The Noncentrality Parameter in the F Distribution
- Variance Estimates
- The Noncentrality Parameter and the Probability Density Function
Like this article? We recommend
Like this article? We recommend
Like this article? We recommend
An F-ratio is the ratio of two variances. When used in the context of the analysis of variance, one variance (the numerator) is based on the variability of the means of sampled groups. The other variance, in the denominator, is based on the variability of individual values within groups.
When the group means differ, the numerator involves a noncentrality parameter that stretches the distribution of the F-ratio, out to the right. This article discusses the meaning, calculation, and symbolic representation of the noncentrality parameter in the literature on ANOVA.
The final article in this series of four papers discusses the relationship of the noncentrality parameter to the calculation of the statistical power of the F-test in an ANOVA. The concept of statistical power is discussed in the first article in this series, and the statistical power of the t-test is discussed in the second article.
Variance Estimates
The rationale for the F-test in ANOVA provides that there are two ways to estimate the variance in the measures of treatment outcome:
- Between Groups. An estimate that depends exclusively on the differences between group means and the number of observations per group. The estimate is based a rearrangement of the formula for the standard error of the mean.
- Within Groups. An estimate that depends exclusively on the variance within each group. This estimate does not involve the differences between the group means, but is the average of the within-group variances.
Both figures estimate the same value: the variance of the individual outcome measures. We can form a ratio, termed the F-ratio, of the two variance estimates, dividing the between-groups estimate by the within-groups estimate.
The derivation of the formulas for the variability within groups and the variability between groups is not given here; see Statistical Analysis: Microsoft Excel 2010 (Que Publishing, 2011) for that information. It turns out, though, that:
- The within groups figure comprises the variance in the population from which the subjects were sampled.
- The between groups figure comprises the variance in the same population, plus any variance attributable to the differences between the group means.
Central F Distributions
So we wind up with this F-ratio:
F = (σε2 + σΒ2) / σε2
where:
σε2 = Estimate of population variance
and
σΒ2 = Estimate of variability due to differences between group means
If there are no differences between group means in the population, then σΒ2 is zero and the F-ratio is:
F = (σε2 + 0) / σε2 = 1.0
When σΒ2 is zero, the ratio follows a central F distribution.
We sample the subjects that make up our treatment groups and control groups from populations: the population of subjects from which we obtain a sample for Group 1, the population of subjects from which we obtain a sample for Group 2, and so on. Those populations would have mean values on the outcome measure if we were able to administer the treatment to a full population. If there is no difference among those population means, we expect the F-ratio to equal 1.0.
Of course, using our sample data, we often calculate an F-ratio that does not equal 1.0, even when the F-ratio comes from a central F distribution. That's because our samples are not perfectly representative of the populations on which they are based. Figure 1 shows the relative frequency of different F-ratios based on samples when there are no differences in the means of the populations.
)
Figure 1 The distribution of F-ratios, when there are no population differences in group means, is termed the central F distribution.
The distribution of central F-ratios is determined solely by the number of degrees of freedom for the numerator and the number of degrees of freedom for the denominator.
You generally decide that an F-ratio is "statistically significant" if you would observe it by the accident of sampling error, when its population value is 1.0, less than 5% of the time (that is, p < .05), or less than 1% of the time (p < .01), or less than 0.1% of the time (p < .001) and so on. Figure 1 shows the relative likelihood of those accidents of sampling error.
The likelihoods are termed alpha levels. You might decide that you want to limit the mistake of deciding there are differences between means, when there are not, to 5% of the possible experiments like this one that you might carry out. Then you would set alpha to .05.
If your eventual F-ratio turned out to be larger than the F-ratio that cuts off the top 5% of the distribution, you would decide that a true difference in means exists. If no difference in the population means exists, your result would come about only 5% of the time. It is more rational to decide that there is a difference between the population means than it is to decide that a 19-to-1 shot came home.
Noncentral F Distributions
But what if there is a difference in the population means? In that case, the distribution of F ratios does not follow the central F distribution shown in Figure 1. It is instead what's called a noncentral F. Figure 2 shows several noncentral F distributions.
)
Figure 2 The larger the noncentrality parameter, the more stretched-out the F distribution.
The noncentrality parameter is closely related to the σΒ2 term in the expected value of the F-ratio, shown earlier as:
F = (σε2 + σΒ2) / σε2
When there are differences between the group means in the population, the term σΒ2 is expected to be greater than zero: It is the variance of the group means. So when that variance, the σΒ2 term in the numerator, is greater than zero, the numerator gets larger, as does the value of the F-ratio, and the distribution stretches out to the right in its chart.
The noncentrality parameter has been defined variously and inconsistently for many years, but the literature on statistics appears to be settling in on both a generally accepted symbol for the parameter (the Greek letter lambda, λ) and on the formula. For example, one generally well-regarded text in its 1968 edition used the Greek character δ to represent the noncentrality parameter and gave this formula:
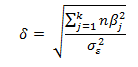
where j indexes the groups, n is the number of observations per group, and β is the difference between a group mean and the grand mean.
But the same book's 2013 edition gives the character as λ and the equation as:
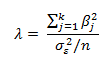
which is algebraically equivalent except that it is the square of the version in the 1968 edition. With an equal number of observations per group, λ is the ratio of the ANOVA table's Sum of Squares Between to its Mean Square Within.
Other well-regarded books, which are now 30 years old, confuse the noncentrality parameter with a related figure, Φ, which has for decades been used to look up the value of statistical power in charts. For more on how Φ is used (and to get a sense of the difficulty of using those old charts) see, for example, this article excerpt from the Journal of the American Statistical Association.