence of the design will be the same. Only now confess that they were not working on the same problem and discuss the implications. Perhaps a different approach is called for this time.
Example: Functional House
The fact you should never design using functional decomposition is a universal observation that has nothing to do with software systems. Consider building a house functionally, as if it were a software system. You start by listing all the required functionalities of the house, such as cooking, playing, resting, sleeping, and so on. You then create an actual component in the architecture for each functionality, as shown in Figure 2-6.
)
FIGURE 2-6 Functional decomposition of a house
While Figure 2-6 is already preposterous, the true insanity becomes evident only when it is time to build this house. You start with a clean plot of land and build cooking. Just cooking. You take a microwave oven out of its box and put it aside. Pour a small concrete pad, build a wood frame on the pad, cover it with countertop, and place the microwave on it. Build a small pantry for the microwave and hammer a tiny roof over it, connect just the microwave to the power grid. “We have cooking!” you announce to the boss and customers.
But is cooking really done? Can cooking ever be done this way? Where are you serving the meal, storing the leftovers, or disposing of trash? What about cooking over the gas stove? What will it take to duplicate this feat for cooking over the stove? What degree of reuse can you have between the two separate ways of expressing the functionality of cooking? Can you extend any one of them easily? What about cooking with a microwave somewhere else? What does it take to relocate the microwave? All of this mess is not even the beginning because it all depends on the type of cooking you perform. You need to build separate cooking functionality, perhaps, if cooking involves multiple appliances and differs by context—for example, if you are cooking breakfast, lunch, dinner, dessert, or snacks. You end up with either explosion of minute cooking services, each dedicated to a specific scenario that must be known in advance, or you end up with massive cooking service that has it all. Will you ever build a house like that? If not, why design and build a software system that way?
Avoid Domain Decomposition
The house design in Figure 2-6 is obviously absurd. In your house, you likely do the cooking in the kitchen, so an alternative decomposition of the house is shown in Figure 2-7. This form of decomposition is called domain decomposition: decomposing a system into building blocks based on the business domains, such as sales, engineering, accounting, and shipping. Sadly, domain decomposition such as Figure 2-7 shows is even worse than the functional decomposition of Figure 2-6. The reason domain decomposition does not work is that it is still functional decomposition in disguise: Kitchen is where you do the cooking, Bedroom is where you do the sleeping, Garage is where you do the parking, and so on.
)
FIGURE 2-7 Domain decomposition of a house
In fact, every one of the functional areas of Figure 2-6 can be mapped to domains in Figure 2-7, which presents severe problems. While each bedroom may be unique, you must duplicate the functionality of sleeping in all of them. Further duplication occurs when sleeping in front of the TV in the living room or when entertaining guests in the kitchen (as almost all house parties end up in the kitchen). Each domain often devolves into an ugly grab bag of functionality, increasing the internal complexity of the domain. The increased inner complexity causes you to avoid the pain of cross-domain connectivity, and communication across domains is typically reduced to simple state changes (CRUD-like) rather than actions triggering required behavior execution involving all domains. Composing more complex behaviors across domains is very difficult. Some functionalities are simply impossible in such domain decompositions. For example, in the house in Figure 2-7, where would you perform cooking that cannot take place in the kitchen (e.g., a barbecue)?
Building a Domain House
As with the pure functional approach, the real problems with domain decomposition become evident during construction. Imagine building a house along the decomposition of Figure 2-7. You start with a clean plot of land. You dig a trench for the foundation for the kitchen, pour concrete for the foundation (just for the kitchen), and add bolts in the concrete. You then erect the kitchen walls (all have to be exterior walls); bolt them to the foundation; run electrical wires and plumbing in the walls; connect the kitchen to the water, power, and gas supplies; connect the kitchen to the sewer discharge; add heating and cooling ducts and vents; connect the kitchen to a furnace; add water, power, and gas meters; build a roof over the kitchen; screw drywall on the inside; hang cabinets; coat the outside walls (all walls) with stucco; and paint it. You announce to the customer that the Kitchen is done and that milestone 1.0 is met.
