Descriptive Statistics
Drawing on his immense experience helping organizations gain value from statistical methods, Conrad Carlberg shows when and how to use Excel, when and how to use R instead, and how to use them together to get the best from both. Here he discusses how descriptive statistics tools in Excel and R can help you understand the distribution of the variables in your data set.
This chapter is from the book
This chapter is from the book
This chapter is from the book
Regardless of the sort of analysis you have in mind for a particular data set, you want to understand the distribution of the variables in that set. The reasons vary from the mundane (someone entered an impossible value for a variable) to the technical (different sample sizes accompanying different variances).
Any of those events could happen, whether the source of the data is a sales ledger, a beautifully designed medical experiment or a study of political preferences. No matter what the cause, if your data set contains any unexpected values you want to know about it. Then you can take steps to correct data entered in error, or to adjust your decision rules if necessary, or even to replicate the experiment if it looks like something might have gone wrong with the methodology.
The point is that sophisticated multivariate analyses such as factor analysis with Varimax rotation or Cox Proportional Hazards Regression do not alert you when someone entered a patient’s body temperature on Wednesday morning as 986 degrees instead of 98.6 degrees. In that case, the results of your sophisticated procedure might turn out cockeyed, but you would have no special reason to suspect a missing decimal point as the cause of your findings.
You can save yourself a lot of subsequent grief if you just look over some preliminary descriptive statistics based on your data set. If a mean value, the range of the observed values, or their standard deviation looks unusual, you probably should verify and validate the way the data is collected, entered and stored before too much time passes.
Descriptive Statistics in Excel
If you’re using Excel to analyze the data, either as a preliminary check or as your principal numeric application, one way to carry out this sort of work is to point Excel’s various worksheet functions at the data set. MIN( ) gets you the minimum in a set of values, MAX( ) gets you the maximum, and MAX( ) − MIN( ) gets you the range. COUNT( ) counts the numeric values, AVERAGE( ) returns the mean, and either STDEV.S( ) or STDEV.P( ) gets you the standard deviation.
Excel comes equipped with a Descriptive Statistics tool in the Data Analysis add-in (which was at one time termed the Analysis ToolPak or ATP). The Descriptive Statistics tool is good news and bad news.
The good news is that using the tool on an existing data set gets you up to 16 different descriptive statistics, and you don’t have to enter a single function on the worksheet. See Figure 2.1.
)
Figure 2.1 You can analyze multiple variables in one pass.
Figure 2.1 shows 11 values of two different variables in the range A1:B12. A univariate analysis of the variable named MPG appears in the range E3:F18, and a similar analysis of IPS appears in G3:H18. Notice that each statistic reported pertains to one variable only: None of the statistics correlates, for example, MPG with IPS, or reports the means of IPS according to specific values of MPG. The reported statistics are exclusively univariate.
You get them without having to know that Excel has a STDEV.S( ) function that reports the standard deviation of a sample of records, or that the standard errors reported in the fourth row are the standard error of the mean of each variable. The reported statistics are largely useful when you’re getting acquainted with a data set. You’ll normally want to know a lot more than that, of course, but it’s a good place to start.
The bad news is that the reported statistics represent static values. For example, in Figure 2.1, cell F3 contains the value 26 rather than this formula:
=AVERAGE(A2:A12)
Therefore, if you want to change the input values in A1:A12 by adding or deleting a record, or editing an existing value, none of the statistics would change in response. A worksheet formula recalculates when the values it points to change, but the results calculated by the Descriptive Statistics tool do not: They don’t point to anything because they’re just numbers.
Using the Descriptive Statistics Tool
Using the tool is easy enough. You’ll want your active worksheet to have one or more lists or tables, such as the two shown in columns A and B of Figure 2.1. Go to the Ribbon’s Data tab and locate the Data Analysis link in the Analyze group. When you click it, you see the list box shown in Figure 2.2.
)
Figure 2.2 Descriptive Statistics is the list box entry you want for these analyses.
Click Descriptive Statistics and click OK. You’ll get the dialog box shown in Figure 2.3.
)
Figure 2.3 It’s usually best to keep the output on the active worksheet.
Then take these steps:
Click in the Input Range box and drag through the range your data occupies. In Figure 2.1, that’s A1:B12. If you have one variable, the range might be A1:A25, or if you have three variables, the range might be B1:D85. Don’t worry if your variables have different numbers of records, but leave unoccupied cells empty and don’t substitute #N/A for an empty cell.
