
This chapter is from the book
This chapter is from the book
This chapter is from the book
1.5. Example: Analysis of Quicksort
To illustrate the basic method just sketched, we examine next a particular algorithm of considerable importance, the quicksort sorting method. This method was invented in 1962 by C. A. R. Hoare, whose paper [15] is an early and outstanding example in the analysis of algorithms. The analysis is also covered in great detail in Sedgewick [27] (see also [29]); we give highlights here. It is worthwhile to study this analysis in detail not just because this sorting method is widely used and the analytic results are directly relevant to practice, but also because the analysis itself is illustrative of many things that we will encounter later in the book. In particular, it turns out that the same analysis applies to the study of basic properties of tree structures, which are of broad interest and applicability. More generally, our analysis of quicksort is indicative of how we go about analyzing a broad class of recursive programs.
Program 1.2 is an implementation of quicksort in Java. It is a recursive program that sorts the numbers in an array by partitioning it into two independent (smaller) parts, then sorting those parts. Obviously, the recursion should terminate when empty subarrays are encountered, but our implementation also stops with subarrays of size 1. This detail might seem inconsequential at first blush, but, as we will see, the very nature of recursion ensures that the program will be used for a large number of small files, and substantial performance gains can be achieved with simple improvements of this sort.
The partitioning process puts the element that was in the last position in the array (the partitioning element) into its correct position, with all smaller elements before it and all larger elements after it. The program accomplishes this by maintaining two pointers: one scanning from the left, one from the right. The left pointer is incremented until an element larger than the partitioning element is found; the right pointer is decremented until an element smaller than the partitioning element is found. These two elements are exchanged, and the process continues until the pointers meet, which defines where the partitioning element is put. After partitioning, the program exchanges a[i] with a[hi] to put the partitioning element into position. The call quicksort(a, 0, N-1) will sort the array.
Program 1.2. Quicksort
private void quicksort(int[] a, int lo, int hi)
{
if (hi <= lo) return;
int i = lo-1, j = hi;
int t, v = a[hi];
while (true)
{
while (a[++i] < v) ;
while (v < a[--j]) if (j == lo) break;
if (i >= j) break;
t = a[i]; a[i] = a[j]; a[j] = t;
}
t = a[i]; a[i] = a[hi]; a[hi] = t;
quicksort(a, lo, i-1);
quicksort(a, i+1, hi);
}
There are several ways to implement the general recursive strategy just outlined; the implementation described above is taken from Sedgewick and Wayne [30] (see also [27]). For the purposes of analysis, we will be assuming that the array a contains randomly ordered, distinct numbers, but note that this code works properly for all inputs, including equal numbers. It is also possible to study this program under perhaps more realistic models allowing equal numbers (see [28]), long string keys (see [4]), and many other situations.
Once we have an implementation, the first step in the analysis is to estimate the resource requirements of individual instructions for this program. This depends on characteristics of a particular computer, so we sketch the details. For example, the “inner loop” instruction
while (a[++i] < v) ;
might translate, on a typical computer, to assembly language instructions such as the following:
LOOP INC I,1 # increment i
CMP V,A(I) # compare v with A(i)
BL LOOP # branch if less
To start, we might say that one iteration of this loop might require four time units (one for each memory reference). On modern computers, the precise costs are more complicated to evaluate because of caching, pipelines, and other effects. The other instruction in the inner loop (that decrements j) is similar, but involves an extra test of whether j goes out of bounds. Since this extra test can be removed via sentinels (see [26]), we will ignore the extra complication it presents.
The next step in the analysis is to assign variable names to the frequency of execution of the instructions in the program. Normally there are only a few true variables involved: the frequencies of execution of all the instructions can be expressed in terms of these few. Also, it is desirable to relate the variables to the algorithm itself, not any particular program. For quicksort, three natural quantities are involved:
- A – the number of partitioning stages
- B – the number of exchanges
- C – the number of compares
On a typical computer, the total running time of quicksort might be expressed with a formula, such as
)
The exact values of these coefficients depend on the machine language program produced by the compiler as well as the properties of the machine being used; the values given above are typical. Such expressions are quite useful in comparing different algorithms implemented on the same machine. Indeed, the reason that quicksort is of practical interest even though mergesort is “optimal” is that the cost per compare (the coefficient of C) is likely to be significantly lower for quicksort than for mergesort, which leads to significantly shorter running times in typical practical applications.
Theorem 1.3. (Quicksort analysis).
Quicksort uses, on the average,
- (N – 1)/2 partitioning stages, 2(N + 1) (HN+1 – 3/2) ≈ 2NlnN – 1.846N compares, and (N + 1) (HN+1 – 3) /3 + 1 ≈ .333NlnN – .865N exchanges
to sort an array of N randomly ordered distinct elements.
