OSPF Implementation
- Establishing OSPF Neighbor Relationships
- Building the Link-State Database
- Optimizing OSPF Behavior
- OSPFv3
- Summary
- Review Questions
This chapter is from the book
This chapter is from the book
This chapter is from the book
This chapter covers the following topics:
- Basic OSPF Configuration and OSPF Adjacencies
- How OSPF Builds the Routing Table
- Configuration of Summarization and Stub Areas in OSPF
- Configuration of OSPFv3 for IPv6 and IPv4
This chapter examines the Open Shortest Path First (OSPF) Protocol, one of the most commonly used interior gateway protocols in IP networking. OSPFv2 is an open-standard protocol that provides routing for IPv4. OSPFv3 offers some enhancements for IP Version 6 (IPv6). OSPF is a complex protocol that is made up of several protocol handshakes, database advertisements, and packet types.
OSPF is an interior gateway routing protocol that uses link-states rather than distance vectors for path selection. OSPF propagates link-state advertisements (LSAs) rather than routing table updates. Because only LSAs are exchanged instead of the entire routing tables, OSPF networks converge in a timely manner.
OSPF uses a link-state algorithm to build and calculate the shortest path to all known destinations. Each router in an OSPF area contains an identical link-state database, which is a list of each of the router-usable interfaces and reachable neighbors.
Establishing OSPF Neighbor Relationships
OSPF is a link-state protocol based on the open standard. At a high level, OSPF operation consists of three main elements: neighbor discovery, link-state information exchange, and best-path calculation.
To calculate the best path, OSPF uses the shortest path first (SPF) or Dijkstra’s algorithm. The input information for SPF calculation is link-state information, which is exchanged between routers using several different OSPF message types. These message types help improve convergence and scalability in multi-area OSPF deployments.
OSPF also supports several different network types, which enables you to configure OSPF over a variety of different underlying network technologies.
Upon completion of this section, you will be able to describe the main operational characteristics of the OSPF protocol and configure its basic features. You will also be able to meet following objectives:
- Explain why would you choose OSPF over other routing protocols
- Describe basic operation steps with link-state protocols
- Describe area and router types in OSPF
- Explain what the design limitations of OSPF are
- List and describe OSPF message types
- Describe OSPF neighbor relationship over point-to-point link
- Describe OSPF neighbor relationship behavior on MPLS VPN
- Describe OSPF neighbor relationship behavior over L2 MPLS VPN
- List and describe OSPF neighbor states
- List and describe OSPF network types
- Configure passive interfaces
OSPF Features
OSPF was developed by the Internet Engineering Task Force (IETF) to overcome the limitations of distance vector routing protocols. One of the main reasons why OSPF is largely deployed in today’s enterprise networks is the fact that it is an open standard; OSPF is not proprietary. Version 1 of the protocol is described in the RFC 1131. The current version used for IPv4, Version 2, is specified in RFCs 1247 and 2328. OSPF Version 3, which is used in IPv6 networks, is specified in RFC 5340.
OSPF offers a large level of scalability and fast convergence. Despite its relatively simple configuration in small and medium-size networks, OSPF implementation and troubleshooting in large-scale networks can at times be challenging.
The key features of the OSPF protocol are as follows:
- Independent transport: OSPF works on top of IP and uses protocol number 89. It does not rely on the functions of the transport layer protocols TCP or UDP.
- Efficient use of updates: When an OSPF router first discovers a new neighbor, it sends a full update with all known link-state information. All routers within an OSPF area must have identical and synchronized link-state information in their OSPF link-state databases. When an OSPF network is in a converged state and a new link comes up or a link becomes unavailable, an OSPF router sends only a partial update to all its neighbors. This update will then be flooded to all OSPF routers within an area.
- Metric: OSPF uses a metric that is based on the cumulative costs of all outgoing interfaces from source to destination. The interface cost is inversely proportional to the interface bandwidth and can be also set up explicitly.
- Update destination address: OSPF uses multicast and unicast, rather than broadcast, for sending messages. The IPv4 multicast addresses used for OSPF are 224.0.0.5 to send information to all OSPF routers and 224.0.0.6 to send information to DR/BDR routers. The IPv6 multicast addresses are FF02::5 for all OSPFv3 routers and FF02::6 for all DR/BDR routers. If the underlying network does not have broadcast capabilities, you must establish OSPF neighbor relationships using a unicast address. For IPv6, this address will be a link-local IPv6 address.
- VLSM support: OSPF is a classless routing protocol. It supports variable-length subnet masking (VLSM) and discontiguous networks. It carries subnet mask information in the routing updates.
- Manual route summarization: You can manually summarize OSPF interarea routes at the Area Border Router (ABR), and you have the possibility to summarize OSPF external routes at the Autonomous System Boundary Router (ASBR). OSPF does not know the concept of autosummarization.
- Authentication: OSPF supports clear-text, MD5, and SHA authentication.
OSPF Operation Overview
To create and maintain routing information, OSPF routers complete the following generic link-state routing process, shown in Figure 3-1, to reach a state of convergence:
- Establish neighbor adjacencies: OSPF-enabled routers must form adjacencies with their neighbor before they can share information with that neighbor. An OSPF-enabled router sends Hello packets out all OSPF-enabled interfaces to determine whether neighbors are present on those links. If a neighbor is present, the OSPF-enabled router attempts to establish a neighbor adjacency with that neighbor.
- Exchange link-state advertisements: After adjacencies are established, routers then exchange link-state advertisements (LSAs). LSAs contain the state and cost of each directly connected link. Routers flood their LSAs to adjacent neighbors. Adjacent neighbors receiving the LSA immediately flood the LSA to other directly connected neighbors, until all routers in the area have all LSAs.
- Build the topology table: After the LSAs are received, OSPF-enabled routers build the topology table (LSDB) based on the received LSAs. This database eventually holds all the information about the topology of the network. It is important that all routers in the area have the same information in their LSDBs.
- Execute the SPF algorithm: Routers then execute the SPF algorithm. The SPF algorithm creates the SPF tree.
Build the routing table: From the SPF tree, the best paths are inserted into the routing table. Routing decisions are made based on the entries in the routing table.
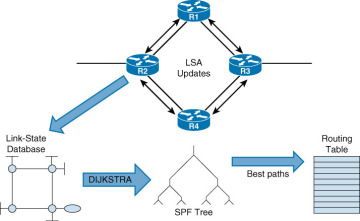
Figure 3-1 OSPF Operation
)
Hierarchical Structure of OSPF
If you run OSPF in a simple network, the number of routers and links are relatively small, and best paths to all destinations are easily deduced. However, the information necessary to describe larger networks with many routers and links can become quite complex. SPF calculations that compare all possible paths for routes can easily turn into a complex and time-consuming calculation for the router.
One of the main methods to reduce this complexity and the size of the link-state information database is to partition the OSPF routing domain into smaller units called areas, shown in Figure 3-2. This also reduces the time it takes for the SPF algorithm to execute. All OSPF routers within an area must have identical entries within their respective LSDBs. Inside an area, routers exchange detailed link-state information. However, information transmitted from one area into another contains only summary details of the LSDB entries and not topology details about the originating area. These summary LSAs from another area are injected directly into the routing table and without making the router rerun its SPF algorithm.
)
Figure 3-2 OSPF Hierarchy
OSPF uses a two-layer area hierarchy:
- Backbone area, transit area or area 0: Two principal requirements for the backbone area are that it must connect to all other nonbackbone areas and this area must be always contiguous; it is not allowed to have split up the backbone area. Generally, end users are not found within a backbone area.
- Nonbackbone area: The primary function of this area is to connect end users and resources. Nonbackbone areas are usually set up according to functional or geographic groupings. Traffic between different nonbackbone areas must always pass through the backbone area.
In the multi-area topology there are some special commonly used OSPF terms:
- ABR: A router that has interfaces connected to at least two different OSPF areas, including the backbone area. ABRs contain LSDB information for each area, make route calculation for each area and advertise routing information between areas.
- ASBR: ASBR is a router that has at least one of its interfaces connected to an OSPF area and at least one of its interfaces connected to an external non-OSPF domain.
- Internal router: A router that has all its interfaces connected to only one OSPF area. This router is completely internal to this area.
- Backbone router: A router that has at least one interface connected to the backbone area.
The optimal number of routers per area varies based on factors such as network stability, but in general it is recommended to have no more than 50 routers per single area.
Design Restrictions of OSPF
OSPF has special restrictions when multiple areas are configured in an OSPF routing domain or AS, as shown in Figure 3-3. If more than one area is configured, known as multi-area OSPF, one of these areas must be area 0. This is called the backbone area. When designing networks or starting with a single area, it is good practice to start with the core layer, which becomes area 0, and then expand into other areas later.