Then you move on to the bedroom. You first bust the stucco off the kitchen walls to expose the bolts connecting the walls to the foundation and unbolt the kitchen from the foundation. You disconnect the kitchen from the power supply, gas supply, water supply, and sewer discharge and then use expensive hydraulic jacks to lift the kitchen. While suspending the kitchen in midair, you shift it to the side so that you can demolish the foundation for the kitchen with jackhammers, hauling the debris away and paying expensive dump fees. Now you can dig a new trench that will contain a continuous foundation for the bedroom and the kitchen. You pour concrete into the trenches to cast the new foundation and add the bolts hopefully at exactly the same spots as before. Next, you very carefully lower the kitchen back on top of the new foundation, making sure all the bolt holes align (this is next to impossible). You erect new walls for the bedroom. You temporarily remove the cabinets from the kitchen walls; remove the drywall to expose the inner electrical wires, pipes, and ducts; and connect the ducts, plumbing, and wires to those of the bedroom. You add drywall in the kitchen and the bedroom, rehang the kitchen cabinets, and add closets in the bedroom. You knock down any remaining stucco from the walls of the kitchen so that you can apply continuous, crack-free stucco on the outside walls. You must convert several of the previous outside walls of the kitchen to internal walls now, with implications on stucco, insulation, paint, and so on. You remove the roof of the kitchen and build a new continuous roof over the bedroom and the kitchen. You announce to the customer that milestone 2.0 is met, and Bedroom 1 is done.
The fact that you had to rebuild the kitchen is not disclosed. The fact that building the kitchen the second time around was much more expensive and riskier than the first time is also undisclosed. What will it take to add another bedroom to this house? How many times will you end up building and demolishing the kitchen? How many times can you actually rebuild the kitchen before it crumbles into a shifting pile of useless debris? Was the kitchen really done when you announced it so? Rework penalties aside, what degree of reuse is there between the various parts of the house? How much more expensive is building a house this way? Why would it make sense to build a software system this way?
Faulty Motivation
The motivation for functional or domain decomposition is that the business or the customer wants its feature as soon as possible. The problem is that you can never deploy a single feature in isolation. There is no business value in Billing independent from Invoicing and Shipping.
The situation is even worse when legacy systems are involved. Rarely do developers get the privilege of a completely new, green-field system. Most likely there is an existing, decaying system that was designed functionally whose inflexibility and maintenance costs justify the new system.
Suppose your business has three functionalities A, B, and C, running in a legacy system. When building a new system to replace the old, you decide to build and, more important, deploy the A functionality first to satisfy the customers and managers who wish to see value early and often. The problem is that the business has no use for just A on its own. The business needs B and C as well. Performing A in the new system and B and C in the old system will not work, because the old system does not know about the new system and cannot execute just B and C. Doing A in both the old system and the new system adds no value and even has negative value due to the repeated work, so users are likely to revolt. The only solution is to somehow reconcile the old and the new systems. The reconciliation typically far eclipses in complexity the challenge of the original underlying business problem, so developers end up solving a far more complex problem. To use the house analogy again, what would it be like to live in a cramped old house while building a new house on the other side of town according to Figure 2-6 or Figure 2-7? Suppose you are building just cooking or the kitchen in the new house while continuing to live in the old house. Every time you are hungry, you have to drive to the new house and come back. You would not accept it with your house, so you should not inflict this kind of abuse on your customers.
Testability and Design
A crucial flaw of both functional and domain decomposition has to do with testing. With such designs, the level of coupling and complexity is so high that the only kind of testing developers can do is unit testing. However, that does not make unit testing important, and it is merely another example of the streetlight effect1 (i.e., searching for something where it is easiest to look).
1. https://en.wikipedia.org/wiki/Streetlight_effect
The sad reality is that unit testing is borderline useless. While unit testing is an essential part of testing, it cannot really test a system. Consider a jumbo jet that has numerous internal components (pumps, actuators, servos, gears, turbines, etc.). Now suppose all components have independently passed unit testing perfectly, but that is the only testing that took place before the components were assembled into an aircraft. Would you dare board that airplane? The reason unit testing is so marginal is that in any complex system, the defects are not going to be in any of the units but rather are the result of the interactions between the units. This is why you instinctively know that, while each component in the jumbo jet example works, the aggregate could be horribly wrong. Worse, even if the complex system is at a perfect state of impeccable quality, changing a single, unit-tested component could break some other unit(s) relying on an old behavior. You must repeat testing of all units when changing a single unit. Even then it would be meaningless because the change to one of the components could affect some interaction between other components or a subsystem, which no unit testing could discover. The only way to verify change is full regression testing of the system, its subsystems, its components and interactions, and finally its units. If, as a result of your change, other units need to change, the effect on regression testing is nonlinear. The inefficacy of unit testing is not a new observation and has been demonstrated across thousands of well-measured systems.
In theory, you could perform regression testing even on a functionally decomposed system. In practice, the complexity of that task would set the bar very high. The sheer number of the functional components would make testing all the interactions impractical. The very large services would be internally so complex that no one could effectively devise a comprehensive strategy that tests all code paths through such services. With functional decomposition, most developers give up and perform just simple unit testing. Therefore, by precluding regression testing, functional decomposition makes the entire system untestable, and untestable systems are always rife with defects.
