Network Storage Evaluations Using Reliability Calculations
- Defining <i>Reliability</i> and <i>Redundancy</i>
- Case Study
- References
Like this article? We recommend
Like this article? We recommend
Like this article? We recommend
Introduction
Today, many storage solutions and configurations are available. You have specific storage requirements, and you need techniques for evaluating which solutions are best suited for your environment.
When designing storage architecture, you must take several parameters into account. Depending on your requirements, some parameters are more important than others. For example, performance might be your main concern, or resiliency, or perhaps cost is the driving influence. A compromise among all parameters must be found in order to achieve the best results for a given environment.
While a complete and thorough evaluation of all storage area networking (SAN) aspects is required in the planning stage, this article provides an introduction to specific techniques for evaluating the redundancy and reliability of network storage solutions. The intent is to provide you with another tool for the trade.
Defining Reliability and Redundancy
This article defines the terms reliability and redundancy, and describes case studies using three different network storage architectures. The architectures are compared for their advantages and disadvantages in terms of redundancy.
In the case where two solutions are fully redundant, it is important to refine the evaluation. We do so by figuring out the reliability of each solution. This provides additional criteria to use in your network storage architecture planning.
Redundancy
A system is redundant if one failure of any of its components does not affect the system's purpose. Redundancy of a storage system is sought to increase overall reliability.
Redundant storage configurations provide a means to survive hardware failures that are considered inevitable, because at some point in time, a component failure is bound to happen.
To find out if a system is redundant, you must enumerate each one of its components, and for every component, evaluate whether its failure compromises the overall system.
Reliability
For the purpose of this article, reliability is divided into component reliability and system reliability.
Component Reliability
The overall reliability of a storage system is based on the reliability of each of its components. The calculation of the component reliability (R) value starts with the mean time between failures (MTBF) value (published by the manufacturer of each component). From this, we can determine the annual failure rate (AFR), which is used to determine the reliability value.
The MTBF statistic represents the average time it takes for a failure to occur. A MTBF of 100,000 hours means that one failure occurs every 100,000 hours on average.
Component reliability formula:
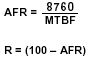
Note
8760 is the total number of hours per year (365 x 24 = 8760).
Example:
For a component with a MTBF value of 100,000 hours, the following reliability value is determined:
AFR = 8760/100000 = 0.0876
R = (1 – 0.0876) = 0.9124 (or 91.24%)
System Reliability
Several methods exist to obtain a figure for the system MTBF. This article uses a method called block diagram analysis.
In a storage system, a component is configured in one of two ways:
Redundant configuration (in parallel)
Non-redundant configuration (in series)
The system is split logically into blocks of components. Blocks represent either a redundant component configuration or a non-redundant component configuration.
When the components are in a redundant configuration, the risk of system failure due to the failure of one component diminishes at the power of the number of redundant components.
When configured as a non-redundant components, the risk of a system failure is equal to the sum of the risks of each component.
Block Diagram Analysis and Network Storage
The purpose of a network storage system is to link a process (user or application) to data (stored on media).
One way to determine the reliability of a network storage architecture, is to use a method called block diagram analysis. We start by drawing a functional picture of this storage system showing how a process can reach the data. Then, using the rules presented above, we calculate the reliability of the overall system.
Examples
Let's consider a logical block made of components each with an AFR = 0.0876. This block can be either in a redundant or non-redundant configuration, as shown in the following figure.
) FIGURE 1 Redundant and Non-redundant Logical Block Diagrams
FIGURE 1 Redundant and Non-redundant Logical Block Diagrams
Example 1:
The block has three components in a redundant configuration. The risk of a system failure in the first year is equal to the risk of all three components failing.
Formula for redundant configurations:
System AFR = ( x )y (x=component AFR, y=number of components in parallel)
Applied to example 1:
System AFR = (0.0876)3 = 0.0006722 (or 0.067%)
Example 2:
The block has three components connected in series. The risk of the whole system failing in the first year is equal to the failure of any single component in the system.
Formula for non-redundant configurations:
System AFR = x * y (x=component AFR, y=number of components in series)
Applied to example 2:
System AFR = 3 * 0.0876 = 0.2628 (or 26.28%)
NOTE
This is a very intuitive method to determine the reliability of a system. However, for more complex systems, computer modeling is used to study the reliability.