- 3.1 Classification Tasks
- 3.2 A Simple Classification Dataset
- 3.3 Training and Testing: Don't Teach to the Test
- 3.4 Evaluation: Grading the Exam
- 3.5 Simple Classifier #1: Nearest Neighbors, Long Distance Relationships, and Assumptions
- 3.6 Simple Classifier #2: Naive Bayes, Probability, and Broken Promises
- 3.7 Simplistic Evaluation of Classifiers
- 3.8 EOC
This chapter is from the book
This chapter is from the book
This chapter is from the book
3.6 Simple Classifier #2: Naive Bayes, Probability, and Broken Promises
Another basic classification technique that draws directly on probability for its inspiration and operation is the Naive Bayes classifier. To give you insight into the underlying probability ideas, let me start by describing a scenario.
There’s a casino that has two tables where you can sit down and play games of chance. At either table, you can play a dice game and a card game. One table is fair and the other table is rigged. Don’t fall over in surprise, but we’ll call these Fair and Rigged. If you sit at Rigged, the dice you roll have been tweaked and will only come up with six pips—the dots on the dice—one time in ten. The rest of the values are spread equally likely among 1, 2, 3, 4, and 5 pips. If you play cards, the scenario is even worse: the deck at the rigged table has no face cards—kings, queens, or jacks—in it. I’ve sketched this out in Figure 3.6. For those who want to nitpick, you can’t tell these modifications have been made because the dice are visibly identical, the card deck is in an opaque card holder, and you make no physical contact with either the dice or the deck.
){kind=link}
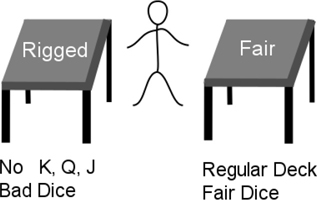
FIGURE 3.6 Fair and rigged tables at a casino.
Suppose I tell you—truthfully!—that you are sitting at Rigged. Then, when you play cards for a while and never see a face card, you aren’t surprised. You also won’t expect to see sixes on the die very often. Still, if you know you are at Rigged, neither of the outcomes of the dice or card events is going to add anything to your knowledge about the other. We know we are at Rigged, so inferring that we are Rigged doesn’t add a new fact to our knowledge—although in the real world, confirmation of facts is nice.
Without knowing what table we are at, when we start seeing outcomes we receive information that indicates which table we are at. That can be turned into concrete predictions about the dice and cards. If we know which table we’re at, that process is short-circuited and we can go directly to predictions about the dice and cards. The information about the table cuts off any gains from seeing a die or card outcome. The story is similar at Fair. If I tell you that you just sat down at the fair table, you would expect all the dice rolls to happen with the same probability and the face cards to come up every so often.
Now, imagine you are blindfolded and led to a table. You only know that there are two tables and you know what is happening at both—you know Rigged and Fair exist.
However, you don’t know whether you are at Rigged or Fair. You sit down and the blindfold is removed. If you are dealt a face card, you immediately know you are at the Fair table. When we knew the table we were sitting at, knowing something about the dice didn’t tell us anything additional about the cards or vice versa. Now that we don’t know the table, we might get some information about the dice from the cards. If we see a face card, which doesn’t exist at Rigged, we know we aren’t at Rigged. We must be at Fair. (That’s double negative logic put to good use.) As a result, we know that sixes are going to show up regularly.
Our key takeaway is that there is no communication or causation between the dice and the cards at one of the tables. Once we sit at Rigged, picking a card doesn’t adjust the dice odds. The way mathematicians describe this is by saying the cards and the dice are conditionally independent given the table.
That scenario lets us discuss the main ideas of Naive Bayes (NB). The key component of NB is that it treats the features as if they are conditionally independent of each other given the class, just like the dice and cards at one of the tables. Knowing the table solidifies our ideas about what dice and cards we’ll see. Likewise, knowing a class sets our ideas about what feature values we expect to see.
Since independence of probabilities plays out mathematically as multiplication, we get a very simple description of probabilities in a NB model. The likelihood of features for a given class can be calculated from the training data. From the training data, we store the probabilities of seeing particular features within each target class. For testing, we look up probabilities of feature values associated with a potential target class and multiply them together along with the overall class probability. We do that for each possible class. Then, we choose the class with the highest overall probability.
I constructed the casino scenario to explain what is happening with NB. However, when we use NB as our classification technique, we assume that the conditional independence between features holds, and then we run calculations on the data. We could be wrong. The assumptions might be broken! For example, we might not know that every time we roll a specific value on the dice, the dealers—who are very good card sharks—are manipulating the deck we draw from. If that were the case, there would be a connection between the deck and dice; our assumption that there is no connection would be wrong. To quote a famous statistician, George Box, “All models are wrong but some are useful.” Indeed.
Naive Bayes can be very useful. It turns out to be unreasonably useful in text classification. This is almost mind-blowing. It seems obvious that the words in a sentence depend on each other and on their order. We don’t pick words at random; we intentionally put the right words together, in the right order, to communicate specific ideas. How can a method which ignores the relationship between words—which are the basis of our features in text classification—be so useful? The reasoning behind NB’s success is two-fold. First, Naive Bayes is a relatively simple learning method that is hard to distract with irrelevant details. Second, since it is particularly simple, it benefits from having lots of data fed into it. I’m being slightly vague here, but you’ll need to jump ahead to the discussion of overfitting (Section 5.3) to get more out of me.
Let’s build, fit, and evaluate a simple NB model.
In [10]:
nb = naive_bayes.GaussianNB()
fit = nb.fit(iris_train_ftrs, iris_train_tgt)
preds = fit.predict(iris_test_ftrs)
print("NB accuracy:",
metrics.accuracy_score(iris_test_tgt, preds))
NB accuracy: 1.0
Again, we are perfect. Don’t be misled, though. Our success says more about the ease of the dataset than our skills at machine learning.