
Like this article? We recommend
Like this article? We recommend
Like this article? We recommend
A Fresh Approach to Iteration
Notice that GoF iterators are not subject to many of the safety issues of STL iterators. You don't need two GoF iterators to iterate over a collection, so pairing-related errors are avoided by design. Also, it is quite easy to implement some minimal checking inside the primitives IsDone, Next, and CurrentItem, as shown below for a hypothetical iterator over an array holding objects of type T.
class ArrayIterator {
public:
bool IsDone() {
assert(begin <= end);
return begin == end;
}
void Next() {
assert(!IsDone());
++begin;
}
T CurrentItem() {
assert(!IsDone());
return *begin;
}
private:
T* begin;
T* end;
}
The GoF interface is naturally more robust without necessarily losing efficiency. The conceptual gain is that the limits are now an indivisible unit presenting a higher-level and safer interface.
For some uses, GoF-style iterators can be just as efficient as iterators, though they sometimes suffer a little in the comparison. For example, the tests for IsDone are just as efficient as with iterators. However, an ArrayIterator is twice the size of an STL iterator, which can be a significant overhead if the iterator is used to refer to a single container element. (For example, consider a large array and a bunch of iterators referring to elements in it.) Yet in many cases, STL iterators must be used in pairs anyway, and for such cases there is no overhead at all.
On the other hand, the STL has effectively demonstrated that iteration is about more than just IsDone, Next, and CurrentItem. Let's adopt and improve on both the STL's and the GoF iterator ideas to get an efficient, flexible, simple, and highly useful iterator. Instead of building upon pointers as the fundamental abstraction, as does the STL, it's better to start with the GoF approach. This allows the iterator type to be smarter and safer without losing efficiency, at least in most use cases. The iterator categories in the STL are highly useful, so let's keep them. As the previous example shows, the new iterator must know its limits—the beginning and end of its range. Therefore, the name of this new candidate abstraction shall be "range," and its refinements—input, output, forward, double-ended, and random access, if not others—"categories."
Separating Access from Traversal
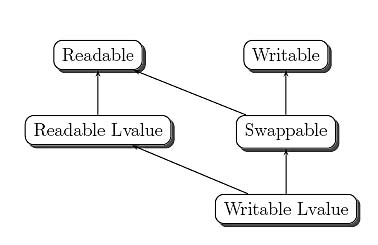
This article is concerned with traversal more than access, but the proposal by Abrahams et al. (discussed in the section "Traversal and Access") is compelling. Let's take one simple abstraction step that allows us to benefit from the separation, without needing to discuss access details in great detail: We encapsulate the access category of ranges as a type called Ref<T>, where T is the native type of the range. Ref<T> is a type that may simply be a synonym for T, or for reference-to-T, but can also be a proxy to a T allowing some or all of read, write, swap, and address taking. Essentially Ref<T> is a wildcard that could fulfill any of the categories in Figure 2. The range categories we discuss below may be parameterized with Ref in addition to T.
{kind=link}
One-Pass Ranges
Let's start with input from a sequential stream, such as reading one keystroke at a time from the keyboard, reading a network packet, or using C's fgetc API. For these, we can easily adapt the IsDone/CurrentItem/Next troika: IsDone checks for end-of-input and fills a one-element buffer held inside the range object, CurrentItem returns the buffer, and Next sets an internal flag that tells IsDone to read the next element when called. Let's define the one-pass interface and also take the opportunity to change the names of the primitives. (As you'll soon see, the new names scale better when we extend the interface.)
interface OnePassRange {
bool empty();
Ref<T> front();
void popFront();
}
The use of "interface" above is informal. Depending on your language of choice, you could use explicit interfaces but also implicit interfaces and duck typing [10] (e.g., "If it has empty, front, and popFront then it's an input range").
To use OnePassRange, you'd write a loop along the following lines:
OnePassRange r = ...;
for (; !r.empty(); r.popFront()) {
... use r.front() ...
}
With input ranges, we can already define some pretty neat algorithms, such as the functional powerhouses map and reduce. To keep things simple, let's take a look at the find algorithm:
OnePassRange find(OnePassRange r, T value) {
for (; !r.empty(); r.popFront()) {
if (r.front() == value) break;
}
return r;
}
find has a very simple specification—it advances the passed-in range until it finds the value, or until the range is exhausted. It returns the balance of the range starting with the found value.
Note that one-pass ranges allow output as well as input—it's up to whichever Ref<T> you use to allow reading, writing, or both. If we denote a writable onepass range with WOnePassRange, we can define the copy algorithm like this:
WOnePassRange copy(
OnePassRange src, WOnePassRange tgt) {
for (; !src.empty();
src.popFront(), tgt.popFront()) {
assert(!tgt.empty());
tgt.front() = src.front();
}
return tgt;
}
The copy function returns the balance of the target range, which allows you to continue copying in it.
