- 2-1 Manipulating Rightmost Bits
- 2-2 Addition Combined with Logical Operations
- 2-3 Inequalities among Logical and Arithmetic Expressions
- 2-4 Absolute Value Function
- 2-5 Average of Two Integers
- 2-6 Sign Extension
- 2-7 Shift Right Signed from Unsigned
- 2-8 Sign Function
- 2-9 Three-Valued Compare Function
- 2-10 Transfer of Sign Function
- 2-11 Decoding a "Zero Means 2 **n" Field
- 2-12 Comparison Predicates
- 2-13 Overflow Detection
- 2-14 Condition Code Result of Add, Subtract, and Multiply
- 2-15 Rotate Shifts
- 2-16 Double-Length Add/Subtract
- 2-17 Double-Length Shifts
- 2-18 Multibyte Add, Subtract, Absolute Value
- 2-19 Doz, Max, Min
- 2-20 Exchanging Registers
- 2-21 Alternating among Two or More Values
- 2-22 A Boolean Decomposition Formula
- 2-23 Implementing Instructions for All 16 Binary Boolean Operations
This chapter is from the book
This chapter is from the book
This chapter is from the book
2–20 Exchanging Registers
A very old trick is exchanging the contents of two registers without using a third [IBM]:
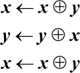
This works well on a two-address machine. The trick also works if ⊕ is replaced by the ≡ logical operation (complement of exclusive or) and can be made to work in various ways with add’s and subtract’s:
)
Unfortunately, each of these has an instruction that is unsuitable for a two-address machine, unless the machine has “reverse subtract.”
This little trick can actually be useful in the application of double buffering, in which two pointers are swapped. The first instruction can be factored out of the loop in which the swap is done (although this negates the advantage of saving a register):
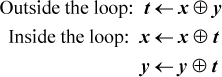
Exchanging Corresponding Fields of Registers
The problem here is to exchange the contents of two registers x and y wherever a mask bit mi = 1, and to leave x and y unaltered wherever mi = 0. By “corresponding” fields, we mean that no shifting is required. The 1-bits of m need not be contiguous. The straightforward method is as follows:
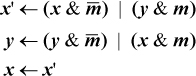
By using “temporaries” for the four and expressions, this can be seen to require seven instructions, assuming that either m or 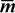 can be loaded with a single instruction and the machine has and not as a single instruction. If the machine is capable of executing the four (independent) and expressions in parallel, the execution time is only three cycles.
can be loaded with a single instruction and the machine has and not as a single instruction. If the machine is capable of executing the four (independent) and expressions in parallel, the execution time is only three cycles.
A method that is probably better (five instructions, but four cycles on a machine with unlimited instruction-level parallelism) is shown in column (a) below. It is suggested by the “three exclusive or” code for exchanging registers.
)
The steps in column (b) do the same exchange as that of column (a), but column (b) is useful if m does not fit in an immediate field, but does, and the machine has the equivalence instruction.
Still another method is shown in column (c) above [GLS1]. It also takes five instructions (again assuming one instruction must be used to load m into a register), but executes in only three cycles on a machine with sufficient instruction-level parallelism.
Exchanging Two Fields of the Same Register
Assume a register x has two fields (of the same length) that are to be swapped, without altering other bits in the register. That is, the object is to swap fields B and D without altering fields A, C, and E, in the computer word illustrated below. The fields are separated by a shift distance k.

Straightforward code would shift D and B to their new positions, and combine the words with and and or operations, as follows:
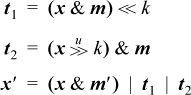
Here, m is a mask with 1’s in field D (and 0’s elsewhere), and m′ is a mask with 1’s in fields A, C, and E. This code requires 11 instructions and six cycles on a machine with unlimited instruction-level parallelism, allowing for four instructions to generate the two masks.
A method that requires only eight instructions and executes in five cycles, under the same assumptions, is shown below [GLS1]. It is similar to the code in column (c) on page 46 for interchanging corresponding fields of two registers. Again, m is a mask that isolates field D.
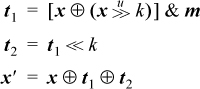
The idea is that t1 contains B ⊕ D in position D (and 0’s elsewhere), and t2 contains B ⊕ D in position B. This code, and the straightforward code given earlier, work correctly if B and D are “split fields”—that is, if the 1-bits of mask m are not contiguous.
Conditional Exchange
The exchange methods of the preceding two sections, which are based on exclusive or, degenerate into no-operations if the mask m is 0. Hence, they can perform an exchange of entire registers, or of corresponding fields of two registers, or of two fields of the same register, if m is set to all 1’s if some condition c is true, and to all 0’s if c is false. This gives branch-free code if m can be set up without branching.