)
Figure 3-3 Multi-Area OSPF
The backbone has to be at the center of all other areas, and other areas have to be connected to the backbone. The main reason is that OSPF expects all areas to inject routing information into the backbone area, which distributes that information into other areas.
Another important requirement for the backbone area is that it must be contiguous. In other words, splitting up area 0 is not allowed.
However, in some cases, these two conditions cannot be met. Later in this chapter in the section, “OSPF Virtual Links,” you will learn about the use of virtual links as a solution.
OSPF Message Types
OSPF uses five types of routing protocol packets, which share a common protocol header. Every OSPF packet is directly encapsulated in the IP header. The IP protocol number for OSPF is 89.
- Type 1: Hello packet: Hello packets are used to discover, build, and maintain OSPF neighbor adjacencies. To establish adjacency, OSPF peers at both sides of the link must agree on some parameters contained in the Hello packet to become OSPF neighbors.
- Type 2: Database Description (DBD) packet: When the OSPF neighbor adjacency is already established, a DBD packet is used to describe LSDB so that routers can compare whether databases are in sync.
- Type 3: Link-State Request (LSR) packet: When the database synchronization process is over, the router might still have a list of LSAs that are missing in its database. The router will send an LSR packet to inform OSPF neighbors to send the most recent version of the missing LSAs.
- Type 4: Link-State Update (LSU) packet: There are several types of LSUs, known as LSAs. LSU packets are used for the flooding of LSAs and sending LSA responses to LSR packets. It is sent only to the directly connected neighbors who have previously requested LSAs in the form of LSR packet. In case of flooding, neighbor routers are responsible for re-encapsulation of received LSA information in new LSU packets.
- Type 5: Link-State Acknowledgment (LSAck) packet: LSAcks are used to make flooding of LSAs reliable. Each LSA received must be explicitly acknowledged. Multiple LSAs can be acknowledged in a single LSAck packet.
Basic OSPF Configuration
This section explores how to configure and establish OSPF neighbor relationship. You will observe the impact of the interface MTU and OSPF hello/dead timer parameters on the OSPF neighbor relationship formation. In addition, you will learn what the roles are of the DR/BDR routers and how to control the DR/BDR election process.
The topology in Figure 3-4 shows five routers, R1 to R5. R1, R4, and R5 are already pre-configured, while R2 and R3 will be configured in this section.
)
Figure 3-4 Topology for Basic OSPF Configuration
R1, R4, and R5 are connected to common multiaccess Ethernet segment. R1 and R2 are connected over serial Frame Relay interface, and R1 and R3 are also connected over Ethernet link.
Example 3-1 begins the configuration of OSPF on WAN and LAN interfaces on R2 and R3. Use the process numbers 2 and 3 on R2 and R3, respectively.
Example 3-1 Configuration OSPF on R2 and R3
R2# configure terminal Enter configuration commands, one per line. End with CNTL/Z. R2(config)# router ospf 2 R2(config-router)# network 172.16.12.0 0.0.0.3 area 1 R2(config-router)# network 192.168.2.0 0.0.0.255 area 1
R3# configure terminal Enter configuration commands, one per line. End with CNTL/Z. R3(config)# router ospf 3 R3(config-router)# network 172.16.13.0 0.0.0.3 area 2 R3(config-router)# network 192.168.3.0 0.0.0.255 area 2
To enable the OSPF process on the router, use the router ospf process-id command. Process ID numbers between neighbors do not need to match for the routers to establish an OSPF adjacency. The OSPF process number ID is an internally used identification parameter for an OSPF routing process and only has local significance. However, it is good practice to make the process ID number the same on all routers. If necessary, you can specify multiple OSPF routing processes on a router, but you need to know the implications of doing so. Multiple OSPF processes on the same router is not common and beyond the scope of this book.
To define which interfaces will run the OSPF process and to define the area ID for those interfaces, use network ip-address wildcard-mask area area-id command. A combination of ip-address and wildcard-mask together allows you to define one or multiple interfaces to be associated with a specific OSPF area using a single command.
Cisco IOS Software sequentially evaluates the ip-address wildcard-mask pair specified in the network command for each interface as follows:
- It performs a logical OR operation between a wildcard-mask argument and the interface’s primary IP address.
- It performs a logical OR operation between a wildcard-mask argument and the ip-address argument in the network command.
- The software compares the two resulting values. If they match, OSPF is enabled on the associated interface, and this interface is attached to the OSPF area specified.
This area ID is a 32-bit number that may be represented in integer or dotted-decimal format. When represented in dotted-decimal format, the area ID does not represent an IP address; it is only a way of writing an integer value in dotted-decimal format. For example, you may specify that an interface belongs to area 1 using area 1 or area 0.0.0.1 notation in the network command. To establish OSPF full adjacency, two neighbor routers must be in the same area. Any individual interface can only be attached to a single area. If the address ranges specified for different areas overlap, IOS will adopt the first area in the network command list and ignore subsequent overlapping portions. To avoid conflicts, you must pay special attention to ensure that address ranges do not overlap.
In Example 3-2, the OSPF router IDs of R2 and R3 are configured using the router-id command.
Example 3-2 Configuration of OSPF Router IDs
R2(config-router)# router-id 2.2.2.2 % OSPF: Reload or use "clear ip ospf process" command, for this to take effect
R3(config-router)# router-id 3.3.3.3 % OSPF: Reload or use "clear ip ospf process" command, for this to take effect
The OSPF router ID is a fundamental parameter for the OSPF process. For the OSPF process to start, Cisco IOS must be able to identify a unique OSPF router ID. Similar to EIGRP, the OSPF router ID is a 32-bit value expressed as an IPv4 address. At least one primary IPv4 address on an interface in the up/up state must be configured for a router to be able to choose router ID; otherwise, an error message is logged, and the OSPF process does not start.
To choose the OSPF router ID at the time of OSPF process initialization, the router uses the following criteria:
- Use the router ID specified in the router-id ip-address command. You can configure an arbitrary value in the IPv4 address format, but this value must be unique. If the IPv4 address specified with the router-id command overlaps with the router ID of another already-active OSPF process, the router-id command fails.
- Use the highest IPv4 address of all active loopback interfaces on the router.
- Use the highest IPv4 address among all active nonloopback interfaces.
After the three-step OSPF router ID selection process has finished, and if the router is still unable to select an OSPF router ID, an error message will be logged. An OSPF process that failed to select a router ID retries the selection process every time an IPv4 address becomes available. (An applicable interface changes its state to up/up or an IPv4 address is configured on an applicable interface.)
In Example 3-3, the OSPF routing process is cleared on R2 and R3 for the manually configured router ID to take effect.
Example 3-3 Clearing the OSPF Processes on R2 and R3
R2# clear ip ospf process Reset ALL OSPF processes? [no]: yes R2# *Nov 24 08:37:24.679: %OSPF-5-ADJCHG: Process 2, Nbr 1.1.1.1 on Serial0/0 from FULL to DOWN, Neighbor Down: Interface down or detached R2# *Nov 24 08:39:24.734: %OSPF-5-ADJCHG: Process 2, Nbr 1.1.1.1 on Serial0/0 from LOADING to FULL, Loading Done
R3# clear ip ospf 3 process Reset OSPF process 3? [no]: yes R3# *Nov 24 09:06:00.275: %OSPF-5-ADJCHG: Process 3, Nbr 1.1.1.1 on Ethernet0/0 from FULL to DOWN, Neighbor Down: Interface down or detached R3# *Nov 24 09:06:40.284: %OSPF-5-ADJCHG: Process 3, Nbr 1.1.1.1 on Ethernet0/0 from LOADING to FULL, Loading Done
Once an OSPF router ID is selected, it is not changed even if the interface that is used to select it changed its operational state or its IP address. To change the OSPF router ID, you must reset the OSPF process with the clear ip ospf process command or reload the router.
In production networks, the OSPF router ID cannot be changed easily. Changing the OSPF router ID requires reset of all OSPF adjacencies, resulting in a temporary routing outage. The router also has to originate new copies of all originating LSAs with the new router ID.
You can either clear the specific OSPF process by specifying the process ID, or you can reset all OSPF processes by using the clear ip ospf process command.
The newly configured OSPF router ID is verified on R2 and R3 using show ip protocols commands in Example 3-4. Large output of this command can optionally be filtered using the pipe function, also shown in Example 3-4.
Example 3-4 Verifying the Router IDs on R2 and R3
R2# show ip protocols *** IP Routing is NSF aware *** Routing Protocol is "ospf 2" Outgoing update filter list for all interfaces is not set Incoming update filter list for all interfaces is not setRouter ID 2.2.2.2Number of areas in this router is 1. 1 normal 0 stub 0 nssa Maximum path: 4 Routing for Networks: 172.16.12.0 0.0.0.3 area 1 192.168.2.0 0.0.0.255 area 1 Routing Information Sources: Gateway Distance Last Update 1.1.1.1 110 00:02:55 Distance: (default is 110) R3# show ip protocols | include IDRouter ID 3.3.3.3
The OSPF neighborship on R2 and R3 is verified in Example 3-5 using the show ip ospf neighbor command.
