Computer Security and Statistical Databases
This chapter is from the book
This chapter is from the book
This chapter is from the book
A statistical database (SDB) is one that provides data of a statistical nature, such as counts and averages. The term statistical database is used in two contexts:
- Pure statistical database: This type of database only stores statistical data. An example is a census database. Typically, access control for a pure SDB is straightforward: Certain users are authorized to access the entire database.
- Ordinary database with statistical access: This type of database contains individual entries; this is the type of database discussed so far in this chapter. The database supports a population of nonstatistical users who are allowed access to selected portions of the database using DAC, RBAC, or MAC. In addition, the database supports a set of statistical users who are only permitted statistical queries. For these latter users, aggregate statistics based on the underlying raw data are generated in response to a user query, or may be precalculated and stored as part of the database.
For the purposes of this section, we are concerned only with the latter type of database and, for convenience, refer to this as an SDB. The access control objective for an SDB system is to provide users with the aggregate information without compromising the confidentiality of any individual entity represented in the database. The security problem is one of inference. The database administrator must prevent, or at least detect, the statistical user who attempts to gain individual information through one or a series of statistical queries.
For this discussion, we use the abstract model of a relational database table shown as Figure 5.7. There are N individuals, or entities, in the table and M attributes. Each attribute A
Table 5.3 Statistical Database Example
)
Figure 5.7. Abstract Model of a Relational Database
Statistics are derived from a database by means of a characteristic formula, C, which is a logical formula over the values of attributes. A characteristic formula uses the operators OR, AND, and NOT (+, ·, ~), written here in order of increasing priority. A characteristic formula specifies a subset of the records in the database. For example, the formula
(Sex = Male) · ((Major = CS) + (Major = EE))
specifies all male students majoring in either CS or EE. For numerical attributes, relational operators may be used. For example, (GP>
The query set of characteristic formula C, denoted as X(C), is the set of records matching that characteristic. For example, for C = Female · CS, X(C) consists of records 1 and 4, the records for Allen and Davis.
A statistical query is a query that produces a value calculated over a query set. Table 5.4 lists some simple statistics that can be derived from a query set. Examples: count(Female · CS) = 2; sum(Female · CS, SAT) = 1400.
Table 5.4 Some Queries of a Statistical Database
Inference from a Statistical Database
A statistical user of an underlying database of individual records is restricted to obtaining only aggregate, or statistical, data from the database and is prohibited access to individual records. The inference problem in this context is that a user may infer confidential information about individual entities represented in the SDB. Such an inference is called a compromise. The compromise is positive if the user deduces the value of an attribute associated with an individual entity and is negative if the user deduces that a particular value of an attribute is not associated with an individual entity. For example, the statistic sum(EE· Female, GP) = 2.5 compromises the database if the user knows that Baker is the only female EE student.
In some cases, a sequence of queries may reveal information. For example, suppose a questioner knows that Baker is a female EE student but does not know if she is the only one. Consider the following sequence of two queries:
count (EE · Female) = 1 sum (EE · Female, GP) = 2.5
This sequence reveals the sensitive information.
The preceding example shows how some knowledge of a single individual in the database can be combined with queries to reveal protected information. For a large database, there may be few or no opportunities to single out a specific record that has a unique set of characteristics, such as being the only female student in a department. Another angle of attack is available to a user aware of an incremental change to the database. For example, consider a personnel database in which the sum of salaries of employees may be queried. Suppose a questioner knows the following information:
- Salary range for a new systems analyst with a BS degree is $[50K, 60K]
- Salary range for a new systems analyst with a MS degree is $[60K, 70K]
Suppose two new systems analysts are added to the payroll and the change in the sum of the salaries is $130K. Then the questioner knows that both new employees have an MS degree.
In general terms, the inference problem for an SDB can be stated as follows. A characteristic function C defines a subset of records (rows) within the database. A query using C provides statistics on the selected subset. If the subset is small enough, perhaps even a single record, the questioner may be able to infer characteristics of a single individual or a small group. Even for larger subsets, the nature or structure of the data may be such that unauthorized information may be released.
Query Restriction
SDB implementers have developed two distinct approaches to protection of an SDB from inference attacks (Figure 5.8):
)
){kind=link}
){kind=link}
- Query restriction: Rejects a query that can lead to a compromise. The answers provided are accurate.
- Perturbation: Provides answers to all queries, but the answers are approximate.
We examine query restriction in this section and perturbation in the next. Query restriction techniques defend against inference by restricting statistical queries so that they do not reveal user confidential information. Restriction in this context simply means that some queries are denied.
Query Size Restriction
The simplest form of query restriction is query size restriction. For a database of size N (number of rows, or records), a query q(C) is permitted only if the number of records that match C satisfies
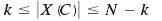
where k is a fixed integer greater than 1. Thus, the user may not access any query set of less than k records. Note that the upper bound is also needed. Designate All as the set of all records in the database. If q(C) is disallowed because |X(C)| k, and there is no upper bound, then a user can compute q(C) = q(All) − q(˜C). The upper bound of N - k guarantees that the user does not have access to statistics on query sets of less than k records. In practice, queries of the form q(All) are allowed, enabling users to easily access statistics calculated on the entire database.