Accept the default of Grouped By Columns.
If the first row in the input range has labels such as variable names, fill the Labels in First Row checkbox. This instructs Excel not to treat a label as a legitimate data value, which would usually result in an error message that the input range contains non-numeric data.
Click the Output Range option button, unless you want the results to be written to a new workbook or a new worksheet. (Worksheet Ply is just an old term for worksheet.) Careful! If you click the Output Range option button, the Input Range box is re-activated and gets filled with any cell or range that you click next. First, click the Output Range edit box and only then indicate where you want the output to begin.
Fill the Summary Statistics checkbox if you want the statistics shown in row 3 through row 15 in Figure 2.1.
Fill the Confidence Level for Mean checkbox if you want to put a confidence interval around the mean. Enter the confidence level you want in the edit box (often that will be 90, 95, or 99, taken as a percent).
Fill the Kth Largest and the Kth smallest checkboxes if you want that information. Also supply a value for K. That is, if you want the 5th largest value, fill the checkbox and enter 5 in the edit box. (I can’t recall the last time I needed either of these two statistics.)
Click OK. Within a few seconds you should see results such as those shown in columns E through H of Figure 2.1.
Understanding the Results
Here’s a closer look at some of the statistics shown in Figure 2.1. Most of them are precisely what you would expect (mean, median, mode, range, minimum, maximum, sum, count, kth largest, and smallest values). The following may require a little additional information.
Standard Error of the Mean
Suppose that the 11 values in A2:A12 of Figure 2.1 are a sample from a population. Now suppose that you took hundreds or even thousands of similar 11-record samples from the same population. Each of those samples would have its own mean value, such as the one shown in cell F3 of Figure 2.1. If you calculated the standard deviation of all those mean values, you would have a statistic called the standard error of the mean. The value in cell F4 of Figure 2.1 estimates that value, so that you don’t have to actually take hundreds or thousands of additional samples. You can calculate that estimate using this formula:
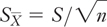
where:
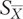 is the standard error of the mean.
is the standard error of the mean.S is the sample standard deviation.
n is the number of records in the sample (the count).
The standard error of the mean is often useful when you want to test the difference between an obtained sample mean and a hypothesized value. It is also an integral part of a confidence interval placed around a sample mean.
Standard Deviation
Excel (and the general field of statistics) offers two types of standard deviation:
Your data constitutes a population. For example, you might have 100 items made in a special production run, after which the mold was broken.
Your data constitutes a sample. You might have 100 items sampled randomly from an ongoing process that yields millions of products per year.
In the first case, where you have an entire population of values, the formula for the standard deviation uses the actual count of values, n, in its denominator. In the second case you are estimating the population’s standard deviation on the basis of your sample, and you use n − 1 instead of n in the denominator.
In Excel, you use the worksheet function STDEV.P( ) when your data is the population. You use STDEV.S( ) when you have a sample. Possession of a sample occurs much more frequently than possession of a population, so the Descriptive Statistics tool returns the value that you would get if you were using the STDEV.S( ) function.
Sample Variance
The variance is the square of the standard deviation, and it’s subject to the same conditions as the standard deviation: That is, the variance has a population form (n) and a sample form (n − 1). The Descriptive Statistics tool returns the sample form of the variance.
Skewness
Skewness measures the symmetry in a distribution of values. An asymmetric distribution is said to be skewed. One popular way of calculating skewness is the average of the cubed standard scores (also termed z-scores):
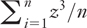
The formula that Excel uses approaches the value of the average cubed z-score as n increases:
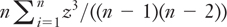
A symmetric distribution is expected to have a skewness of 0.
Kurtosis
Kurtosis measures the degree to which a distribution of scores is taller or flatter with respect to its width. Here’s one textbook definition of kurtosis:
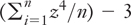
It’s very similar to one definition of skewness, except here the z-scores are raised to the fourth instead of the third power. A distribution such as the normal curve would have an average z-score, raised to the fourth power, of 3. Therefore, 3 is subtracted in the formula so that a normal curve would have kurtosis of 0.