Example 3-5 Verifying OSPF Neighborships on R2 and R2
R2# show ip ospf neighbor
Neighbor ID Pri State Dead Time Address Interface
1.1.1.1 1 FULL/DR 00:01:57 172.16.12.1 Serial0/0
R3# show ip ospf neighbor
Neighbor ID Pri State Dead Time Address Interface
1.1.1.1 1 FULL/DR 00:00:39 172.16.13.1 Ethernet0/0
The command show ip ospf neighbor displays OSPF neighbor information on a per-interface basis. The significant fields of the outputs are as follows:
- Neighbor ID: Represents neighbor router ID.
- Priority: Priority on the neighbor interface used for the DR/BDR election.
- State: A Full state represents the final stage of OSPF neighbor establishment process and denotes that the local router has established full neighbor adjacency with the remote OSPF neighbor. DR means that DR/BDR election process has been completed and that the remote router with the router ID 1.1.1.1 has been elected as the designated router (DR).
- Dead Time: Represents value of the dead timer. When this timer expires, the router terminates the neighbor relationship. Each time a router receives an OSPF Hello packet from a specific neighbor, it resets the dead timer back to its full value.
- Address: Primary IPv4 address of the neighbor router.
- Interface: Local interface over which an OSPF neighbor relationship is established.
Example 3-6 verifies the OSPF-enabled interfaces on R2 and R3 using the show ip ospf interface command.
Example 3-6 Verifying the OSPF-Enabled Interfaces on R2 and R3
R2# show ip ospf interfaceLoopback0 is up, line protocol is upInternet Address 192.168.2.1/24,Area 1, Attached via Network StatementProcess ID 2, Router ID 2.2.2.2,Network Type LOOPBACK, Cost: 1<Output omitted>Serial0/0 is up, line protocol is upInternet Address 172.16.12.2/30,Area 1, Attached via Network StatementProcess ID 2, Router ID 2.2.2.2,Network Type NON_BROADCAST, Cost: 64<Output omitted>
R3# show ip ospf interfaceLoopback0 is up, line protocol is upInternet Address 192.168.3.1/24,Area 2, Attached via Network StatementProcess ID 3, Router ID 3.3.3.3,Network Type LOOPBACK, Cost: 1<Output omitted>Ethernet0/0 is up, line protocol is up Internet Address 172.16.13.2/30,Area 2, Attached via Network StatementProcess ID3, Router ID 3.3.3.3,Network Type BROADCAST, Cost: 10<Output omitted>
Output of the show ip ospf interface command shows you all interfaces enabled in the OSPF process. For each enabled interface, you can see detailed information such as OSPF area ID, OSPF process ID, and how the interface was included into the OSPF process. In the output, you can see that both interfaces on both routers were included via the network statement, configured with the network command.
In Example 3-7, the OSPF routes are verified in the routing table on R5 using the show ip route ospf command.
Example 3-7 Verifying the OSPF Routes on R5
R5# show ip route ospf
Codes: L - local, C - connected, S - static, R - RIP, M - mobile, B - BGP
D - EIGRP, EX - EIGRP external, O - OSPF, IA - OSPF inter area
N1 - OSPF NSSA external type 1, N2 - OSPF NSSA external type 2
E1 - OSPF external type 1, E2 - OSPF external type 2
i - IS-IS, su - IS-IS summary, L1 - IS-IS level-1, L2 - IS-IS level-2
ia - IS-IS inter area, * - candidate default, U - per-user static route
o - ODR, P - periodic downloaded static route, H - NHRP, l - LISP
+ - replicated route, % - next hop override
Gateway of last resort is not set
172.16.0.0/16 is variably subnetted, 4 subnets, 3 masks
O IA 172.16.12.0/30 [110/74] via 172.16.145.1, 00:39:00, Ethernet0/0
O IA 172.16.13.0/30 [110/20] via 172.16.145.1, 00:19:29, Ethernet0/0
192.168.2.0/32 is subnetted, 1 subnets
O IA 192.168.2.1 [110/75] via 172.16.145.1, 00:07:27, Ethernet0/0
192.168.3.0/32 is subnetted, 1 subnets
O IA 192.168.3.1 [110/21] via 172.16.145.1, 00:08:30, Ethernet0/0
O 192.168.4.0/24 [110/11] via 172.16.145.4, 00:39:10, Ethernet0/0
Among the routes originated within the OSPF autonomous system, OSPF clearly distinguishes two types of routes: intra-area routes and interarea routes. Intra-area routes are routes that are originated and learned in the same local area. Code for the intra-area routes in the routing table is O. The second type is interarea routes, which originate in other areas and are inserted into the local area to which your router belongs. Code for the interarea routes in the routing table is O IA. Interarea routes are inserted into other areas on the ABR.
The prefix 192.168.4.0/24 is an example of intra-area route from the R5 perspective. It originated from router R4, which is part of the area 0, the same area as R5.
Prefixes from R2 and R3, which are part of area 1 and area 2, are shown in the routing table on R5 as interarea routes. Prefixes were inserted into area 0 as interarea routes by R1, which plays the role of ABR.
Prefixes 192.168.2.0/24 and 192.168.3.0/24 configured on the loopback interfaces of R2 and R3 are displayed in the R5 routing table as host routes 192.168.2.1/32 and 192.168.3.1/32. By default, OSPF will advertise any subnet configured on the loopback interface as /32 host route. To change this default behavior, you can optionally change OSPF network type on the loopback interface from the default loopback to point-to-point using the ip ospf network point-to-point interface command.
OSPF database routes on R5 are observed in Example 3-8 using the show ip ospf route command.
Example 3-8 OSPF Routes on R5
R5# show ip ospf route
OSPF Router with ID (5.5.5.5) (Process ID 1)
Base Topology (MTID 0)
Area BACKBONE(0)
Intra-area Route List
* 172.16.145.0/29, Intra, cost 10, area 0, Connected
via 172.16.145.5, Ethernet0/0
*> 192.168.4.0/24, Intra, cost 11, area 0
via 172.16.145.4, Ethernet0/0
Intra-area Router Path List
i 1.1.1.1 [10] via 172.16.145.1, Ethernet0/0, ABR, Area 0, SPF 2
Inter-area Route List
*> 192.168.2.1/32, Inter, cost 75, area 0
via 172.16.145.1, Ethernet0/0
*> 192.168.3.1/32, Inter, cost 21, area 0
via 172.16.145.1, Ethernet0/0
*> 172.16.12.0/30, Inter, cost 74, area 0
via 172.16.145.1, Ethernet0/0
*> 172.16.13.0/30, Inter, cost 20, area 0
via 172.16.145.1, Ethernet0/0
The show ip ospf route command clearly separates the lists of intra-area and interarea routes. In addition, output of the command displays essential information about ABRs, including the router ID, IPv4 address in the current area, interface that advertises routes into the area, and the area ID.
For interarea routes, the metric for the route (cost), the area into which the route is distributed, and the interface over which the route is inserted are displayed.
In Example 3-9, the OSPF neighbor adjacency and the associated OSPF packet types on R3 are observed using the debug ip ospf adj and clear ip ospf process commands. Disable debug when the OSPF session is reestablished.
