- 3.1 Classification Tasks
- 3.2 A Simple Classification Dataset
- 3.3 Training and Testing: Don't Teach to the Test
- 3.4 Evaluation: Grading the Exam
- 3.5 Simple Classifier #1: Nearest Neighbors, Long Distance Relationships, and Assumptions
- 3.6 Simple Classifier #2: Naive Bayes, Probability, and Broken Promises
- 3.7 Simplistic Evaluation of Classifiers
- 3.8 EOC
This chapter is from the book
This chapter is from the book
This chapter is from the book
3.2 A Simple Classification Dataset
The iris dataset is included with sklearn and it has a long, rich history in machine learning and statistics. It is sometimes called Fisher’s Iris Dataset because Sir Ronald Fisher, a mid-20th-century statistician, used it as the sample data in one of the first academic papers that dealt with what we now call classification. Curiously, Edgar Anderson was responsible for gathering the data, but his name is not as frequently associated with the data. Bummer. History aside, what is the iris data? Each row describes one iris—that’s a flower, by the way—in terms of the length and width of that flower’s sepals and petals (Figure 3.1). Those are the big flowery parts and little flowery parts, if you want to be highly technical. So, we have four total measurements per iris. Each of the measurements is a length of one aspect of that iris. The final column, our classification target, is the particular species—one of three—of that iris: setosa, versicolor, or virginica.
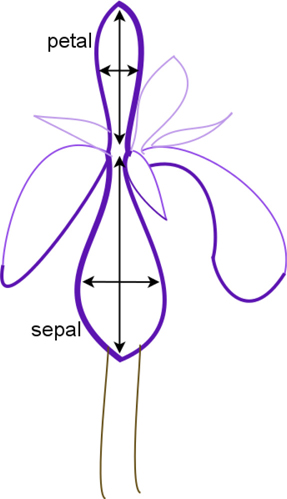
FIGURE 3.1 An iris and its parts.
We’ll load the iris data, take a quick tabular look at a few rows, and look at some graphs of the data.
In [2]:
iris = datasets.load_iris()
iris_df = pd.DataFrame(iris.data,
columns=iris.feature_names)
iris_df['target'] = iris.target
display(pd.concat([iris_df.head(3),
iris_df.tail(3)]))
|
sepal length (cm) |
sepal width (cm) |
petal length (cm) |
petal width (cm) |
target |
|---|---|---|---|---|---|
0 |
5.1000 |
3.5000 |
1.4000 |
0.2000 |
0 |
1 |
4.9000 |
3.0000 |
1.4000 |
0.2000 |
0 |
2 |
4.7000 |
3.2000 |
1.3000 |
0.2000 |
0 |
147 |
6.5000 |
3.0000 |
5.2000 |
2.0000 |
2 |
148 |
6.2000 |
3.4000 |
5.4000 |
2.3000 |
2 |
149 |
5.9000 |
3.0000 |
5.1000 |
1.8000 |
2 |
In [3]:
sns.pairplot(iris_df, hue='target', size=1.5);
)
){kind=link}
sns.pairplot gives us a nice panel of graphics. Along the diagonal from the top-left to bottom-right corner, we see histograms of the frequency of the different types of iris differentiated by color. The off-diagonal entries—everything not on that diagonal—are scatter plots of pairs of features. You’ll notice that these pairs occur twice—once above and once below the diagonal—but that each plot for a pair is flipped axis-wise on the other side of the diagonal. For example, near the bottom-right corner, we see petal width against target and then we see target against petal width (across the diagonal). When we flip the axes, we change up-down orientation to left-right orientation.
In several of the plots, the blue group (target 0) seems to stand apart from the other two groups. Which species is this?
In [4]:
print('targets: {}'.format(iris.target_names),
iris.target_names[0], sep="\n")
targets: ['setosa' 'versicolor' 'virginica'] setosa
So, looks like setosa is easy to separate or partition off from the others. The vs, versicolor and virginica, are more intertwined.