Components of Decision Analytics
- Classifying According to Existing Categories
- Classifying According to Naturally Occurring Clusters
- Some Terminology Problems
This chapter is from the book
This chapter is from the book
This chapter is from the book
Regardless of what line of work we’re in, we make decisions about people, medical treatments, marketing programs, soil amendments, and so on. If we’re to make informed, sensible decisions, we need to understand how to find clusters of people who are likely or unlikely to succeed in a job; how to classify medications according to their efficacy; how to classify mass mailings according to their likelihood of driving revenue; how to divide fertilizers into those that will work well with our crops and those that won’t.
The key is to find ways of classifying into categories that make sense and that stand up in more than just one sample. Decision analytics comprises several types of analysis that help you make that sort of classification. The techniques have been around for decades, but it’s only with the emergence of the term analytics that the ways that those techniques can work together have gained real currency.
This initial chapter provides a brief overview of each of the techniques discussed in the book’s remaining chapters, along with an introduction to the conditions that might guide you toward selecting a particular technique.
Classifying According to Existing Categories
Several techniques used in decision analytics are intended for sets of data where you already know the correct classification of the records. The idea of classifying records into known categories might seem pointless at first, but bear in mind that this is usually a preliminary analysis. You typically intend to apply what you learn from such a pilot study to other records—and you don’t yet know which categories those other records belong to.
Using a Two-Step Approach
A classification procedure that informs your decision making often involves two steps. For example, suppose you develop a new antibiotic that shows promise of preventing or curing new bacterial infections that have so far proven drug-resistant. You test your antibiotic in a double-blind experiment that employs random selection and assignment, with a comparison arm getting a traditional antibiotic and an experimental arm getting your new medication. You get mixed results: Your medication stops the infection in about one third of the patients in the experimental arm, but it’s relatively ineffective in the remaining patients.
You would like to determine whether there are any patient characteristics among those who received your new medication that tend either to enable or to block its effects. You know your classification categories—those in whom the infection was stopped, and those in whom the infection was unaffected. You can now test whether other patient characteristics, such as age, sex, infection history, blood tests and so on, can reliably distinguish the two classification categories. Several types of analysis, each discussed in this book, are available to help you make those tests: Multivariate analysis of variance and discriminant function analysis are two such analyses. If those latter tests are successful, you can classify future patients into a group that’s likely to be helped by your medication and a group that’s unlikely to be helped.
Notice the sequence in the previous example. You start with a group whose category memberships are known—those who received your medication and were helped and those who weren’t. Pending a successful test of existing patient characteristics and their response to your medication, you might now be in a position to classify new patients into a group that your medication is likely to help, and a group that isn’t. Health care providers can now make more informed decisions about prescribing your medication.
Multiple Regression and Decision Analytics
The previous section discusses the issue of classifying and decision making purely from the standpoint of design. Let’s take another look from the point of view of analysis rather than design—and, not incidentally, in terms of multiple regression, which employs ideas that underlie many of the more advanced techniques described in this book.
You’re probably familiar to some degree with the technique of multiple regression. That technique seeks to develop an equation that looks something like this one:
Y = a1X1 + a2X2 + b
In that equation, Y is a variable such as weight that you’d like to predict. X1 is a variable such as height, and X2 is another variable such as age. You’d like to use your knowledge of people’s heights and ages to predict their weight.
You locate a sample of, say, 50 people, weigh them, measure each person’s height, and record their ages. Then you push that data through an application that calculates multiple regression statistics and in that way learn the values of the remaining three items in the equation:
- a1, a coefficient you multiply by a person’s height
- a2, a coefficient you multiply by a person’s age
- b, a constant that you add to adjust the scale of the results
You can now find another person whose weight you don’t know. Get his height and age and plug them into your multiple regression equation. If your sample of 50 people is reasonably representative, and if height and age are reliably related to weight, you can expect to predict this new person’s weight with fair accuracy.
You have established the numeric relationships between two predictor variables, height and age, and a predicted variable, weight. You did so using a sample in which weight—which you want to predict—is known. You expect to use that information with people whose weight you don’t know.
At root, those concepts are the same as the ones that underlie several of the decision analytics techniques that this book discusses. You start out with a sample of records (for example, people, plants, or objects) whose categories you already know (for example, their recent purchase behaviors with respect to your products, whether they produce crops in relatively arid conditions, whether they shatter when you subject them to abnormal temperature ranges). You take the necessary measures on those records and run the numbers through one or more of the techniques described in this book.