Example 3-9 Observing Formation of OSPF Neighbor Adjacencies
R3# debug ip ospf adj OSPF adjacency debugging is on R3# clear ip ospf process Reset ALL OSPF processes? [no]: yes *Jan 17 13:02:37.394: OSPF-3 ADJ Lo0: Interface going Down *Jan 17 13:02:37.394: OSPF-3 ADJ Lo0: 3.3.3.3 address 192.168.3.1 is dead, state DOWN *Jan 17 13:02:37.394: OSPF-3 ADJ Et0/0: Interface going Down *Jan 17 13:02:37.394: OSPF-3 ADJ Et0/0: 1.1.1.1 address 172.16.13.1 is dead, state DOWN *Jan 17 13:02:37.394: %OSPF-5-ADJCHG: Process 3, Nbr 1.1.1.1 on Ethernet0/0 from FULL to DOWN, Neighbor Down: Interface down or detached <Output omitted> *Jan 17 13:02:37.394: OSPF-3 ADJ Lo0: Interface going Up *Jan 17 13:02:37.394: OSPF-3 ADJ Et0/0: Interface going Up *Jan 17 13:02:37.395: OSPF-3 ADJEt0/0: 2 Way Communication to 1.1.1.1, state 2WAY*Jan 17 13:02:37.396: OSPF-3 ADJ Et0/0: Backup seen event before WAIT timer *Jan 17 13:02:37.396: OSPF-3 ADJEt0/0: DR/BDR election*Jan 17 13:02:37.396: OSPF-3 ADJ Et0/0: Elect BDR 3.3.3.3 *Jan 17 13:02:37.396: OSPF-3 ADJ Et0/0: Elect DR 1.1.1.1 *Jan 17 13:02:37.396: OSPF-3 ADJ Et0/0: Elect BDR 3.3.3.3 *Jan 17 13:02:37.396: OSPF-3 ADJ Et0/0: Elect DR 1.1.1.1 *Jan 17 13:02:37.396: OSPF-3 ADJEt0/0: DR: 1.1.1.1 (Id) BDR: 3.3.3.3 (Id)*Jan 17 13:02:37.396: OSPF-3 ADJ Et0/0: Nbr 1.1.1.1: Prepare dbase exchange *Jan 17 13:02:37.396: OSPF-3 ADJ Et0/0:Send DBD to 1.1.1.1seq 0x95D opt 0x52 flag 0x7 len 32 *Jan 17 13:02:37.397: OSPF-3 ADJ Et0/0:Rcv DBD from 1.1.1.1seq 0x691 opt 0x52 flag 0x7 len 32 mtu 1500state EXSTART*Jan 17 13:02:37.397: OSPF-3 ADJ Et0/0:First DBD and we are not SLAVE*Jan 17 13:02:37.397: OSPF-3 ADJ Et0/0:Rcv DBD from 1.1.1.1seq 0x95D opt 0x52 flag 0x2 len 152 mtu 1500state EXSTART*Jan 17 13:02:37.397: OSPF-3 ADJ Et0/0:NBR Negotiation Done. We are the MASTER*Jan 17 13:02:37.397: OSPF-3 ADJ Et0/0: Nbr 1.1.1.1:Summary list built, size 0 *Jan 17 13:02:37.397: OSPF-3 ADJ Et0/0:Send DBDto 1.1.1.1 seq 0x95E opt 0x52 flag 0x1 len 32 *Jan 17 13:02:37.398: OSPF-3 ADJ Et0/0:Rcv DBDfrom 1.1.1.1 seq 0x95E opt 0x52 flag 0x0 len 32 mtu 1500state EXCHANGE*Jan 17 13:02:37.398: OSPF-3 ADJ Et0/0: Exchange Done with 1.1.1.1 *Jan 17 13:02:37.398: OSPF-3 ADJ Et0/0:Send LS REQto 1.1.1.1 length 96 LSA count 6 *Jan 17 13:02:37.399: OSPF-3 ADJ Et0/0:Rcv LS UPDfrom 1.1.1.1 length 208 LSA count 6 *Jan 17 13:02:37.399: OSPF-3 ADJ Et0/0:Synchronized with 1.1.1.1, state FULL*Jan 17 13:02:37.399:%OSPF-5-ADJCHG: Process 3, Nbr 1.1.1.1 on Ethernet0/0 fromLOADING to FULL, Loading DoneR3# undebug all
An OSPF adjacency is established in several steps. In the first step, routers that intend to establish full OSPF neighbor adjacency exchange OSPF Hello packets. Both OSPF neighbors are in the Down state, the initial state of a neighbor conversation that indicates that no Hello’s have been heard from the neighbor. When a router receives a Hello from the neighbor but has not yet seen its own router ID in the neighbor Hello packet, it will transit to the Init state. In this state, the router will record all neighbor router IDs and start including them in Hellos sent to the neighbors. When the router sees its own router ID in the Hello packet received from the neighbor, it will transit to the 2-Way state. This means that bidirectional communication with the neighbor has been established.
On broadcast links, OSPF neighbors first determine the designated router (DR) and backup designated router (BDR) roles, which optimize the exchange of information in broadcast segments.
In the next step, routers start to exchange content of OSPF databases. The first phase of this process is to determine master/slave relationship and choose the initial sequence number for adjacency formation. To accomplish this, routers exchange DBD packets. When the router receives the initial DBD packet it transitions the state of the neighbor from which this packet is received to ExStart state, populates its Database Summary list with the LSAs that describe content of the neighbor’s database, and sends its own empty DBD packet. In the DBD exchange process, the router with the higher router ID will become master, and it will be the only router that can increment sequence numbers.
With master/slave selection complete, database exchange can start. R3 will transit R1’s neighbor state to Exchange. In this state, R3 describes its database to the R1 by sending DBD packets that contain the headers of all LSAs in the Database Summary list. The Database Summary list describes all LSAs in the router’s database, but not the full content of the OSPF database. To describe the content of the database, one or multiple DBD packets may be exchanged. A router compares the content of its own Database Summary list with the list received from the neighbor, and if there are differences, it adds missing LSAs to the Link State Request list. At this point, routers enter the Loading state. R3 sends an LSR packet to the neighbor requesting full content of the missing LSAs from the LS Request list. R1 replies with the LSU packets, which contain full versions of the missing LSAs.
Finally, when neighbors have a complete version of the LSDB, both neighbors transit to the Full state, which means that databases on the routers are synchronized and that neighbors are fully adjacent.
Optimizing OSPF Adjacency Behavior
Multiaccess networks, either broadcast (such as Ethernet) or nonbroadcast (such as Frame Relay), represent interesting issues for OSPF. All routers sharing the common segment will be part of the same IP subnet. When forming adjacency on multiaccess network, every router will try to establish full OSPF adjacency with all other routers on the segment. This may not represent an issue for the smaller multiaccess broadcast networks, but it may represent an issue for the nonbroadcast multiaccess (NBMA) networks, where in most cases you do not have full-mesh private virtual circuit (PVC) topology. This issue in NBMA networks manifests in an inability for neighbors to synchronize their OSPF databases directly among themselves. A logical solution in this case is to have a central point of OSPF adjacency responsible for the database synchronization and advertisement of the segment to the other routers, as shown in Figure 3-5.
)
Figure 3-5 OSPF Adjacencies on Multiaccess Networks
As the number of routers on the segment grows, the number of OSPF adjacencies increases exponentially. Every router must synchronize its OSPF database with every other router, and in the case of a large number of routers, this leads to inefficiency. Another issue arises when every router on the segment advertises all its adjacencies to other routers in the network. If you have full-mesh OSPF adjacencies, remaining OSPF routers will receive a large amount of redundant link-state information. Again, the solution for this problem is to establish a central point with which every other router forms adjacency and which advertises the segment as a whole to the rest of the network.
The routers on the multiaccess segment elect a designated router (DR) and backup designated router (BDR), which centralizes communications for all routers connected to the segment. The DR and BDR improve network functioning in the following ways:
- Reducing routing update traffic: The DR and BDR act as a central point of contact for link-state information exchange on a multiaccess network; therefore, each router must establish a full adjacency with the DR and the BDR only. Each router, rather than exchanging link-state information with every other router on the segment, sends the link-state information to the DR and BDR only, by using a dedicated IPv4 multicast address 224.0.0.6 or FF00::6 for IPv6. The DR represents the multiaccess network in the sense that it sends link-state information from each router to all other routers in the network. This flooding process significantly reduces the router-related traffic on the segment.
- Managing link-state synchronization: The DR and BDR ensure that the other routers on the network have the same link-state information about the common segment. In this way, the DR and BDR reduce the number of routing errors.
Only LSAs are sent to the DR/BDR. The normal routing of packets on the segment will go to the best next-hop router.
When the DR is operating, the BDR does not perform any DR functions. Instead, the BDR receives all the information, but the DR performs the LSA forwarding and LSDB synchronization tasks. The BDR performs the DR tasks only if the DR fails. When the DR fails, the BDR automatically becomes the new DR, and a new BDR election occurs.
In Example 3-10, the DR/BDR status on R1, R4, and R5 are observed using the show ip ospf neighbor command. Routers R1, R4, and R5 are all connected to the same shared network segment, where OSPF will automatically attempts to optimize adjacencies.
