- 3.1 Classification Tasks
- 3.2 A Simple Classification Dataset
- 3.3 Training and Testing: Don't Teach to the Test
- 3.4 Evaluation: Grading the Exam
- 3.5 Simple Classifier #1: Nearest Neighbors, Long Distance Relationships, and Assumptions
- 3.6 Simple Classifier #2: Naive Bayes, Probability, and Broken Promises
- 3.7 Simplistic Evaluation of Classifiers
- 3.8 EOC
This chapter is from the book
This chapter is from the book
This chapter is from the book
3.5 Simple Classifier #1: Nearest Neighbors, Long Distance Relationships, and Assumptions
One of the simpler ideas for making predictions from a labeled dataset is:
Find a way to describe the similarity of two different examples.
When you need to make a prediction on a new, unknown example, simply take the value from the most similar known example.
This process is the nearest-neighbors algorithm in a nutshell. I have three friends Mark, Barb, Ethan for whom I know their favorite snacks. A new friend, Andy, is most like Mark. Mark’s favorite snack is Cheetos. I predict that Andy’s favorite snack is the same as Mark’s: Cheetos.
There are many ways we can modify this basic template. We may consider more than just the single most similar example:
Describe similarity between pairs of examples.
Pick several of the most-similar examples.
Combine those picks to get a single answer.
3.5.1 Defining Similarity
We have complete control over what similar means. We could define it by calculating a distance between pairs of examples: similarity = distance(example_one, example_two). Then, our idea of similarity becomes encoded in the way we calculate the distance. Similar things are close—a small distance apart. Dissimilar things are far away—a large distance apart.
Let’s look at three ways of calculating the similarity of a pair of examples. The first, Euclidean distance, harkens back to high-school geometry or trig. We treat the two examples as points in space. Together, the two points define a line. We let that line be the hypotenuse of a right triangle and, armed with the Pythagorean theorem, use the other two sides of the triangle to calculate a distance (Figure 3.4). You might recall that 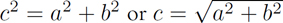 . Or, you might just recall it as painful. Don’t worry, we don’t have to do the calculation. scikit-learn can be told, “Do that thing for me.” By now, you might be concerned that my next example can only get worse. Well, frankly, it could. The Minkowski distance would lead us down a path to Einstein and his theory of relativity . . . but we’re going to avoid that black (rabbit) hole.
. Or, you might just recall it as painful. Don’t worry, we don’t have to do the calculation. scikit-learn can be told, “Do that thing for me.” By now, you might be concerned that my next example can only get worse. Well, frankly, it could. The Minkowski distance would lead us down a path to Einstein and his theory of relativity . . . but we’re going to avoid that black (rabbit) hole.
){kind=link}
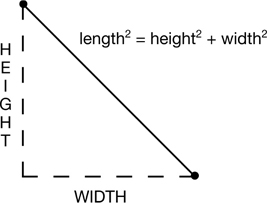
FIGURE 3.4 Distances from components.
Instead, another option for calculating similarity makes sense when we have examples that consist of simple Yes, No or True, False features. With Boolean data, I can compare two examples very nicely by counting up the number of features that are different. This simple idea is clever enough that it has a name: the Hamming distance. You might recognize this as a close cousin—maybe even a sibling or evil twin—of accuracy. Accuracy is the percent correct—the percent of answers the same as the target—which is 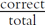 . Hamming distance is the number of differences. The practical implication is that when two sets of answers agree completely, we want the accuracy to be high: 100%. When two sets of features are identical, we want the similarity distance between them to be low: 0.
. Hamming distance is the number of differences. The practical implication is that when two sets of answers agree completely, we want the accuracy to be high: 100%. When two sets of features are identical, we want the similarity distance between them to be low: 0.
You might have noticed that these notions of similarity have names—Euclid(-ean), Minkowski, Hamming Distance—that all fit the template of FamousMathDude Distance. Aside from the math dude part, the reason they share the term distance is because they obey the mathematical rules for what constitutes a distance. They are also called metrics by the mathematical wizards-that-be—as in distance metric or, informally, a distance measure. These mathematical terms will sometimes slip through in conversation and documentation. sklearn’s list of possible distance calculators is in the documentation for neighbors.DistanceMetric: there are about twenty metrics defined there.
3.5.2 The k in k-NN
Choices certainly make our lives complicated. After going to the trouble of choosing how to measure our local neighborhood, we have to decide how to combine the different opinions in the neighborhood. We can think about that as determining who gets to vote and how we will combine those votes.
Instead of considering only the nearest neighbor, we might consider some small number of nearby neighbors. Conceptually, expanding our neighborhood gives us more perspectives. From a technical viewpoint, an expanded neighborhood protects us from noise in the data (we’ll come back to this in far more detail later). Common numbers of neighbors are 1, 3, 10, or 20. Incidentally, a common name for this technique, and the abbreviation we’ll use in this book, is k-NN for “k-Nearest Neighbors”. If we’re talking about k-NN for classification and need to clarify that, I’ll tack a C on there: k-NN-C.
3.5.3 Answer Combination
We have one last loose end to tie down. We must decide how we combine the known values (votes) from the close, or similar, neighbors. If we have an animal classification problem, four of our nearest neighbors might vote for cat, cat, dog, and zebra. How do we respond for our test example? It seems like taking the most frequent response, cat, would be a decent method.