Then you apply the resulting equations to a new sample of people (or plants or objects) whose purchasing behavior, or ability to produce crops, or resistance to unusual temperatures is unknown. If your original sample was a representative one, and if there are useful relationships between the variables you measured and the ones you want to predict, you’re in business. You can decide whether John Jones is likely or unlikely to buy your product, whether your new breed of corn will flourish or wither if it’s planted just east of Tucson, or whether pistons made from a new alloy will shatter in high temperature driving.
I slipped something in on you in the last two paragraphs. The first example in this section concerns the prediction of a continuous variable, weight. Ordinary, least-squares multiple regression is well suited to that sort of situation. But the example in the previous section uses categories, nominal classifications, as a predicted variable: cures infection versus doesn’t cure it. As the values of a predicted variable, categories present problems that multiple regression has difficulty overcoming. When the predictor variables are categories, there’s no problem. In fact, the traditional approach to analysis of variance (ANOVA) and the regression approach to ANOVA are both designed specifically to handle that sort of situation. The problem arises when it’s the predicted variable rather than the predictor variables that is measured on a nominal rather than a continuous scale.
But that’s precisely the sort of situation you’re confronted with when you have to make a choice between one of two or more alternatives. Will this new product succeed or fail? Will this new medicine prolong longevity or shorten it due to side effects? Based solely on their voting records, which political party did these two congressional representatives from the nineteenth century belong to?
So, to answer that sort of question, you need analysis techniques—decision analytics—designed specifically for situations in which the outcome or predicted variable is measured on a nominal scale, in terms of categories. That, of course, is the focus of this book: analysis techniques that enable you to use numeric variables to classify records into groups, and thereby make decisions about the records on the basis of the group you project them into. To anticipate some of the examples I use in subsequent chapters:
- How can you classify potential borrowers into those who are likely to repay loans in accordance with the loan schedules, and those who are unlikely to do so?
- How can you accurately classify apparently identical plants and animals into different species according to physical characteristics such as petal width or length of femur?
- Which people in this database are so likely to purchase our resort properties in the Bahamas that we should fly them there and house them for a weeklong sales pitch?
Access to a Reference Sample
In the examples I just cited, it’s best if you have a reference sample: a sample of records that are representative of the records that you want to classify and that are already correctly classified. (Such samples are often termed supervised or training samples.) The second example outlined in this chapter, regarding weight, height, and age, discussed the development of an equation to predict weight using a sample in which weight was known. Later on you could use the equation with people whose weight is not known.
Similarly, if your purpose is to classify loan applicants into Approved versus Declined, it’s best if you can start with a representative reference sample of applicants, perhaps culled from your company’s historical records, along with variables such as default status, income, credit rating, and state of residence. You could develop an equation that classifies applicants into your Approved and Declined categories.
Multiple regression is not an ideal technique for this sort of decision analysis because, as I noted earlier, the predicted variable is not a continuous one such as weight but is a dichotomy. However, multiple regression shares many concepts and treatments with techniques that in fact are suited to classifying records into categories. So you’re ahead of the game if you’ve had occasion to study or use multiple regression in the past. If not, don’t be concerned; this book doesn’t assume that you’re a multiple regression maven.
Multiple regression does require that you have access to a reference sample, one in which the variable that is eventually to be predicted is known. That information is used to develop the prediction equation, which in turn is used with data sets in which the predicted variable is as yet unknown. Other analytic techniques, designed for use with categorical outcome variables, and which also must make use of reference samples, include those I discuss in the next few sections.
Multivariate Analysis of Variance
Multivariate analysis of variance, or MANOVA, extends the purpose of ordinary ANOVA to multiple dependent variables. (Statistical jargon tends to use the term multivariate only when there is more than one predicted or outcome or dependent variable; however, even this distinction breaks down when you consider discriminant analysis.) Using ordinary univariate ANOVA, you might investigate whether people who pay back loans according to the agreed terms have, on average at the time the loan is made, different credit ratings than people who subsequently default. (I review the concepts and procedures used in ANOVA in Chapter 3, “Univariate Analysis of Variance (ANOVA).”) Here, the predictor variable is whether the borrower pays back the loan, and the predicted variable is the borrower’s credit rating.