Query size restriction counters attacks based on very small query sets. For example, suppose a user knows that a certain individual I satisfies a given characteristic formula C (e.g., Allen is a female CS major). If the query count(C) returns 1, then the user has uniquely identified I. Then the user can test whether I has a particular characteristic D with the query count(C· D). Similarly, the user can learn the value of a numerical attribute A for I with the query sum(C, A).
Although query size restriction can prevent trivial attacks, it is vulnerable to more sophisticated attacks, such as the use of a tracker [DENN79]. In essence, the questioner divides his or her knowledge of an individual into parts, such that queries can be made based on the parts without violating the query size restriction. The combination of parts is called a tracker, because it can be used to track down characteristics of an individual. We can describe a tracker in general terms using the case from the preceding paragraph. The formula C·D corresponds to zero or one record, so that the query count(C·&) is not permitted. But suppose that the formula C can be decomposed into two parts C = C1·C2, such that the query sets for both C1 and T = (C1·˜C2) satisfy the query size restriction. Figure 5.9 illustrates this situation; in the figure, the size of the circle corresponds to the number of records in the query set. If it is not known if I is uniquely identified by C, the following formula can be used to determine if count(C) = 1:
count(C)=count(C1)−count(T)(5.2)
That is, you count the number of records in C1 and then subtract the number of records that are in C1 but not in C2. The result is the number of records that are in both C1 and C2, which is equal to the number of records in C. By a similar reasoning, it can be shown that we can determine whether I has attribute D with
count(C · D) = count(T +; C1 · D)−count(T)
For example, in Table 5.3, Evans is identified by C = Male·Bio·1979. Let k= 3 in Equation 501. We can use T = (C1· ˜C2) = Male· ˜ (Bio· 1979). Both C1 and C2 satisfy the query size restriction. Using Equations (5.2) and (5.3), we determine that Evans is uniquely identified by C and whether his SAT score is at least 600:
)
Figure 5.9. Example of Tracker
In a large database, the use of just a few queries will typically be inadequate to compromise the database. However, it can be shown that more sophisticated tracker attacks may succeed even against large databases in which the threshold k is set at a relatively high level [DENN79].
We have looked at query size restriction in some detail because it is easy to grasp both the mechanism and its vulnerabilities. A number of other query restriction approaches have been studied, all of which have their own vulnerabilities. However, several of these techniques in combination do reduce vulnerability.
Query Set Overlap Control
A query size restriction is defeated by issuing queries in which there is considerable overlap in the query sets. For example, in one of the preceding examples the query sets Male and Male· ˜ (Bio· 1979) overlap significantly, allowing an inference. To counter this, the query set overlap control provides the following limitation.
A query q(C) is permitted only if the number of records that match C satisfies
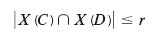
for all q(D) that have been answered for this user, and where r is a fixed integer greater than 0.
This technique has a number of problems, including the following [ADAM89]:
- This control mechanism is ineffective for preventing the cooperation of several users to compromise the database.
- Statistics for both a set and its subset (e.g., all patients and all patients undergoing a given treatment) cannot be released, thus limiting the usefulness of the database.
- For each user, a user profile has to be kept up to date.
Partitioning
Partitioning can be viewed as taking query set overlap control to its logical extreme, by not allowing overlapping queries at all. With partitioning, the records in the database are clustered into a number of mutually exclusive groups. The user may only query the statistical properties of each group as a whole. That is, the user may not select a subset of a group. Thus, with multiple queries, there must either be complete overlap (two different queries of all the records in a group) or zero overlap (two queries from different groups).
The rules for partitioning the database are as follows:
- Each group G has g = |G| records, where g = 0 or g≥ n, and g even, where n is a fixed integer parameter.
- Records are added or deleted from G in pairs.
- Query sets must include entire groups. A query set may be a single group or multiple groups.
A group of a single record is forbidden, for obvious reasons. The insertion or deletion of a single record enables a user to gain information about that record by taking before and after statistics. As an example, the database of Table 5.3a can be partitioned as shown in Table 5.5. Because the database has an odd number of records, the record for Kline has been omitted. The database is partitioned by year and sex, except that for 1978, it is necessary to merge the Female and Male records to satisfy the design requirement.
Table 5.5 Partitioned Database
View Table){kind=link}
Partitioning solves some security problems but has some drawbacks. The user’s ability to extract useful statistics is reduced, and there is a design effort in constructing and maintaining the partitions.
Query Denial and Information Leakage
A general problem with query restriction techniques is that the denial of a query may provide sufficient clues that an attacker can deduce underlying information. This is generally described by saying that query denial can leak information.