Example 3-10 Neighbor Status of R1, R4, and R5
R1# show ip ospf neighbor Neighbor ID Pri State Dead Time Address Interface 4.4.4.4 1FULL/BDR00:00:37 172.16.145.4 Ethernet0/1 5.5.5.5 1FULL/DR00:00:39 172.16.145.5 Ethernet0/1 2.2.2.2 1 FULL/DR 00:01:53 172.16.12.2 Serial2/0 3.3.3.3 1 FULL/DR 00:00:35 172.16.13.2 Ethernet0/0
R4# show ip ospf neighbor Neighbor ID Pri State Dead Time Address Interface 1.1.1.1 1FULL/DROTHER00:00:39 172.16.145.1 Ethernet0/0 5.5.5.5 1FULL/DR00:00:39 172.16.145.5 Ethernet0/0
R5# show ip ospf neighbor Neighbor ID Pri State Dead Time Address Interface 1.1.1.1 1FULL/DROTHER00:00:39 172.16.145.1 Ethernet0/0 4.4.4.4 1FULL/BDR00:00:35 172.16.145.4 Ethernet0/0
When R1, R4, and R5 start establishing OSPF neighbor adjacency, they first send OSPF Hello packets to discover which OSPF neighbors are active on the common Ethernet segment. After the bidirectional communication between routers is established and they are all in the OSPF neighbor 2-Way state, the DR/BDR election process begins. The OSPF Hello packet contains three specific fields used for the DR/BDR election: Designated Router, Backup Designated Router, and Router Priority.
The Designated Router and Backup Designate Router fields are populated with a list of routers claiming to be DR and BDR. From all routers listed, the router with the highest priority becomes the DR, and the one with the next highest priority becomes the BDR. If the priority values are equal, the router with the highest OSPF router ID becomes the DR, and the one with the next highest OSPF router ID becomes the BDR.
The DR/BDR election process takes place on broadcast and NBMA networks. The main difference between the two is the type of IP address used in the Hello packet. On the multiaccess broadcast networks, routers use multicast destination IPv4 address 224.0.0.6 to communicate with the DR (called AllDRRouters), and the DR uses multicast destination IPv4 address 224.0.0.5 to communicate with all other non-DR routers (called AllSPFRouters). On NBMA networks, the DR and adjacent routers communicate using unicast addresses.
The DR/BDR election process not only occurs when the network first becomes active but also when the DR becomes unavailable. In this case, the BDR will immediately become the DR, and the election of the new BDR starts.
In the topology, R5 has been elected as the DR and R4 as the BDR due to having the highest router ID values on the segment. R1 became a DROTHER. On the multiaccess segment, it is normal behavior that the router in DROTHER status is fully adjacent with DR/BDR and in 2-WAY state with all other DROTHER routers present on the segment.
In Example 3-11, the interface on R5 is shut down toward R1 and R4. Now, reexamine the DR/BDR status on R1 and R4. After the shutdown on the interface, wait until neighbor adjacencies expire before reexamining the DR/BDR state.
Example 3-11 R5’s Ethernet 0/0 Interface Shutdown
R5(config)# interface ethernet 0/0 R5(config-if)# shutdown *Dec 8 16:20:25.080: %OSPF-5-ADJCHG: Process 1, Nbr 1.1.1.1 on Ethernet0/0 from FULL to DOWN, Neighbor Down: Interface down or detached *Dec 8 16:20:25.080: %OSPF-5-ADJCHG: Process 1, Nbr 4.4.4.4 on Ethernet0/0 from FULL to DOWN, Neighbor Down: Interface down or detached
R1# show ip ospf neighbor
Neighbor ID Pri State Dead Time Address Interface
4.4.4.4 1 FULL/DR 00:00:32 172.16.145.4 Ethernet0/1
2.2.2.2 1 FULL/DR 00:01:36 172.16.12.2 Serial2/0
3.3.3.3 1 FULL/DR 00:00:39 172.16.13.2 Ethernet0/0
R4# show ip ospf neighbor
Neighbor ID Pri State Dead Time Address Interface
1.1.1.1 1 FULL/BDR 00:00:33 172.16.145.1 Ethernet0/0
When R5’s Ethernet 0/0 interface is shut down, the DR router on the segment becomes immediately unavailable. As a result, a new DR/BDR election takes place. The output of the show ip ospf neighbor command shows that R4 has become the DR and R1 the BDR.
Next, in Example 3-12, R5’s interface toward R1 and R4 is enabled. Examine the DR/BDR status on R1, R4, and R5.
Example 3-12 R1’s Ethernet 0/0 Interface Reenabled
R5(config)# interface ethernet 0/0 R5(config-if)# no shutdown *Dec 10 08:49:26.491: %OSPF-5-ADJCHG: Process 1, Nbr 1.1.1.1 on Ethernet0/0 from LOADING to FULL, Loading Done *Dec 10 08:49:30.987: %OSPF-5-ADJCHG: Process 1, Nbr 4.4.4.4 on Ethernet0/0 from LOADING to FULL, Loading Done
R1# show ip ospf neighbor Neighbor ID Pri State Dead Time Address Interface 4.4.4.4 1FULL/DR00:00:36 172.16.145.4 Ethernet0/1 5.5.5.5 1FULL/DROTHER00:00:38 172.16.145.5 Ethernet0/1 2.2.2.2 1 FULL/DR 00:01:52 172.16.12.2 Serial2/0 3.3.3.3 1 FULL/DR 00:00:33 172.16.13.2 Ethernet0/0
R4# show ip ospf neighbor Neighbor ID Pri State Dead Time Address Interface 1.1.1.1 1FULL/BDR00:00:30 172.16.145.1 Ethernet0/0 5.5.5.5 1FULL/DROTHER00:00:34 172.16.145.5 Ethernet0/0
R5# show ip ospf neighbor Neighbor ID Pri State Dead Time Address Interface 1.1.1.1 1FULL/BDR00:00:33 172.16.145.1 Ethernet0/0 4.4.4.4 1FULL/DR00:00:37 172.16.145.4 Ethernet0/0
When R5’s Ethernet 0/0 interface is reenabled, a new DR/BDR election process will not take place even though R5 has the highest OSPF router ID on the segment. Once a DR and BDR are elected, they are not preempted. This rule makes the multiaccess segment more stable by preventing the election process from occurring whenever a new router becomes active. It means that the first two DR-eligible routers on the link will be elected as DR and BDR. A new election will occur only when one of them fails.
Using OSPF Priority in the DR/BDR Election
One of the fields in the OSPF Hello packet used in the DR/BDR election process is the Router Priority field. Every broadcast and NBMA OSPF-enabled interface is assigned a priority value between 0 and 255. By default, in Cisco IOS, the OSPF interface priority value is 1 and can be manually changed by using the ip ospf priority interface command. When electing a DR and BDR, the routers view the OSPF priority value of other routers during the Hello packet exchange process, and then use the following conditions to determine which router to select:
- The router with the highest priority value is elected as the DR.
- The router with the second-highest priority value is the BDR.
- In case of a tie where two routers have the same priority value, router ID is used as the tiebreaker. The router with the highest router ID becomes the DR. The router with the second-highest router ID becomes the BDR.
- A router with a priority that is set to 0 cannot become the DR or BDR. A router that is not the DR or BDR is called a DROTHER.
The OSPF priority is configured on R1 using the ip ospf priority interface command, shown in Example 3-13. The OSPF process is cleared on R4 to reinitiate the DR/BDR election process. Setting the OSPF interface priority to a value higher than 1 will influence the DB/BDR election in favor of R1.
Example 3-13 Configuring the OSPF Priority on an Interface
R1(config)# interface ethernet 0/1 R1(config-if)# ip ospf priority 100
R4# clear ip ospf process Reset ALL OSPF processes? [no]: yes *Dec 10 13:08:48.610: %OSPF-5-ADJCHG: Process 1, Nbr 1.1.1.1 on Ethernet0/0 from FULL to DOWN, Neighbor Down: Interface down or detached *Dec 10 13:08:48.610: %OSPF-5-ADJCHG: Process 1, Nbr 5.5.5.5 on Ethernet0/0 from FULL to DOWN, Neighbor Down: Interface down or detached *Dec 10 13:09:01.294: %OSPF-5-ADJCHG: Process 1, Nbr 1.1.1.1 on Ethernet0/0 from LOADING to FULL, Loading Done *Dec 10 13:09:04.159: %OSPF-5-ADJCHG: Process 1, Nbr 5.5.5.5 on Ethernet0/0 from LOADING to FULL, Loading Done
In this example, the OSPF interface priority value is configured to 100. This influences the DR/BDR election, so that the R1 router will become DR after the OSPF process is cleared on the current DR, R4.
In Example 3-14, the show ip ospf interface Ethernet 0/1 command on R1 verifies that it has been elected as a new DR.
