
- Metaphors
- Issues
- Interfaces
- Implementations
- Collections
- Extending Collections
- Conclusion
This chapter is from the book
This chapter is from the book
This chapter is from the book
Implementations
Choosing implementation classes for collections is primarily a matter of performance. As with all performance issues, it is best to pick a simple implementation to begin with and then tune based on experience.
)
Figure 9.1 Collection interfaces and classes
In this section, each interface introduces alternative implementations. Because performance considerations dominate the choice of implementation class, each set of alternatives is accompanied by performance measurements for important operations. Appendix, “Performance Measurement,” provides the source code for the tool I used to gather this data.
By far the majority of collections are implemented by ArrayList, with HashSet a distant second (~3400 references to ArrayList in Eclipse+JDK versus ~800 references to HashSet). The quick-and-dirty solution is to choose whichever of these classes suits your needs. However, for those times when experience shows that performance matters, the remainder of this section presents the details of the alternative implementations.
A final factor in choosing a collection implementation class is the size of the collections involved. The data presented below shows the performance of collections sized one to one hundred thousand. If your collections only contain one or two elements, your choice of implementation class may be different than if you expect them to scale to millions of elements. In any case, the gains available from switching implementation classes are often limited, and you’ll need to look for larger-scale algorithmic changes if you want to further improve performance.
Collection
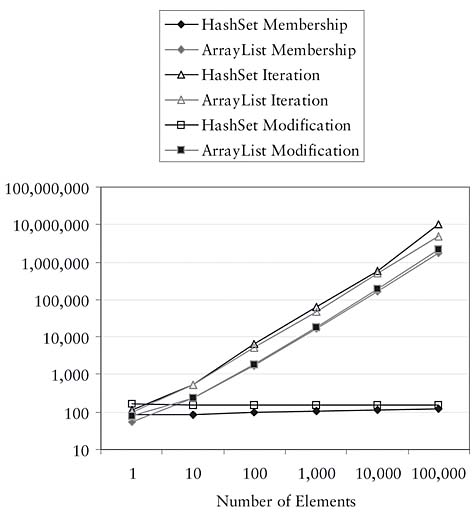
The default class to use when implementing a Collection is ArrayList. The potential performance problem with ArrayList is that contains(Object) and other operations that rely on it like remove(Object) take time proportional to the size of the collection. If a performance profile shows one of these methods to be a bottleneck, consider replacing your ArrayList with a HashSet. Before doing so, make sure that your algorithm is insensitive to discarding duplicate elements. When you have data that is already guaranteed to contain no duplicates, the switch won’t make a difference. Figure 9.2 compares the performance of ArrayList and HashSet. (See Appendix A for the details of how I collected this information.)
{kind=link}
Figure 9.2 Comparing ArrayList and HashSet as implementations of Collection
List
To the Collection protocol, List adds the idea that the elements are in a stable order. The two implementations of List in common use are ArrayList and LinkedList.
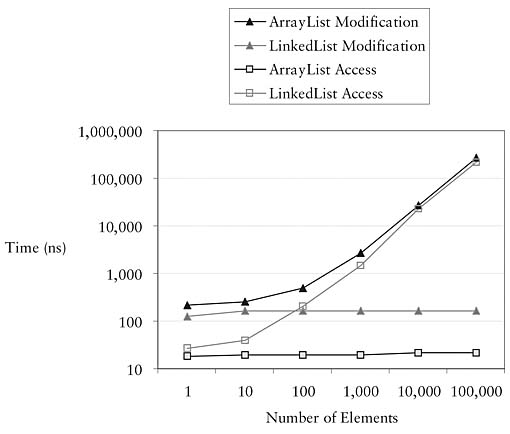
The performance profiles of these two implementations are mirror images. ArrayList is fast at accessing elements and slow at adding and removing elements, while LinkedList is slow at accessing elements and fast at adding and removing elements (see Figure 9.3). If you see a profile dominated by calls to add() or remove(), consider switching an ArrayList to a LinkedList.
{kind=link}
)
Figure 9.3 Comparing ArrayList and LinkedList
Set
There are three main implementations of Set: HashSet, LinkedHashSet, and TreeSet (which actually implements SortedSet). HashSet is the fastest but its elements are in no guaranteed order. A LinkedHashSet maintains elements in the order in which they were added, but at the cost of an extra 30% time penalty for adding and removing elements (see Figure 9.3). TreeSet keeps its elements sorted according to a Comparator but at the cost of making adding and removing elements or testing for an element take time proportional to log n, where n is the size of the collection.
Choose a LinkedHashSet if you need the order of elements to be stable. External users, for example, may appreciate getting elements in the same order each time.
)
Figure 9.4 Comparing Set implementations.
Map
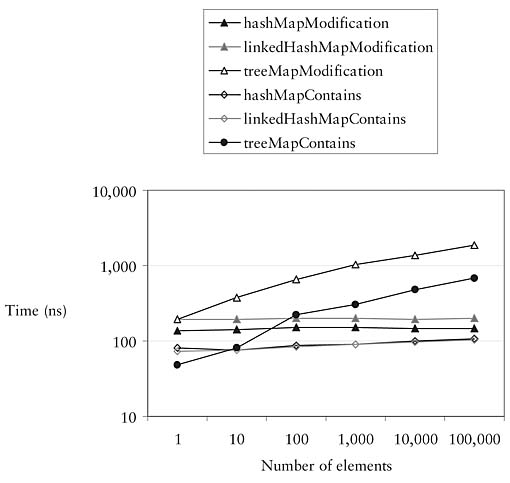
The implementations of Map follow a similar pattern to the implementations of Set. HashMap is the fastest and simplest. LinkedHashMap preserves the order of elements, iterating over the elements in the order in which they were inserted. TreeMap (actually an implementation of SortedMap) iterates over entries based on the order of the keys, but at the cost of making insertion and inclusion testing take time proportional to log n. Figure 9.5 summarizes the way performance scales for these Map implementations.
{kind=link}
)
Figure 9.5 Comparing Map implementations.