In a very cool twist, we can use the exact same neighbor-based technique in regression problems where we try to predict a numerical value. The only thing we have to change is how we combine our neighbors’ targets. If three of our nearest neighbors gave us numerical values of 3.1, 2.2, and 7.1, how do we combine them? We could use any statistic we wanted, but the mean (average) and the median (middle) are two common and useful choices. We’ll come back to k-NN for regression in the next chapter.
3.5.4 k-NN, Parameters, and Nonparametric Methods
Since k-NN is the first model we’re discussing, it is a bit difficult to compare it to other methods. We’ll save some of those comparisons for later. There’s one major difference we can dive into right now. I hope that grabbed your attention.
Recall the analogy of a learning model as a machine with knobs and levers on the side. Unlike many other models, k-NN outputs—the predictions—can’t be computed from an input example and the values of a small, fixed set of adjustable knobs. We need all of the training data to figure out our output value. Really? Imagine that we throw out just one of our training examples. That example might be the nearest neighbor of a new test example. Surely, missing that training example will affect our output. There are other machine learning methods that have a similar requirement. Still others need some, but not all, of the training data when it comes to test time.
Now, you might argue that for a fixed amount of training data there could be a fixed number of knobs: say, 100 examples and 1 knob per example, giving 100 knobs. Fair enough. But then I add one example—and, poof, you now need 101 knobs, and that’s a different machine. In this sense, the number of knobs on the k-NN machine depends on the number of examples in the training data. There is a better way to describe this dependency. Our factory machine had a side tray where we could feed additional information. We can treat the training data as this additional information. Whatever we choose, if we need either (1) a growing number of knobs or (2) the side-input tray, we say the type of machine is nonparametric. k-NN is a nonparametric learning method.
Nonparametric learning methods can have parameters. (Thank you for nothing, formal definitions.) What’s going on here? When we call a method nonparametric, it means that with this method, the relationship between features and targets cannot be captured solely using a fixed number of parameters. For statisticians, this concept is related to the idea of parametric versus nonparametric statistics: nonparametric statistics assume less about a basket of data. However, recall that we are not making any assumptions about the way our black-box factory machine relates to reality. Parametric models (1) make an assumption about the form of the model and then (2) pick a specific model by setting the parameters. This corresponds to the two questions: what knobs are on the machine, and what values are they set to? We don’t make assumptions like that with k-NN. However, k-NN does make and rely on assumptions. The most important assumption is that our similarity calculation is related to the actual example similarity that we want to capture.
3.5.5 Building a k-NN Classification Model
k-NN is our first example of a model. Remember, a supervised model is anything that captures the relationship between our features and our target. We need to discuss a few concepts that swirl around the idea of a model, so let’s provide a bit of context first. Let’s write down a small process we want to walk through:
We want to use 3-NN—three nearest neighbors—as our model.
We want that model to capture the relationship between the iris training features and the iris training target.
We want to use that model to predict—on previously unseen test examples—the iris target species.
Finally, we want to evaluate the quality of those predictions, using accuracy, by comparing predictions against reality. We didn’t peek at these known answers, but we can use them as an answer key for the test.
There’s a diagram of the flow of information in Figure 3.5.
)
FIGURE 3.5 Workflow of training, testing, and evaluation for 3-NN.
As an aside on sklearn’s terminology, in their documentation an estimator is fit on some data and then used to predict on some data. If we have a training and testing split, we fit the estimator on training data and then use the fit-estimator to predict on the test data. So, let’s
Create a 3-NN model,
Fit that model on the training data,
Use that model to predict on the test data, and
Evaluate those predictions using accuracy.
In [9]:
# default n_neighbors = 5
knn = neighbors.KNeighborsClassifier(n_neighbors=3)
fit = knn.fit(iris_train_ftrs, iris_train_tgt)
preds = fit.predict(iris_test_ftrs)
# evaluate our predictions against the held-back testing targets
print("3NN accuracy:",
metrics.accuracy_score(iris_test_tgt, preds))
3NN accuracy: 1.0
Wow, 100%. We’re doing great! This machine learning stuff seems pretty easy—except when it isn’t. We’ll come back to that shortly. We can abstract away the details of k-NN classification and write a simplified workflow template for building and assessing models in sklearn:
Build the model,
Fit the model using the training data,
Predict using the fit model on the testing data, and
Evaluate the quality of the predictions.
We can connect this workflow back to our conception of a model as a machine. The equivalent steps are:
Construct the machine, including its knobs,
Adjust the knobs and feed the side-inputs appropriately to capture the training data,
Run new examples through the machine to see what the outputs are, and
Evaluate the quality of the outputs.
Here’s one last, quick note. The 3 in our 3-nearest-neighbors is not something that we adjust by training. It is part of the internal machinery of our learning machine. There is no knob on our machine for turning the 3 to a 5. If we want a 5-NN machine, we have to build a completely different machine. The 3 is not something that is adjusted by the k-NN training process. The 3 is a hyperparameter. Hyperparameters are not trained or manipulated by the learning method they help define. An equivalent scenario is agreeing to the rules of a game and then playing the game under that fixed set of rules. Unless we’re playing Calvinball or acting like Neo in The Matrix—where the flux of the rules is the point—the rules are static for the duration of the game. You can think of hyperparameters as being predetermined and fixed in place before we get a chance to do anything with them while learning. Adjusting them involves conceptually, and literally, working outside the learning box or the factory machine. We’ll discuss this topic more in Chapter 11.