Forward Ranges
Forward ranges are most similar to what functional languages and GoF iterators implement: strictly forward iteration over an in-memory entity.
interface ForwardRange : OnePassRange {
ForwardRange save();
}
ForwardRange defines all of OnePassRange's primitives plus save, which returns a snapshot of the iteration state.
Why is just a regular copy not enough?
void fun(ForwardRange r) {
ForwardRange lookIMadeACopy = r;
...
}
The save method serves two purposes. First, in a language with reference semantics (such as Java), lookIMadeACopy is not a copy at all—it's an alias, another reference to the same underlying Range object. Copying the actual object requires a method call. Second, in a language with value semantics, like C++, there's no distinction between copying to pass an argument to a function and copying to save a snapshot of the range. Calling save makes that syntactically obvious. (This solves a problem that plagues the STL's forward and input iterators, which are syntactically indistinguishable while semantically distinct—a perennial source of trouble.)
Using the forward range interface, we can define a host of interesting algorithms. To get an idea of what range-based algorithms would look like, consider defining a function findAdjacent that advances through a range until its first and second elements are equal:
ForwardRange findAdjacent(ForwardRange r){
if (!r.empty()) {
auto s = r.save();
s.popFront();
for (; !s.empty();
r.popFront(), s.popFront()) {
if (r.front() == s.front()) break;
}
}
return r;
}
After auto s = r.save(); the ranges s and r are considered independent. If you attempt to pass a OnePassRange instead of a ForwardRange, the code would not work because OnePassRanges don't have a save method. If ForwardRange just used copying instead of save, then the code would compile with a OnePassRange, but would produce wrong results at runtime. (For the curious: It would stop at the first step, because r.front() is trivially equal to s.front() when r and s are actually tied together.)
Double-Ended Ranges
The next step of range specialization is to define double-ended ranges, characterized by two extra methods, back and popBack, corresponding to front and popFront for forward iteration:
interface DoubleEndedRange : ForwardRange {
Ref<T> back();
void popBack();
}
Let's try our hand at the reverse algorithm, which reverses a swappable double-ended range in place.
void reverse(DoubleEndedRange r) {
while (!r.empty()) {
swap(r.front(), r.back());
r.popFront();
if (r.empty()) break;
r.popBack();
}
}
Easy as pie. We can define not only algorithms that use ranges, but also new ranges, which is very useful. For example, defining a range Retro that walks a double-ended range backwards is a simple matter of cross-wiring front with back and popFront with popBack:
struct Retro<DoubleEndedRange> {
private DoubleEndedRange r;
bool empty() { return r.empty(); }
Ref<T> front() { return r.back(); }
void popFront() { r.popBack(); }
Ref<T> back() { return r.front(); }
void popBack() { r.popFront(); }
}
Random Access Ranges
The most powerful range of all, the random access range, adds constant-time indexed access in addition to the single-ended range primitives. This category of range notably covers contiguous arrays but also noncontiguous structures such as STL's deque. The random access interface offers all of ForwardRange's primitives, plus two random access primitives, at and slice. at fetches an element given the index, and slice produces a subrange lying between two indices.
interface RandomAccessRange : ForwardRange {
Ref<T> at(int i);
RandomAccessRange slice(int i, int j);
}
A startling detail is that RandomAccessRange extends ForwardRange, not DoubleEndedRange. What's happening? Infiniteness, that's what happens. Consider a simple range that yields numbers modulo 10: 0, 1, 2, …, 9, 0, 1, …. Given an index, it's easy to compute the corresponding series element, so the range is rightfully a RandomAccessRange. But this range does not have a "last" element, so it cannot define DoubleEndedRange's primitives. So a random access range extends different concepts, depending on its finiteness.
Many algorithms require constant-time slicing. Consider quicksort as an example: it cannot select a good pivot (ahem) unless it has constant-time random access, and then it needs constant-time slicing to divide the input in two at a randomly chosen point.
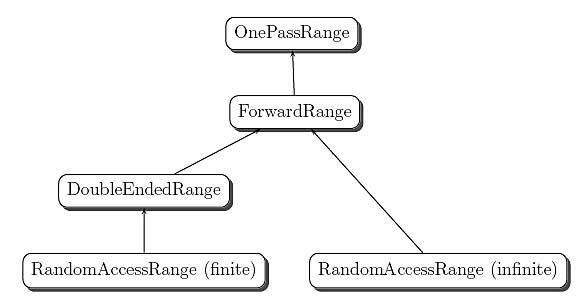
Figure 3 shows the proposed conceptual hierarchy for ranges.
{kind=link}
)
Figure 3 The proposed Range concept hierarchy.