Example 3-14 R1 Is the New DR
R1# show ip ospf interface ethernet 0/1
Ethernet0/1 is up, line protocol is up
Internet Address 172.16.145.1/29, Area 0, Attached via Network Statement
Process ID 1, Router ID 1.1.1.1, Network Type BROADCAST, Cost: 10
Topology-MTID Cost Disabled Shutdown Topology Name
0 10 no no Base
Transmit Delay is 1 sec, State DR, Priority 100
Designated Router (ID) 1.1.1.1, Interface address 172.16.145.1
Backup Designated router (ID) 5.5.5.5, Interface address 172.16.145.5
Timer intervals configured, Hello 10, Dead 40, Wait 40, Retransmit 5
oob-resync timeout 40
Hello due in 00:00:06
Supports Link-local Signaling (LLS)
Cisco NSF helper support enabled
IETF NSF helper support enabled
Index 1/3, flood queue length 0
Next 0x0(0)/0x0(0)
Last flood scan length is 1, maximum is 5
Last flood scan time is 0 msec, maximum is 1 msec
Neighbor Count is 2, Adjacent neighbor count is 2
Adjacent with neighbor 4.4.4.4
Adjacent with neighbor 5.5.5.5 (Backup Designated Router)
Suppress hello for 0 neighbor(s)
The Ethernet 0/1 interface on R1 has been assigned the OSPF priority value of 100, too, and when the new DR/BDR election process took place, the state of the R1 has become DR. The show ip ospf interface command on R1 shows that R1 is elected as the DR and that R5 is elected as the BDR. R1 is fully adjacent with two neighbors: R4 and R5.
OSPF Behavior in NBMA Hub-and-Spoke Topology
Special issues may arise when trying to interconnect multiple OSPF sites over an NBMA network. For example, if the NBMA topology is not fully meshed, a broadcast or multicast that is sent by one router will not reach all the other routers. Frame Relay and ATM are two examples of NBMA networks. OSPF treats NBMA environments like any other broadcast media environment, such as Ethernet; however, NBMA clouds are usually built as hub-and-spoke topologies using private virtual circuits (PVCs) or switched virtual circuits (SVCs). The hub-and-spoke topology shown in Figure 3-6 means that the NBMA network is only a partial mesh. In these cases, the physical topology does not provide multiaccess capability, on which OSPF relies. In a hub-and-spoke NBMA environment, you will need to have the hub router acting as the DR and spoke routers acting as the DROTHER routers. On the spoke router interfaces, you want to configure an OSPF priority value of 0 so that the spoke routers never participate in the DR election.
){kind=link}
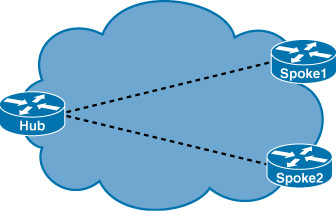
Figure 3-6 Hub-and-Spoke Topology
In addition, OSPF is not able to automatically discover OSPF neighbors over an NBMA network like Frame Relay. Neighbors must be statically configured on at least one router by using the neighbor ip_address configuration command in the router configuration mode.
Example 3-15 shows setting the OSPF priority on R4’s and R5’s Ethernet 0/0 interfaces to 0 using the ip ospf priority interface command. Setting the OSPF interface priority to 0 prevents the router from being a candidate for the DR/BDR role.
Example 3-15 Setting the OSPF Priority to 0 on R4 and R5
R4(config)# interface ethernet 0/0 R4(config-if)# ip ospf priority 0
R5(config)# interface ethernet 0/0 R5(config-if)# ip ospf priority 0
Setting the OSPF priority value to 0 on the Ethernet 0/0 interfaces for R4 and R5 means that these two routers will not participate in the DR/BDR election and will not be eligible to become the DR/BDR. These routers will be DROTHER routers.
The state of the DR/BDR status on R1, R4, and R5 is shown in Example 3-16.
Example 3-16 DR/BDR States on R1, R4, and R5
R1# show ip ospf neighbor Neighbor ID Pri State Dead Time Address Interface 4.4.4.4 0FULL/DROTHER00:00:36 172.16.145.4 Ethernet0/1 5.5.5.5 0FULL/DROTHER00:00:34 172.16.145.5 Ethernet0/1 2.2.2.2 1FULL/DR00:01:33 172.16.12.2 Serial2/0 3.3.3.3 1FULL/DR00:00:30 172.16.13.2 Ethernet0/0
R4# show ip ospf neighbor Neighbor ID Pri State Dead Time Address Interface 1.1.1.1 100FULL/DR00:00:37 172.16.145.1 Ethernet0/0 5.5.5.5 02WAY/DROTHER00:00:37 172.16.145.5 Ethernet0/0
R5# show ip ospf neighbor Neighbor ID Pri State Dead Time Address Interface 1.1.1.1 100FULL/DR00:00:32 172.16.145.1 Ethernet0/0 4.4.4.4 02WAY/DROTHER00:00:37 172.16.145.4 Ethernet0/0
The output of the show ip ospf neighbor commands on R1 shows that R1 is fully adjacent with R4 and R5 and that R4 and R5 have DROTHER functions. R4 is fully adjacent with the DR router R1, but it maintains a 2-Way state with its peer DROTHER router R5. Similarly, R5 is fully adjacent with DR R1 and maintains a 2-Way state with the DROTHER router R4. A 2-Way state between non-DR/BDR routers on the segment is normal behavior; they do not synchronize LSDBs directly, but over DR/BDR. By maintaining 2-Way state, DROTHER routers keep other DROTHER peers informed about their presence on the network.
The Importance of MTU
The IP MTU parameter determines the maximum size of an IPv4 packet that can be forwarded out the interface without fragmentation. If a packet with an IPv4 MTU larger than the maximum arrives at the router interface, it will be either discarded, if the DF bit in the packet header is set, or it will be fragmented. OSPF for IPv4 packets completely relies on IPv4 for the possible fragmentation. Although RFC 2328 does not recommend OSPF packet fragmentation, in some situations the size of the OSPF packet has greater value than the interface IPv4 MTU. If MTUs are mismatched between two neighbors, this could introduce issues with exchange of link-state packets, resulting in continuous retransmissions.
To prevent such issues, OSPF requires that the same IPv4 MTU be configured on both sides of the link. If neighbors have a mismatched IPv4 MTU configured, they will not be able to form full OSPF adjacency. They will be stuck in the ExStart adjacency state.
In Example 3-17, the IPv4 MTU size on the R3 Ethernet 0/0 interface is changed to 1400.
Example 3-17 Configuration of the IPv4 MTU on R3’s Ethernet 0/0 Interface
R3(config)# interface ethernet 0/0 R3(config-if)# ip mtu 1400
After the IPv4 MTU size is changed on R3’s Ethernet 0/0 interface, this creates a mismatch between IPv4 MTU sizes on the link between R3 and R1. This mismatch will result in R3 and R1 not being able to synchronize their OSPF databases, and a new full adjacency between them will not be established. This is observed in Example 3-18 using the debug ip ospf adj command on R3. The OSPF process is cleared to reset adjacency, and debug is disabled when the OSPF session is reestablished.
Example 3-18 Observing a Mismatched MTU
R3# debug ip ospf adj R3# clear ip ospf process Reset ALL OSPF processes? [no]: yes *Jan 19 17:37:05.969: OSPF-3 ADJ Et0/0: Interface going Up *Jan 19 17:37:05.969: OSPF-3 ADJ Et0/0: 2 Way Communication to 1.1.1.1, state 2WAY *Jan 19 17:37:05.969: OSPF-3 ADJ Et0/0: Backup seen event before WAIT timer *Jan 19 17:37:05.969: OSPF-3 ADJ Et0/0: DR/BDR election *Jan 19 17:37:05.969: OSPF-3 ADJ Et0/0: Elect BDR 3.3.3.3 *Jan 19 17:37:05.969: OSPF-3 ADJ Et0/0: Elect DR 1.1.1.1 *Jan 19 17:37:05.969: OSPF-3 ADJ Et0/0: Elect BDR 3.3.3.3 *Jan 19 17:37:05.969: OSPF-3 ADJ Et0/0: Elect DR 1.1.1.1 *Jan 19 17:37:05.969: OSPF-3 ADJ Et0/0: DR: 1.1.1.1 (Id) BDR: 3.3.3.3 (Id) *Jan 19 17:37:05.970: OSPF-3 ADJ Et0/0: Nbr 1.1.1.1: Prepare dbase exchange *Jan 19 17:37:05.970: OSPF-3 ADJ Et0/0: Send DBD to 1.1.1.1 seq 0x21D6 opt 0x52 flag 0x7 len 32 *Jan 19 17:37:05.970: OSPF-3 ADJ Et0/0:Rcv DBD from 1.1.1.1seq 0x968 opt 0x52 flag 0x7 len 32mtu 1500 state EXSTART*Jan 19 17:37:05.970: OSPF-3 ADJ Et0/0:Nbr 1.1.1.1 has larger interface MTU*Jan 19 17:37:05.970: OSPF-3 ADJ Et0/0: Rcv DBD from 1.1.1.1 seq 0x21D6 opt 0x52 flag 0x2 len 112 mtu 1500state EXSTART*Jan 19 17:37:05.970: OSPF-3 ADJ Et0/0: Nbr 1.1.1.1 has larger interface MTU R1# no debug ip ospf adj
The DBD packet carries information about largest nonfragmented packet that can be sent from the neighbor. In this situation, the IPv4 MTU values on different sides of the link are not equal. R3 will receive the DBD packet with an IPv4 MTU size of 1500, which is greater than its own MTU size of 1400. This will result in the inability of both R3 and R1 to establish full neighbor adjacency, and the output of the debug command will display that Nbr has a larger interface MTU message. Mismatched neighbors will stay in ExStart state. To form full OSPF adjacency, the IPv4 MTU needs to match on both sides of the link.