Proof. The exact answers here are expressed in terms of the harmonic numbers
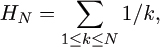
the first of many well-known “special” number sequences that we will encounter in the analysis of algorithms.
As with mergesort, the analysis of quicksort involves defining and solving recurrence relations that mirror directly the recursive nature of the algorithm. But, in this case, the recurrences must be based on probabilistic statements about the inputs. If CN is the average number of compares to sort N elements, we have C0 = C1 = 0 and
)
To get the total average number of compares, we add the number of compares for the first partitioning stage (N +1) to the number of compares used for the subarrays after partitioning. When the partitioning element is the jth largest (which occurs with probability 1/N for each 1 ≤ j ≤ N), the subarrays after partitioning are of size j – 1 and N – j.
Now the analysis has been reduced to a mathematical problem (3) that does not depend on properties of the program or the algorithm. This recurrence relation is somewhat more complicated than (1) because the right-hand side depends directly on the history of all the previous values, not just a few. Still, (3) is not difficult to solve: first change j to N – j + 1 in the second part of the sum to get
)
Then multiply by N and subtract the same formula for N – 1 to eliminate the sum:
- NCN – (N – 1)CN – 1 = 2N + 2CN – 1 for N > 1.
Now rearrange terms to get a simple recurrence
- NCN = (N + 1)CN – 1 + 2N for N > 1.
This can be solved by dividing both sides by N(N + 1):
)
Iterating, we are left with the sum
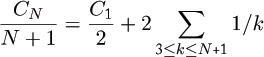
which completes the proof, since C1 = 0.
As implemented earlier, every element is used for partitioning exactly once, so the number of stages is always N; the average number of exchanges can be found from these results by first calculating the average number of exchanges on the first partitioning stage.
The stated approximations follow from the well-known approximation to the harmonic number HN ≈ lnN + .57721 ... . We consider such approximations below and in detail in Chapter 4.
Exercise 1.12 Give the recurrence for the total number of compares used by quicksort on all N! permutations of N elements.
Exercise 1.13 Prove that the subarrays left after partitioning a random permutation are themselves both random permutations. Then prove that this is not the case if, for example, the right pointer is initialized at j:=r+1 for partitioning.
Exercise 1.14 Follow through the steps above to solve the recurrence
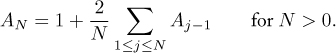
Exercise 1.15 Show that the average number of exchanges used during the first partitioning stage (before the pointers cross) is (N – 2)/6. (Thus, by linearity of the recurrences,
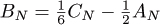 .)
.)
Figure 1.1 shows how the analytic result of Theorem 1.3 compares to empirical results computed by generating random inputs to the program and counting the compares used. The empirical results (100 trials for each value of N shown) are depicted with a gray dot for each experiment and a black dot at the mean for each N. The analytic result is a smooth curve fitting the formula given in Theorem 1.3. As expected, the fit is extremely good.
)
Figure 1.1. Quicksort compare counts: empirical and analytic
Theorem 1.3 and (2) imply, for example, that quicksort should take about 11.667NlnN – .601N steps to sort a random permutation of N elements for the particular machine described previously, and similar formulae for other machines can be derived through an investigation of the properties of the machine as in the discussion preceding (2) and Theorem 1.3. Such formulae can be used to predict (with great accuracy) the running time of quicksort on a particular machine. More important, they can be used to evaluate and compare variations of the algorithm and provide a quantitative testimony to their effectiveness.
Secure in the knowledge that machine dependencies can be handled with suitable attention to detail, we will generally concentrate on analyzing generic algorithm-dependent quantities, such as “compares” and “exchanges,” in this book. Not only does this keep our focus on major techniques of analysis, but it also can extend the applicability of the results. For example, a slightly broader characterization of the sorting problem is to consider the items to be sorted as records containing other information besides the sort key, so that accessing a record might be much more expensive (depending on the size of the record) than doing a compare (depending on the relative size of records and keys). Then we know from Theorem 1.3 that quicksort compares keys about 2NlnN times and moves records about .667NlnN times, and we can compute more precise estimates of costs or compare with other algorithms as appropriate.
Quicksort can be improved in several ways to make it the sorting method of choice in many computing environments. We can even analyze complicated improved versions and derive expressions for the average running time that match closely observed empirical times [29]. Of course, the more intricate and complicated the proposed improvement, the more intricate and complicated the analysis. Some improvements can be handled by extending the argument given previously, but others require more powerful analytic tools.