But you might be interested in more than just those people’s credit ratings. Do the two groups differ in average age of the borrower? In the size of the loans they apply for? In the average term of the loan? If you want to answer all those questions, not just one, you typically start out with MANOVA, the multivariate version of ANOVA. Notice that if you want MANOVA to analyze group differences in average credit ratings, average age of borrower, average size of loan, and average term of loan, you need to work with multiple predicted variables, not solely the single predicted variable you would analyze using univariate ANOVA.
MANOVA is not a classification procedure in the sense I used the phrase earlier. You do not employ MANOVA to help determine whether some combination of credit rating, borrower’s age, size of loan, and term of loan accurately classifies applicants according to whether they can be expected to repay the loan or default. Instead, MANOVA helps you decide whether those who repay their loans differ from those who don’t on any one of, or a combination of, the outcome variables—credit rating, age, and so on.
You don’t use one univariate ANOVA after another to make those inferences because the outcome variables are likely correlated with one another. Those correlations have an effect, which cannot be quantified, on the probability estimate of each univariate ANOVA. In other words, you might think that each of your univariate F-tests is operating at an alpha level of .05. But because of the correlations the F-tests are not independent of one another and the actual alpha level for one test might be .12, for another test .08, and so on. MANOVA helps to protect you against this kind of problem by taking all the outcome variables into account simultaneously. See Chapter 4, “Multivariate Analysis of Variance (MANOVA),” for a discussion of the methods used in MANOVA.
It surprises some multivariate analysts to learn that you can carry out an entire MANOVA using Excel’s worksheet functions only. But it’s true that by deploying Excel’s matrix functions properly—MDETERM(), MINVERSE(), MMULT(), TRANSPOSE() and so on—you can go from raw data to a complete MANOVA including Wilks’ Lambda and a multivariate F-test in just a few steps. Nevertheless, among the files you can download from the publisher’s website is a MANOVA workbook with subroutines that automate the process for you. Apart from learning what’s involved, there’s little point to doing it by hand if you can turn things over to code.
But MANOVA, despite its advantages in this sort of situation, still doesn’t classify records for you. The reason I’ve gone on about MANOVA is explained in the next section.
Discriminant Function Analysis
Discriminant function analysis is a technique developed by Sir Ronald Fisher during the 1930s. It is sometimes referred to as linear discriminant analysis or LDA, or as multiple discriminant analysis, both in writings and in the names conferred by statistical applications such as R. Like MANOVA, discriminant analysis is considered a true multivariate technique because its approach is to simultaneously analyze multiple continuous variables, even though they are treated as predictors rather than predicted or outcome variables.
Discriminant analysis is typically used as a followup to a MANOVA. If the MANOVA returns a multivariate F-ratio that is not significant at the alpha level selected by the researcher, there is no point to proceeding further. If the categories do not differ significantly as to their mean values on any of the continuous variables, then the reverse is also true. The continuous variables cannot reliably classify the records into the categories of interest.
But if the MANOVA returns a significant multivariate F-ratio, it makes sense to continue with a discriminant analysis, which, in effect, turns the MANOVA around. Instead of asking whether the categories differ in their mean values of the continuous variables, as does MANOVA, discriminant analysis asks how the continuous variables combine to separate the records into different categories.
The viewpoint adopted by discriminant analysis brings about two important outcomes:
- It enables you to look more closely than does MANOVA at how the continuous variables work together to distinguish the category membership.
- It provides you with an equation called a discriminant function that, when used like a multiple regression equation, assigns individual records to categories such as Repays versus Defaults or Buys versus Doesn’t Buy.
Chapter 5, “Discriminant Function Analysis: The Basics,” and Chapter 6, “Discriminant Function Analysis: Further Issues,” show you how to obtain the discriminant function, and what use you can make of it, using Excel as the platform. An associated Excel workbook automates a discriminant analysis using the results of a preliminary MANOVA.
Both MANOVA and discriminant analysis are legitimately thought of as multivariate techniques, particularly when you consider that they look at the same phenomena, but from different ends of the telescope. They are also parametric techniques: Their statistical tests make use of theoretical distributions such as the F-ratio and Wilks’ lambda. Therefore these parametric techniques are able to return to you information about, say, the likelihood of getting an F-ratio as large as the one you observed in your sample if the population means were actually identical.