In Example 3-19, the OSPF neighbor state is verified on R3 and R1.
Example 3-19 Verifying the OSPF Neighbor States
R3# show ip ospf neighbor
Neighbor ID Pri State Dead Time Address Interface
1.1.1.1 1 EXSTART/BDR 00:00:38 172.16.13.1 Ethernet0/0
R1# show ip ospf neighbor Neighbor ID Pri State Dead Time Address Interface 4.4.4.4 0 FULL/DROTHER 00:00:39 172.16.145.4 Ethernet0/1 5.5.5.5 0 FULL/DROTHER 00:00:38 172.16.145.5 Ethernet0/1 2.2.2.2 1 FULL/DR 00:01:55 172.16.12.2 Serial2/0 3.3.3.3 1EXCHANGE/DR 00:00:36 172.16.13.2 Ethernet0/0 R1# show ip ospf neighbor Neighbor ID Pri State Dead Time Address Interface 4.4.4.4 0 FULL/DROTHER 00:00:38 172.16.145.4 Ethernet0/1 5.5.5.5 0 FULL/DROTHER 00:00:31 172.16.145.5 Ethernet0/1 2.2.2.2 1 FULL/DR 00:01:31 172.16.12.2 Serial2/0 3.3.3.3 1INIT/DROTHER00:00:33 172.16.13.2 Ethernet0/0
Mismatching interface IPv4 MTU sizes on opposite sides of the OSPF link results in the inability to form full adjacency. R3, which detected that R1 has higher MTU, keeps the neighbor adjacency in ExStart state. R1 continues to retransmit initial BDB packet to R3, but R3 cannot acknowledge them because of the unequal IPv4 MTU. On R1, you can observe how the OSPF neighbor relationship state with R3 is unstable. Adjacency gets to the Exchange state, but is then terminated, starting again from the Init state up to the Exchange state.
The recommended way to solve such issues is to make sure that the IPv4 MTU matches between OSPF neighbors.
Manipulating OSPF Timers
Similar to EIGRP, OSPF uses two timers to check neighbor reachability: the hello and dead intervals. The values of hello and dead intervals are carried in OSPF Hello packets and serve as a keepalive message, with the purpose of acknowledging the presence of the router on the segment. The hello interval specifies the frequency of sending OSPF Hello packets in seconds. The OSPF dead timer specifies how long a router waits to receive a Hello packet before it declares a neighbor router as down.
OSPF requires that both hello and dead timers be identical for all routers on the segment to become OSPF neighbors. The default value of the OSPF hello timer on multiaccess broadcast and point-to-point links is 10 seconds, and is 30 seconds on all other network types, including NBMA. When you configure the hello interval, the default value of the dead interval is automatically adjusted to four times the hello interval. For broadcast and point-to-point links, it is 40 seconds, and for all other OSPF network types, it is 120 seconds.
To detect faster topological changes, you can lower the value of OSPF hello interval, with the downside of having more routing traffic on the link. The debug ip ospf hello command enables you to investigate hello timer mismatch.
In Example 3-20, R1, the different hello/dead timer values on Ethernet 0/1, and Frame Relay Serial 2/0 interfaces are observed using the show ip ospf interface command.
Example 3-20 Examining the Hello/Dead Timers on R1 Interfaces
R1# show ip ospf interface ethernet 0/1Ethernet0/1is up, line protocol is up Internet Address 172.16.145.1/29, Area 0, Attached via Network Statement Process ID 1, Router ID 1.1.1.1,Network Type BROADCAST, Cost: 10 Topology-MTID Cost Disabled Shutdown Topology Name 0 10 no no Base Transmit Delay is 1 sec, State DROTHER, Priority 1 Designated Router (ID) 5.5.5.5, Interface address 172.16.145.5 Backup Designated router (ID) 4.4.4.4, Interface address 172.16.145.4Timer intervals configured, Hello 10, Dead 40, Wait 40, Retransmit 5 <Output omitted> R1# show ip ospf interface serial 2/0Serial2/0is up, line protocol is up Internet Address 172.16.12.1/30, Area 1, Attached via Network Statement Process ID 1, Router ID 1.1.1.1,Network Type NON_BROADCAST, Cost: 64 Topology-MTID Cost Disabled Shutdown Topology Name 0 64 no no Base Transmit Delay is 1 sec, State BDR, Priority 1 Designated Router (ID) 2.2.2.2, Interface address 172.16.12.2 Backup Designated router (ID) 1.1.1.1, Interface address 172.16.12.1Timer intervals configured, Hello 30, Dead 120, Wait 120, Retransmit 5 <Output omitted>
The default value of the OSPF hello interval on broadcast multiaccess (Ethernet) and point-to-point links is 10 seconds, and the default value of the dead interval is four times hello (40 seconds). Default values of the OSPF hello and dead timers on all other OSPF network types, including nonbroadcast (NBMA) like Frame Relay on the Serial 2/0 interface, are 30 seconds and 120 seconds, respectively.
On low-speed links, you might want to alter default OSPF timer values to achieve faster convergence. The negative aspect of lowering the OSPF hello interval is the overhead of more frequent routing updates causing higher router utilization and more traffic on the link.
In Example 3-21, the default OSPF hello and dead intervals on R1’s Frame Relay Serial 2/0 interface are modified. You can change the OSPF by using the ip ospf hello-interval and ip ospf dead-interval interface commands.
Example 3-21 Modifying the Hello and Dead Intervals on R1’s Serial Interface
R1(config)# interface serial 2/0
R1(config-if)# ip ospf hello-interval 8
R1(config-if)# ip ospf dead-interval 30
*Jan 20 13:17:34.441: %OSPF-5-ADJCHG: Process 1, Nbr 2.2.2.2 on Serial2/0 from
FULL to DOWN, Neighbor Down: Dead timer expired
Once the default OSPF hello and dead interval values on the Frame Relay link are changed, both routers will detect hello timer mismatch. As a result, the dead timer will not be refreshed, so it will expire, declaring the OSPF neighbor relationship as down.
In Example 3-22, R2’s default OSPF hello and dead timers on the Frame Relay Serial 0/0 interface are changed so that they match respective values configured on R1.
Example 3-22 Modifying the Hello and Dead Intervals on R2’s Serial Interface
R2(config)# interface serial 0/0 R2(config-if)# ip ospf hello-interval 8 R2(config-if)# ip ospf dead-interval 30 *Jan 20 13:38:58.976: %OSPF-5-ADJCHG: Process 2, Nbr 1.1.1.1 on Serial0/0fromLOADING to FULL, Loading Done
When you are changing OSPF hello and dead timers on R2 so that they match the timers on R1, both routers on the link will be able to establish adjacency and elect the DR/BDR on the NBMA segment. Routers will then exchange and synchronize LSDBs and form full neighbor adjacency.
On R2, the OSPF neighbor state is verified by using the show ip ospf neighbor detail command, as demonstrated in Example 3-23.
Example 3-23 Verifying the OSPF Neighbor States on R2
R2# show ip ospf neighbor detailNeighbor 1.1.1.1, interface address 172.16.12.1In the area 1 via interface Serial0/0Neighbor priority is 1,State is FULL, 6 state changesDR is 172.16.12.2 BDR is 172.16.12.1Poll interval 120 Options is 0x12 in Hello (E-bit, L-bit) Options is 0x52 in DBD (E-bit, L-bit, O-bit) LLS Options is 0x1 (LR) Dead timer due in 00:00:26Neighbor is up for 00:14:57Index 1/1, retransmission queue length 0, number of retransmission 0 First 0x0(0)/0x0(0) Next 0x0(0)/0x0(0) Last retransmission scan length is 0, maximum is 0 Last retransmission scan time is 0 msec, maximum is 0 msec
The output of the show ip ospf neighbor detail command confirms that full OSPF adjacency with R1 is established. The output also shows additional information about neighbor router ID, DR/BDR roles, and how long the neighbor session has been established.
OSPF Neighbor Relationship over Point-to-Point Links
Figure 3-7 shows a point-to-point network joining a single pair of routers. A T1 serial line that is configured with a data link layer protocol such as PPP or High-Level Data Link Control (HDLC) is an example of a point-to-point network.