Small subarrays
The simplest variant of quicksort is based on the observation that it is not very efficient for very small files (for example, a file of size 2 can be sorted with one compare and possibly one exchange), so that a simpler method should be used for smaller subarrays. The following exercises show how the earlier analysis can be extended to study a hybrid algorithm where “insertion sort” (see §7.6) is used for files of size less than M. Then, this analysis can be used to help choose the best value of the parameter M.
Exercise 1.16 How many subarrays of size 2 or less are encountered, on the average, when sorting a random file of size N with quicksort?
Exercise 1.17 If we change the first line in the quicksort implementation above to
if r-l<=M then insertionsort(l,r) else
(see §7.6), then the total number of compares to sort N elements is described by the recurrence
)
Solve this exactly as in the proof of Theorem 1.3.
Exercise 1.18 Ignoring small terms (those significantly less than N) in the answer to the previous exercise, find a function f(M) so that the number of compares is approximately
- 2NlnN + f(M)N.
Plot the function f(M), and find the value of M that minimizes the function.
Exercise 1.19 As M gets larger, the number of compares increases again from the minimum just derived. How large must M get before the number of compares exceeds the original number (at M = 0)?
Median-of-three quicksort
A natural improvement to quicksort is to use sampling: estimate a partitioning element more likely to be near the middle of the file by taking a small sample, then using the median of the sample. For example, if we use just three elements for the sample, then the average number of compares required by this “median-of-three” quicksort is described by the recurrence
)
where 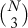 is the binomial coefficient that counts the number of ways to choose 3 out of N items. This is true because the probability that the kth smallest element is the partitioning element is now
is the binomial coefficient that counts the number of ways to choose 3 out of N items. This is true because the probability that the kth smallest element is the partitioning element is now 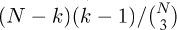 (as opposed to 1/N for regular quicksort). We would like to be able to solve recurrences of this nature to be able to determine how large a sample to use and when to switch to insertion sort. However, such recurrences require more sophisticated techniques than the simple ones used so far. In Chapters 2 and 3, we will see methods for developing precise solutions to such recurrences, which allow us to determine the best values for parameters such as the sample size and the cutoff for small subarrays. Extensive studies along these lines have led to the conclusion that median-of-three quicksort with a cutoff point in the range 10 to 20 achieves close to optimal performance for typical implementations.
(as opposed to 1/N for regular quicksort). We would like to be able to solve recurrences of this nature to be able to determine how large a sample to use and when to switch to insertion sort. However, such recurrences require more sophisticated techniques than the simple ones used so far. In Chapters 2 and 3, we will see methods for developing precise solutions to such recurrences, which allow us to determine the best values for parameters such as the sample size and the cutoff for small subarrays. Extensive studies along these lines have led to the conclusion that median-of-three quicksort with a cutoff point in the range 10 to 20 achieves close to optimal performance for typical implementations.
Radix-exchange sort
Another variant of quicksort involves taking advantage of the fact that the keys may be viewed as binary strings. Rather than comparing against a key from the file for partitioning, we partition the file so that all keys with a leading 0 bit precede all those with a leading 1 bit. Then these subarrays can be independently subdivided in the same way using the second bit, and so forth. This variation is referred to as “radix-exchange sort” or “radix quicksort.” How does this variation compare with the basic algorithm? To answer this question, we first have to note that a different mathematical model is required, since keys composed of random bits are essentially different from random permutations. The “random bitstring” model is perhaps more realistic, as it reflects the actual representation, but the models can be proved to be roughly equivalent. We will discuss this issue in more detail in Chapter 8. Using a similar argument to the one given above, we can show that the average number of bit compares required by this method is described by the recurrence
)
This turns out to be a rather more difficult recurrence to solve than the one given earlier—we will see in Chapter 3 how generating functions can be used to transform the recurrence into an explicit formula for CN, and in Chapters 4 and 8, we will see how to develop an approximate solution.
One limitation to the applicability of this kind of analysis is that all of the preceding recurrence relations depend on the “randomness preservation” property of the algorithm: if the original file is randomly ordered, it can be shown that the subarrays after partitioning are also randomly ordered. The implementor is not so restricted, and many widely used variants of the algorithm do not have this property. Such variants appear to be extremely difficult to analyze. Fortunately (from the point of view of the analyst), empirical studies show that they also perform poorly. Thus, though it has not been analytically quantified, the requirement for randomness preservation seems to produce more elegant and efficient quicksort implementations. More important, the versions that preserve randomness do admit to performance improvements that can be fully quantified mathematically, as described earlier.
Mathematical analysis has played an important role in the development of practical variants of quicksort, and we will see that there is no shortage of other problems to consider where detailed mathematical analysis is an important part of the algorithm design process.