Those parametric properties invest the tests with statistical power. Compared to other, nonparametric tests, techniques such as discriminant analysis are better (sometimes much better) able to inform you that an outcome is a reliable one. With a reliable finding, you have every right to expect that you would get the same results from a replication sample, constructed similarly.
But that added statistical power comes with a cost: You have to make some assumptions (which of course you can test). In the case of MANOVA and discriminant analysis, for example, you assume that the distribution of the continuous variables is “multivariate normal.” That assumption implies that you should check scattercharts of each pair of continuous variables, across all your groups, looking for nonlinear relationships between the variables. You should also arrange for histograms of each variable, again by group, to see whether the variable’s distribution appears skewed.
NOTE
Excel can make your life a little easier here, although admittedly not by much. It’s easy enough to create a scatterchart in Excel. (Begin by going to the Insert tab on the Ribbon in Excel 2007 or 2010 or 2013. Click the Chart Wizard button in an earlier version.) But if you have 3 categories and 7 continuous variables, that’s 3 × 7 × 6 or a tedious 126 scattercharts to create. Pivot charts would make things a little quicker, but pivot charts do not offer a scatterchart type.
Excel has a worksheet function, SKEW(), which returns the skewness of a distribution of values. The function does not return perhaps the most popular version of skewness, the average cubed z-score. Instead, SKEW() uses this formula:
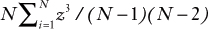
With a small number of records, Excel’s value of skewness can be easily half again as large as the average cubed z-score (which of course does not depend on the number of records). Still, using SKEW() is undoubtedly faster than creating histograms. (The Data Analysis add-in has a Histograms tool that can speed the process considerably.)
As another example, MANOVA assumes that the variance-covariance matrix is equivalent in the different categories. All that means is that if you assembled a matrix of your variables, showing each variable’s variance and its covariance with the other continuous variables in your design, the values in that matrix would be equivalent for the Repayers and for the Defaulters, for the Buyers and the Non-Buyers. Notice that I used the word “equivalent,” not “equal.” The issue is whether the variance-covariance matrices are equal in the population, not necessarily in the sample (where they’ll never be equal). Again, you can test whether your data meets this assumption. Bartlett’s test is the usual method and the MANOVA workbook, which you can download from the publisher’s website, carries that test out for you.
If these assumptions are met, you’ll have a more powerful test available than if they are not met. When the assumptions are not met, you can fall back on what’s typically a somewhat less powerful technique: logistic regression.
Logistic Regression
Logistic regression differs from ordinary least squares regression in a fundamental way. Least squares regression depends on correlations, which in turn depend on the calculation of the sums of squared deviations, and regression works to minimize those sums—hence the term “least squares.”
In contrast, logistic regression depends not on correlations but on odds ratios (or, less formally, odds). The process of logistic regression is not a straightforward computation as it is in simple or multiple regression. Logistic regression uses maximum likelihood techniques to arrive at the coefficients for its equation: for example, the values for a1 and a2 that I mentioned at the beginning of this chapter. Conceptually there’s nothing magical about maximum likelihood. It’s a matter of trial and error: the educated and automated process of trying out different values for the coefficients until they provide an optimal result. I discuss how to convert the probabilities to odds, the odds to a special formulation called the logit, how to get your maximum likelihood estimates using Excel’s Solver—and how to find your way back to probabilities, in Chapter 2, “Logistic Regression.”
Largely because the logistic regression process does not rely on reference distributions such as the F distribution to help evaluate the sums of squares, logistic regression cannot be considered a parametric test. One important consequence is that logistic regression does not involve the assumptions that other techniques such as MANOVA and discriminant analysis employ. That means you can use logistic regression with some data sets when you might not be able to use parametric tests.
For example, in logistic regression there is no assumption that the continuous variables are normally distributed. There is no assumption that the continuous variables are related in a linear rather than curvilinear fashion. There is no assumption that their variances and covariances are equivalent across groups.
So, logistic regression positions you to classify cases using continuous variables that might well fail to behave as required by MANOVA and discriminant analysis. It extends the number of data sets that you can classify.
But the same tradeoff is in play. Although you can get away with violations in logistic regression that might cause grief in MANOVA, nothing’s free. You pay for discarding assumptions with a loss of statistical power. Logistic regression simply is not as sensitive to small changes in the data set as is discriminant analysis.