Example: Functional Trading System
Instead of a house, consider the following simplified requirements for a stock trading system for a financial company:
The system should enable in-house traders to:
– Buy and sell stocks
– Schedule trades
– Issue reports
– Analyze the trades
The users of the system utilize a browser to connect to the system and manage connected sessions, completing a form and submitting the request.
After a trade, report, or analysis request, the system sends an email to the users confirming their request or containing the results.
The data should be stored in a local database.
A straightforward functional decomposition would yield the design of Figure 2-8.
){kind=link}
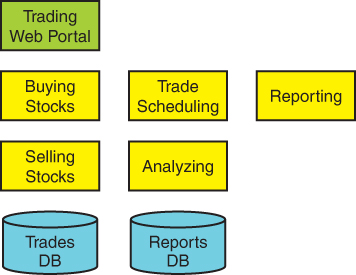
FIGURE 2-8 Functional trading system
Each of the functional requirements is expressed in a respective component of the architecture. Figure 2-8 represents a common design to which many novice software developers would gravitate without hesitation.
Problems with the Functional Trading System
The flaws of such a system design are many. It is very likely the client in the present system is the one that orchestrates Buying Stocks, Selling Stocks, and Trade Scheduling; issues a report with Reporting; and so on. Suppose the user wants to fund purchasing of a certain number of stocks by selling other stocks. This means two orders: first sell and then buy. But what should the client do if by the time these two transactions take place, the price of the stocks sold has dropped or the price of the bought stocks has risen so that the selling cannot fulfill the buying? Should the client buy just as many as possible? Should it perhaps sell more stocks than intended? Should it dip into the cash account behind the trading account to supplement the order? Should it abort the whole thing? Should it ask for user assistance? The exact resolution is immaterial for this discussion. Whatever the resolution, it requires business logic, which now resides in the client.
What will it take to change the client from a web portal to a mobile device? Would that not mean duplicating the business logic into the mobile device? It is likely that little of the business logic and the effort invested in developing it for the web client can be salvaged and reused in the mobile client because it is embedded in the web portal. Over time, the developers will end up maintaining several versions of the business logic in multiple clients.
Per the requirements, Buying Stocks, Selling Stocks, Trade Scheduling, Reporting, and Analyzing all respond to the user with an email listing their activities. What if the users prefer to receive a text message (or a paper letter) instead of an email? You will have to change the implementation of Buying Stocks, Selling Stocks, Trade Scheduling, Reporting, and Analyzing activities from an email to a text message.
Per the design decision, the data is stored in a database, and Buying Stocks, Selling Stocks, Trade Scheduling, Reporting, and Analyzing all access that database. Now suppose you decide to move the data storage from the local database to a cloud-based solution. At the very least, this will force you to change the data-access code in Buying Stocks, Selling Stocks, Trade Scheduling, Reporting, and Analyzing to go from a local database to a cloud offering. The way you structure, access, and consume the data has to change across all components.
What if the client wishes to interact with the system asynchronously, issuing a few trades and collecting the results later? You built the components with the notion of a connected, synchronous client that orchestrates the components. You will likely need to rewrite Buying Stocks, Selling Stocks, Trade Scheduling, Reporting, and Analyzing activities to orchestrate each other, along the lines of Figure 2-5.
Often, financial portfolios are comprised of multiple financial instruments besides stocks, such as currencies, bonds, commodities, and even options and futures on those instruments. What if the users of the system wish to start trading currencies or commodities instead of stocks? What if the users demand a single application, rather than several applications, to manage all of their portfolios? Buying Stocks, Selling Stocks, and Trade Scheduling are all about stocks and cannot handle currencies or bonds, requiring you to add additional components (like Figure 2-6). Similarly, Reporting and Analyzing need a major rewrite to accommodate reporting and analysis of trades other than stocks. The client needs a rewrite to accommodate the new trade items.
Even without branching to commodities, what if you must localize the application to foreign markets? At the very least, the client will need a serious makeover to accommodate language localization, but the real effect is going to be the system components again. Foreign markets are going to have different trading rules, regulations, and compliance requirements, drastically affecting what the system is allowed to do and how it is to go about trading. This will mean much rework to Buying Stocks, Selling Stocks, Trade Scheduling, Reporting, and Analyzing whenever entering a new locale. You are going to end up with either bloated god services that can trade in any market or a version of the system for each deployment locale.
Finally, all components presently connect to some stock ticker feed that provides them with the latest stock values. What is required to switch to a new feed provider or to incorporate multiple feeds? At the very least, Buying Stocks, Selling Stocks, Trade Scheduling, Reporting, and Analyzing will require work to move to a new feed, connect to it, handle its errors, pay for its service, and so on. There are also no guarantees that the new feed uses the same data format as the old one. All components require some conversion and transformation work as well.