Maps in Microsoft BizTalk Server 2010
This chapter is from the book
This chapter is from the book
This chapter is from the book
As mentioned several times in Chapter 2, “Schemas,” schemas are really important in your BizTalk solution. This is partly because they serve as the contract between systems and are therefore useful for determining which system is faulty. And it is partly because updating them is potentially particularly laborious because so many other artifacts depend on them.
One of the artifacts that depends heavily on schemas is a map. A map is a transformation from one Extensible Markup Language (XML) document into another XML document, and it is used in three places:
- To transform incoming trading-partner-specific or internal-system-specific messages into an internal XML format. This is achieved by setting the map on a receive port or on the receive side of a two-way port.
- To transform outgoing internal XML format messages into the trading-partner-specific or internal-system-specific formats they need to receive. This is achieved by setting the map on a send port or on the send side of a two-way port.
- To perform transformations needed inside business processes that do not involve receiving or sending messages to and from trading partners or internal systems.
Maps are developed inside Visual Studio 2010 using the BizTalk Mapper tool. This tool has a developer friendly interface, which allows you to have a tree structure view of both input and output schemas used by the map. When viewing these two tree structures, you can then use either direct links from nodes in the source schema to nodes in the destination schemas, or you can use functoids that perform some processing on its input and then generates output, which can be used either as input for other functoids or as a value that goes to a node in the destination schema.
Although maps are developed in a nice, user-friendly interface and stored as a BizTalk-specific XML format, they are compiled into Extensible Stylesheet Language Transformations (XSLT) when the Visual Studio 2010 project is compiled. In fact, you can even provide your own XSLT instead of using the Mapper if you are so inclined or if you need to do complex transformations that you cannot do with the Mapper. Only XSLT 1.0 is supported for this, though.
Incoming files are either arriving as Extensible Markup Language (XML) or converted into XML in the receive pipeline, which happens before the map on the receive port is executed. Also, on a send port, the map is performed before the send pipeline converts the outgoing XML into the format it should have when arriving at the destination. This makes it possible for the Mapper and the XSLT to work for all files BizTalk handles because the tree structure shown in the Mapper is a representation of how the XML will look like for the file and because the XSLT can only be performed and will always be performed on XML. This provides a nice and clean way of handling all files in BizTalk in the same way when it comes to transformations.
The Mapper
This section walks you through the main layout of the BizTalk Mapper and describes the main functions and features.
Developing a map is done inside Visual Studio 2010 just as with other BizTalk artifacts. Follow these steps to add a map to your project:
- Right-click your project.
- Choose Add, New Item.
- Choose Map and provide a name for the map. This is illustrated in Figure 3.1
Layout of Mapper
After adding the map to your project, it opens in the BizTalk Mapper tool, which is shown in Figure 3.2.
The Mapper consists of five parts:
- To the left a Toolbox contains functoids that you can use in your map. Functoids are explained in detail later. If the Toolbox is not present, you can enable it by choosing View, Toolbox or by pressing Ctrl+Alt+X.
- A Source Schema view, which displays a tree structure of the source schema for the map.
)
Figure 3.1 Add a new map to your project.
)
Figure 3.2 Overview of the BizTalk Mapper.
- The Mapper grid, which is where you place all functoids used by the map and also where lines between nodes in the source and destination schemas are shown. Above the Mapper grid there is a toolbar with some functionality that is described later.
- A Destination Schema view, which displays an inverted tree structure of the destination schema. An inverted tree structure means that it unfolds right to left rather than left to right, which is normal.
- The Properties window, which shows the properties that are available depending on what is the active part of the Mapper. For instance, it can show properties for a functoid in the map, a node in the source schema, or the map itself. If the Properties window is not present, you can always get to it by right-clicking the item for which you need the properties and choosing Properties or by clicking an item and pressing F4.
Initial Considerations
When developing a transformation, you usually assume that the input for the map is always valid given the schema for the source. This requires one of two things, however:
- Validation has been turned on in the receive pipeline, meaning that the pipeline used is either a custom pipeline with the XML validator component in it or validation has been enabled on the disassembler in use.
- You trust the sending system or trading partner to always send valid messages and therefore do not turn on validation. This can be done for performance reasons. The downside to this is, of course, that it can provide unpredictable results later on in the process and troubleshooting will be hard.
Either way, your business must decide what to do. Should validation be turned on so that errors are caught in the beginning of the process, or can it be turned off either because you trust the sender or because you decide to just deal with errors as they arise? As a developer of a transformation, you need to know the state of the incoming XML. If a map fails at some point, this can lead to unexpected behavior, like the following:
- Orchestrations can start failing and get suspended because the logic inside the orchestration is based on valid input.
- Incoming messages can get suspended if the map fails.
