Reinforcement Learning - The Actor-Critic Algorithm
A complete look at the Actor-Critic (A2C) algorithm, used in deep reinforcement learning, which enables a learned reinforcing signal to be more informative for a policy than the rewards available from an environment.
Save 35% off the list price* of the related book or multi-format eBook (EPUB + MOBI + PDF) with discount code ARTICLE.
* See informit.com/terms
This chapter is from the book
This chapter is from the book
This chapter is from the book
In this chapter, we look at Actor-Critic algorithms which elegantly combine the ideas we have seen so far in this book—namely, the policy gradient and a learned value function. In these algorithms, a policy is reinforced with a learned reinforcing signal generated using a learned value function. This contrasts with REINFORCE which uses a high-variance Monte Carlo estimate of the return to reinforce the policy.
All Actor-Critic algorithms have two components which are learned jointly—an actor, which learns a parameterized policy, and a critic which learns a value function to evaluate state-action pairs. The critic provides a reinforcing signal to the actor.
The main motivation behind these algorithms is that a learned reinforcing signal can be more informative for a policy than the rewards available from an environment. For example, it can transform a sparse reward in which the agent only receives +1 upon success into a dense reinforcing signal. Furthermore, learned value functions typically have lower variance than Monte Carlo estimates of the return. This reduces the uncertainty under which a policy learns [11], making the learning process easier. However, training also becomes more complex. Now learning the policy depends on the quality of the value function estimate which is being learned simultaneously. Until the value function is generating reasonable signals for the policy, learning how to select good actions will be challenging.
It is common to learn the advantage function Aπ(s, a) = Qπ(s, a) − Vπ(s) as the reinforcing signals in these methods. The key idea is that it is better to select an action based on how it performs relative to the other actions available in a particular state, instead of using the absolute value of that action as measured by the Q-function. The advantage quantifies how much better or worse an action is than the average available action. Actor-Critic algorithms which learn the advantage function are known as Advantage Actor-Critic (A2C) algorithms.
First, we discuss the actor in Section 6.1. This is brief because it is similar to REINFORCE. Then, in Section 6.2 we introduce the critic and two different methods for estimating the advantage function—n-step returns and Generalized Advantage Estimation [123].
Section 6.3 covers the Actor-Critic algorithm and Section 6.4 contains an example of how it can be implemented. The chapter ends with instructions for training an Actor-Critic agent.
6.1 The Actor
Actors learn parametrized policies πθ using the policy gradient as shown in Equation 6.1. This is very similar to REINFORCE (Chapter 2) except we now use the advantage 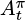 as a reinforcing signal instead of a Monte Carlo estimate of the return Rt(τ ) (Equation 2.1).
as a reinforcing signal instead of a Monte Carlo estimate of the return Rt(τ ) (Equation 2.1).
)
)
Next, we look at how to learn the advantage function.