Again, Excel’s formula for kurtosis is slightly different and attempts to remove bias from the calculation of kurtosis based on a sample:
)
I’m inflicting these formulas on you so that if you need to contrast the reason that R returns different values for skewness and kurtosis than Excel, you’ll be better placed to understand the differences.
Confidence Level
The Descriptive Statistics tool’s results refer to the confidence interval value as the Confidence Level (see cell E18 in Figure 2.1). That’s a misnomer. The confidence level is the percentage of sample confidence intervals that you expect to capture the population mean: typically, 90%, 95%, or 99%.
In contrast, the Descriptive Statistics tool reports the quantity that you add to and subtract from the calculated mean so as to arrive at the confidence interval. That quantity is calculated, using Excel function syntax, as
=T.INV.2T(0.05,10)*F4
where cell F4 contains the standard error of the mean. Excel’s T.INV.2T( ) worksheet function returns the positive t value that cuts off some percentage of the area under the t-distribution, such that the remaining percentage is divided evenly between the two tails. So, this use of the function
=T.INV.2T(.05,10)
returns 2.23. That means
Take a t-distribution, which is very similar to a normal curve but is a little flatter in its center and a little thicker in its tails. Its shape depends partly on the number of observations in the samples used to build the distribution. In this example, the number of observations is 11 and therefore the degrees of freedom is 10.
The mean of that t-distribution is 0. If you cut the distribution at two points, −2.23 and +2.23, you’ll find that 95% of the area under the curve is between those two cuts.
And of course, 5% is outside the cuts, with 2.5% in the distribution’s right tail and 2.5% in its left tail.
But we’re not working in a scale of t values, which has a standard deviation that’s slightly larger than 1.
NOTE
The standard deviation of the t-distribution is given by this formula:
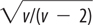
where v is the degrees of freedom. So in a t-distribution built on samples of size 5, the degrees of freedom is 4 and the standard deviation is the square root of (4/2), or 1.414. As the sample size increases the standard deviation decreases, so a t-distribution built on samples of size 11 has a standard deviation of 1.12.
Instead, we’re working with a scale that in Figure 2.1 describes whatever MPG is, with a standard error of 2.63. So, to cut off 2.5% of the distribution at each tail, we multiply ±2.23 by 2.63 or ±5.86. Adding ±5.86 to the mean of 26 shown in cell F4 of Figure 2.1 gives a 95% confidence interval of from 20.14 to 31.86. Another way of saying this is that we want to go up from the mean by 2.23 standard deviations. In this scale, a standard deviation is 2.63 units, so we go up from the mean by 2.23 × 2.63 units. We go down from the mean by the same amount. The resulting range of values is the 95% confidence interval for this data.
You interpret the confidence interval as follows: If you were to take 100 random samples, each from the same population, and put a 95% confidence interval around each of 100 sample means, 95 of those confidence intervals would capture the mean of the population. It is more rational to suppose that the one confidence interval that you did construct is one of the 95 that captures the population mean than one of the 5 that do not. That’s what’s meant by saying that a confidence interval makes you 95% confident that it captures the true population mean.
Using the Excel Descriptive Statistics Tool on R’s Pizza File
Let’s take a look at what Excel’s Descriptive Statistics tool has to say about the numeric variables in R’s pizza delivery database. The first step is to export that database so it’s available to Excel. To arrange that, take these steps:
Start R.
Load the DescTools package using this R command:
Export the data frame named d.pizza by entering this command:
library(DescTools)
write.csv(d.pizza, file=“C:/Users/Jean/Desktop/pizza.csv”)
You can use any legitimate destination name and location for the file. It will be formatted as a comma-separated values file, or csv file, so you might as well use csv as the filename extension. Also notice the use of forward slash (/) rather than backslashes (\) in the file path: R interprets a backslash as an escape character. You can instead use the forward slash (/) or two consecutive backslashes (\\).
When control returns to the R interface—it only takes a second or two—quit R and start Excel. Open the csv file from the location where you stored it. It looks something like the worksheet shown in Figure 2.4.
)
Figure 2.4 A csv file that’s opened in Excel has none of the frills such as currency formats that we’re used to seeing in Excel workbooks.
In Figure 2.4, notice the NA values sprinkled among the legitimate values. The NA values mean not available and, because they’re text, the Descriptive Statistics tool has difficulty dealing with them when they’re supposed to be numbers.