)
Figure 3-7 Point-to-Point link
On these types of networks, the router dynamically detects its neighboring routers by multicasting its Hello packets to all OSPF routers, using the 224.0.0.5 address. On point-to-point networks, neighboring routers become adjacent whenever they can communicate directly. No DR or BDR election is performed; there can be only two routers on a point-to-point link, so there is no need for a DR or BDR.
The default OSPF hello and dead timers on point-to-point links are 10 seconds and 40 seconds, respectively.
OSPF Neighbor Relationship over Layer 3 MPLS VPN
Figure 3-8 shows a Layer 3 MPLS VPN architecture, where the ISP provides a peer-to-peer VPN architecture. In this architecture, provider edge (PE) routers participate in customer routing, guaranteeing optimum routing between customer sites. Therefore, the PE routers carry a separate set of routes for each customer, resulting in perfect isolation between customers.
)
Figure 3-8 Layer 3 MPLS VPN
The following applies to Layer 3 MPLS VPN technology, even when running OSPF as a provider edge - customer edge (PE-CE) routing protocol:
- The customer routers should not be aware of MPLS VPN; they should run standard IP routing software.
- The core routers in the provider network between the two PE routers are known as the P routers (not shown in the diagram). The P routers do not carry customer VPN routes for the MPLS VPN solution to be scalable.
- The PE routers must support MPLS VPN services and traditional Internet services.
To OSPF, the Layer 3 MPLS VPN backbone looks like a standard corporate backbone that runs standard IP routing software. Routing updates are exchanged between the customer routers and the PE routers that appear as normal routers in the customer network. OSPF is enabled on proper interfaces by using the network command. The standard design rules that are used for enterprise Layer 3 MPLS VPN backbones can be applied to the design of the customer network. The service provider routers are hidden from the customer view, and CE routers are unaware of MPLS VPN. Therefore, the internal topology of the Layer 3 MPLS backbone is totally transparent to the customer. The PE routers receive IPv4 routing updates from the CE routers and install them in the appropriate virtual routing and forwarding (VRF) table. This part of the configuration, and operation, is the responsibility of a service provider.
The PE-CE can have any OSPF network type: point-to-point, broadcast, or even nonbroadcast multiaccess.
The only difference between a PE-CE design and a regular OSPF design is that the customer has to agree with the service provider about the OSPF parameters (area ID, authentication password, and so on); usually, these parameters are governed by the service provider.
OSPF Neighbor Relationship over Layer 2 MPLS VPN
Figure 3-9 shows a Layer 2 MPLS VPN. The MPLS backbone of the service provider is used to enable Layer 2 Ethernet connectivity between the customer routers R1 and R2, whether an Ethernet over MPLS (EoMPLS) or Layer 2 MPLS VPN Ethernet service is used.
)
Figure 3-9 Layer 2 MPLS VPN
R1 and R2 thus exchange Ethernet frames. PE router PE1 takes the Ethernet frames that are received from R1 on the link to PE1, encapsulates them into MPLS packets, and forwards them across the backbone to router PE2. PE2 decapsulates the MPLS packets and reproduces the Ethernet frames on the link toward R2. EoMPLS and Layer 2 MPLS VPN typically do not participate in Shortest Tree Protocol (STP) and bridge protocol data unit (BPDU) exchanges, so EoMPLS and Layer 2 MPLS VPNs are transparent to the customer routers.
The Ethernet frames are transparently exchanged across the MPLS backbone. Keep in mind that customer routers can be connected either in a port-to-port fashion, in which PE routers take whatever Ethernet frame is received and forward the frames across the Layer 2 MPLS VPN backbone, or in a VLAN subinterface fashion in which frames for a particular VLAN—identified with subinterface in configuration—are encapsulated and sent across the Layer 2 MPLS VPN backbone.
When deploying OSPF over EoMPLS, there are no changes to the existing OSPF configuration from the customer perspective.
OSPF needs to be enabled, and network commands must include the interfaces that are required by the relevant OSPF area to start the OSPF properly.
R1 and R2 form a neighbor relationship with each other over the Layer 2 MPLS VPN backbone. From an OSPF perspective, the Layer 2 MPLS VPN backbone, PE1, and PE2 are all invisible.
A neighbor relationship is established between R1 and R2 directly, and it behaves in the same way as on a regular Ethernet broadcast network.
OSPF Neighbor States
OSPF neighbors go through multiple neighbor states before forming full OSPF adjacency, as illustrated in Figure 3-10.
)
Figure 3-10 OSPF States
The following is a brief summary of the states that an interface passes through before becoming adjacent to another router:
- Down: No information has been received on the segment.
- Init: The interface has detected a Hello packet coming from a neighbor, but bidirectional communication has not yet been established.
- 2-Way: There is bidirectional communication with a neighbor. The router has seen itself in the Hello packets coming from a neighbor. At the end of this stage, the DR and BDR election would have been done if necessary. When routers are in the 2-Way state, they must decide whether to proceed in building an adjacency. The decision is based on whether one of the routers is a DR or BDR or the link is a point-to-point or a virtual link.
- ExStart: Routers are trying to establish the initial sequence number that is going to be used in the information exchange packets. The sequence number ensures that routers always get the most recent information. One router will become the master and the other will become the slave. The primary router will poll the secondary for information.
- Exchange: Routers will describe their entire LSDB by sending database description (DBD) packets. A DBD includes information about the LSA entry header that appears in the router’s LSDB. The entries can be about a link or about a network. Each LSA entry header includes information about the link-state type, the address of the advertising router, the link’s cost, and the sequence number. The router uses the sequence number to determine the “newness” of the received link-state information.
- Loading: In this state, routers are finalizing the information exchange. Routers have built a link-state request list and a link-state retransmission list. Any information that looks incomplete or outdated will be put on the request list. Any update that is sent will be put on the retransmission list until it gets acknowledged.
- Full: In this state, adjacency is complete. The neighboring routers are fully adjacent. Adjacent routers will have similar LSDBs.
OSPF Network Types
OSPF defines distinct types of networks based on their physical link types, as shown in Table 3-1. OSPF operation on each type is different, including how adjacencies are established and which configuration is required.
Table 3-1 OSPF Network Types
|
OSPF Network Type |
Uses DR/BDR |
Default Hello Interval (sec) |
Dynamic Neighbor Discovery |
More than Two Routers Allowed in Subnet |
|
Point-to-point |
No |
10 |
Yes |
No |
|
Broadcast |
Yes |
10 |
Yes |
Yes |
|
Nonbroadcast |
Yes |
30 |
No |
Yes |
|
Point-to-multipoint nonbroadcast |
No |
30 |
No |
Yes |
|
Looback |
No |
— |
— |
No |
These are the most common network types that are defined by OSPF:
- Point-to-point: Routers use multicast to dynamically discover neighbors. There is no DR/BDR election because only two routers can be connected on a single point-to-point segment. It is a default OSPF network type for serial links and point-to-point Frame Relay subinterfaces.
- Broadcast: Multicast is used to dynamically discover neighbors. The DR and BDR are elected to optimize the exchange of information. It is a default OSPF network type for Ethernet links.
- Nonbroadcast: Used on networks that interconnect more than two routers but without broadcast capability. Frame Relay and ATM are examples of NBMA networks. Neighbors must be statically configured, followed by DR/BDR election. This network type is the default for all physical interfaces and multipoint subinterfaces using Frame Relay encapsulation.
- Point-to-multipoint: OSPF treats this network type as a logical collection of point-to-point links even though all interfaces belong to the common IP subnet. Every interface IP address will appear in the routing table of the neighbors as a host /32 route. Neighbors are discovered dynamically using multicast. No DR/BDR election occurs.
- Point-to-multipoint nonbroadcast: Cisco extension that has the same characteristics as point-to-multipoint type except for the fact that neighbors are not discovered dynamically. Neighbors must be statically defined, and unicast is used for communication. Can be useful in point-to-multipoint scenarios where multicast and broadcast are not supported.
- Loopback: Default network type on loopback interfaces.
You can change OSPF network type by using the interface configuration mode command ip ospf network network_type.
Configuring Passive Interfaces
Passive interface configuration is a common method for hardening routing protocols and reducing the use of resources. The passive interface is supported by OSPF, and a sample configuration is shown in Example 3-24.
Example 3-24 Passive Interface Configuration for OSPF
Router(config)# router ospf 1 Router(config-if)# passive-interface default Router(config-if)# no passive-interface serial 1/0
When you configure a passive interface under the OSPF process, the router stops sending and receiving OSPF Hello packets on the selected interface. The passive interface should be used only on interfaces where the router is not expected to form any OSPF neighbor adjacency. A specific interface can be configured as passive, or passive interface can be configured as the default. If the default option is used, any interfaces that need to form a neighbor adjacency must be exempted with the no passive-interface configuration command.