Here is a simple example from [KENT05]. Suppose that the underlying database consists of real-valued entries and that a query is denied only if it would enable the requestor to deduce a value. Now suppose the requester poses the query sum(x
[KENT05] describes an approach to counter this threat, referred to as simulatable auditing. The details of this approach are beyond the scope of this chapter. In essence, the system monitors all of the queries from a given source and decides on the basis of the queries so far posed whether to deny a new query. The decision is based solely on the history of queries and answers and the specific new query. In deciding whether to deny the query, the system does not consider the actual values of database elements that will contribute to generating the answer and therefore does not consider the actual value of the answer. Thus, the system makes the denial decision solely on the basis of information that is already available to the requester (the history of prior requests). Hence the decision to deny a query cannot leak any information. For this approach, the system determines whether any collection of database values might lead to information leakage and denies the query if leakage is possible. In practice, a number of queries will be denied even if leakage is not possible. In the example of the preceding paragraph, this strategy would deny the max query whether or not the three underlying values were equal. Thus, this approach is more conservative in that it issues more denials than an approach that considers the actual values in the database.
Perturbation
Query restriction techniques can be costly and are difficult to implement in such a way as to completely thwart inference attacks, especially if a user has supplementary knowledge. For larger databases, a simpler and more effective technique is to, in effect, add noise to the statistics generated from the original data. This can be done in one of two ways (Figure 5.8): The data in the SDB can be modified (perturbed) so as to produce statistics that cannot be used to infer values for individual records; we refer to this as data perturbation. Alternatively, when a statistical query is made, the system can generate statistics that are modified from those that the original database would provide, again thwarting attempts to gain knowledge of individual records; this is referred to as output perturbation.
Regardless of the specific perturbation technique, the designer must attempt to produce statistics that accurately reflect the underlying database. Because of the perturbation, there will be differences between perturbed results and ordinary results from the database. However, the goal is to minimize the differences and to provide users with consistent results.
As with query restriction, there are a number of perturbation techniques. In this section, we highlight a few of these.
Data Perturbation Techniques
We look at two techniques that consider the SDB to be a sample from a given population that has a given population distribution. Two methods fit into this category. The first transforms the database by substituting values that conform to the same assumed underlying probability distribution. The second method is, in effect, to generate statistics from the assumed underlying probability distribution.
The first method is referred to as data swapping. In this method, attribute values are exchanged (swapped) between records in sufficient quantity so that nothing can be deduced from the disclosure of individual records. The swapping is done in such a way that the accuracy of at least low-order statistics is preserved. Table 5.6, from [DENN82], shows a simple example, transforming the database D into the database D
Table 5.6 Example of Data Swapping
){kind=link}
Another method is to generate a modified database using the estimated underlying probability distribution of attribute values. The following steps are used:
- For each confidential or sensitive attribute, determine the probability distribution function that best matches the data and estimate the parameters of the distribution function.
- Generate a sample series of data from the estimated density function for each sensitive attribute.
- Substitute the generated data of the confidential attribute for the original data in the same rank order. That is, the smallest value of the new sample should replace the smallest value in the original data, and so on.
Output Perturbation Techniques
A simple output perturbation technique is known as random-sample query. This technique is suitable for large databases and is similar to a technique employed by the U.S. Census Bureau. The technique works as follows:
- A user issues a query q(C) that is to return a statistical value. The query set so defined is X(C).
- The system replaces X(C) with a sampled query set, which is a properly selected subset of X(C).
- The system calculates the requested statistic on the sampled query set and returns the value.
Other approaches to output perturbation involve calculating the statistic on the requested query set and then adjusting the answer up or down by a given amount in some systematic or randomized fashion. All of these techniques are designed to thwart tracker attacks and other attacks that can be made against query restriction techniques.
With all of the perturbation techniques, there is a potential loss of accuracy as well as the potential for a systematic bias in the results.
Limitations of Perturbation Techniques
The main challenge in the use of perturbation techniques is to determine the average size of the error to be used. If there is too little error, a user can infer close approximations to protected values. If the error is, on average, too great, the resulting statistics may be unusable.
For a small database, it is difficult to add sufficient perturbation to hide data without badly distorting the results. Fortunately, as the size of the database grows, the effectiveness of perturbation techniques increases. This is a complex topic, beyond the scope of this chapter. Examples of recent work include [DWOR06], [EVFI03], and [DINU03].
The last-mentioned reference reported the following result. Assume the size of the database, in terms of the number of data items or records, is n. If the number of queries from a given source is linear to the size of the database (i.e., on the order of n), then a substantial amount of noise must be added to the system in terms of perturbation, to preserve confidentiality. Specifically, suppose the perturbation is imposed on the system by adding a random amount of perturbation ≤x . Then, if the query magnitude is linear, the perturbation must be at least of order √n . This amount of noise may be sufficient to make the database effectively unusable. However, if the number of queries is sublinear (e.g., of order √n), then much less noise must be added to the system to maintain privacy. For a large database, limiting queries to a sublinear number may be reasonable.