If you want to use Excel’s worksheet functions, you’re in the clear. When a function such as SUM( ) or AVERAGE( ) or STDEV.S( ) encounters a text value such as NA, it simply ignores it. See Figure 2.5 for some examples.
)
Figure 2.5 Excel ignores records on a pairwise basis for correlation functions such as CORREL( ).
The first ten records in the Pizza database from DescTools appear in cells A2:A11 of Figure 2.5, where the delivery temperature is recorded. This formula is entered in cell A13:
=AVERAGE(A2:A11)
Notice that the formula’s argument includes the text value NA in cell A5. The formula returns the result 46.00.
This formula is entered in cell A16:
=AVERAGE(A2,A3,A4,A6,A7,A8,A9,A10,A11)
The second AVERAGE formula includes every cell in A2:A11 except A5. Both AVERAGE( ) formulas return the same result, 46.00, and you can depend on Excel worksheet functions such as AVERAGE( ) and SUM( ) to ignore text values such as NA when they expect numeric values.
Still in Figure 2.5, the range D2:E11 contains the same records as A2:A11, but both the temperature and the minutes to delivery appear. If you want to calculate the correlation between those two variables on the basis of those records, Excel manages the missing data by ignoring the entire fourth record because it has a missing value for one of the variables. Notice the correlation between the values in D2:D11 and E2:E11, and −0.7449. That value is returned by this formula:
=CORREL(D2:D11,E2:E11)
In the range G2:H10 I have omitted the record with one missing value. The formula that calculates the correlation for that range of data is
=CORREL(G2:G10,H2:H10)
Both formulas return the same result, so the CORREL( ) function ignores the full record when either of the values is text.
Therefore, you’re in good shape if you decide to get the summary statistics from a data set such as the Pizza database using worksheet functions. Things aren’t as straightforward if you decide you want to use the Descriptive Statistics tool in Excel’s Data Analysis add-in.
If you point the Descriptive Statistics tool at a worksheet range that contains text data, it returns an error message to the effect that the range contains text data. See Figure 2.6.
)
Figure 2.6 Although all the worksheet functions operate smoothly with text values, the Descriptive Statistics tool doesn’t.
To get the Descriptive Statistics tool to process the data, you have to replace the text data with something else. Obviously, you can’t just make up numbers and enter them in place of the NA values. As it turns out, though, the Descriptive Statistics tool can manage if you replace the text values with empty cells.
So, one possibility is to do a global replace of the NA values with nothing—that is, in the Find and Replace dialog box, enter NA in the Find What box and enter nothing in the Replace With edit box. Excel treats a truly empty cell as missing data, and functions such as AVERAGE( ) and SUM( ) return the correct summary values for those cells that contain numeric values.
Unfortunately, with a data set as full of NA values as R’s Pizza data set, those replacement empty cells cause another problem. With as many as 1209 records in the worksheet, you’re apt to want to select a variable for analysis by clicking its label (for example, cell M1 in Figure 2.4), then holding down the Ctrl key and pressing the down arrow. This sequence selects all the cells from the active one to the final contiguous non-empty cell below the one that’s active.
But that probably just takes you partway through the data set—perhaps even just 10 records. As soon as you replace an NA value, making (say) M5 an empty cell, your search for the actual final value in the column ends at M4.
An acceptable workaround is to select the entire column by clicking its column header to enter, for example, M:M in the Input Range box (see Figure 2.3). This slows processing down just a bit, but it’s better than hitting the down arrow once for every blank cell in the data’s column.
Another possibility is to use a worksheet function that is designed to handle text values in an otherwise numeric field. AVERAGEA( ) treats text values as legitimate zero values, however, and in averages there’s a difference between a missing value and a zero value. That is, this formula:
=AVERAGEA(1,2,“NA,“4,5)
returns 2.4. Treating NA as a zero value means that the sum is 12 and the count is 5, so the result is 2.4. It’s likely that the result you’re after completely ignores the NA value, so the sum would still be 12 but the count would be 4, and the result would be 3.
There’s no entirely satisfactory solution to these problems in Excel. You could define names based on the top row of the selection, and use a defined name instead of a worksheet address in the Input Range edit box. But Excel does not include the column headers as part of a range that’s named using that method, and so Descriptive Statistics cannot show the variable’s label as part of its results. If only from the standpoint of convenience, then, R is probably the better bet than Excel in this sort of situation.