- If you validate your XML in a send pipeline and the map generated invalid XML according to the schema, the validation will fail, and the message will get suspended and not delivered to the recipient.
After this is dealt with, you can start looking at how to implement the map. Most of a map is usually straightforward, and you just specify which nodes in the source should be mapped to which nodes in the destination schema. For instance, the quantity on an order line is usually just mapped to the relevant quantity node in the destination schema that may have another name, namespace, or other. This works fine, as long as the cardinality and data type match between the source node and the destination node.
Special cases, however, must also be dealt with. Handling all the special cases can take a long time just to specify, and this time should be taken because you want to generate valid output. Determining how to handle these cases is usually not something a BizTalk developer can do alone because you need to specify what actions the business wants to perform in these cases. Therefore, this specification should be done in cooperation between a businessperson and a BizTalk developer. The most common special cases are described in the following paragraphs.
Different Data Types
If the source node and destination node have different data types, you might run into issues. Naturally, if you are mapping from one data type to another data type that has fewer restrictions, you are safe. If you are mapping form a node of type decimal to a node of type string, for example, you can just do the mapping because anything that can be in a node of type decimal can also be in a node of type string. The other way around, however, is not so easy. You have three options:
- Change the source schema either by changing the data type or by placing a restriction on the node that limits the possible values. You can use a regular expression to limit a string node to only contain numbers, for instance.
- Change the destination schema by changing the data type of the relevant node. Relaxing restrictions, however, can give you trouble later on in the business process.
- Handle the situation inside the map. After schemas are made and agreed upon with trading partners, they are not easy to change. So, you probably want to address this issue inside the map. You can use functoids, which are explained later, to deal with any inputs that are not numeric values.
Different Cardinality
If the source node is optional and the destination node is not, you have an issue. What you should do in case the input node is missing is a matter of discussion. Again, you have three options:
- Change the source schema by changing the optional node to be required.
- Change the destination schema by changing the relevant node to be optional.
- Handle the situation inside the map. You probably want to address this issue inside the map. You can use functoids to deal with the scenario where the source node is missing. This can either mean mapping a default value to the destination node or throwing an exception.
Creating a Simple Map
To start creating the map, you must choose which schema to use as the input for the map and which schema to use for the output. These are also known as the source and the destination schemas of the map.
To choose the source schema, click Open Source Schema on the left side of the Mapper. Doing so opens a schema selector, as shown in Figure 3.3.
)
Figure 3.3 Choosing a schema to be used for the map.
In the schema selector, you can choose between schemas that exist in the current project or schemas that are in projects you have referenced from this project. You cannot add a reference from this window, so references must be added before choosing schemas in other projects. You choose a schema for the destinations schema by clicking Open Destination Schema and choosing a schema in the same way. If you choose a schema that has multiple root nodes, you get a screen where you need to choose which one of them to use as the root node for the schema you have chosen.
After choosing the two schemas involved, you are ready to start designing your map. This is mainly done by dragging links between the source schema and the destination schema and possibly doing some work on the source values before they are put into the destination schema.
For values that just need to be copied from a source node to a destination node, you can simply drag a link between the nodes in question. Just click either the source or the destination node and hold down the left mouse button while you move the mouse to the other element. Then release it. Doing so instructs the Mapper that you want the values from the source node copied to the node in the destination schema when the map is executed.
In between the source and destination schema is the Mapper grid. This grid is used to place functoids on, which perform some work on its input before its output is either used as input for another functoid or sent to the destination schema. Functoids are described later in this chapter. Figure 3.4 shows a simple map with a single line drawn and a single functoid on it. The functoid is an “Uppercase” functoid that converts the input it gets into uppercase and outputs that.
)
Figure 3.4 Simple map with one line drawn and one functoid used.
The map grid is actually larger than what you can see on your screen. If you move the mouse to the edge of the grid, the cursor changes to a large arrow, and you can then click to let the grid scroll so that you can see what is located in the direction the arrow points. You can also click the icon illustrating a hand in the toolbar at the top of the Mapper grid to get to the Panning mode, where you can click the grid and drag it around.
If you need to move a functoid to another location on the grid, you need to first click it. When it is selected, you can drag it anywhere on the grid.
If you need to move a collection of functoids at the same time, you can click the grid and drag a rectangle to mark the functoids and links you want to move. After marking a rectangle on the grid, you can just click somewhere inside it and drag the entire rectangle to another location on the grid. Another option is to select multiple functoids/links by holding down Ctrl while clicking them. After they are selected, you can drag them to where you want them.
Sometimes you need to change one end of a link if, for instance, some destination node should have its value from another node than it does at the time. You can do this either by deleting the existing link and adding a new one or by clicking the link and then dragging one end of the link that has been changed to a small blue square to the new place. Changing the existing link instead of adding a new link has some advantages:
- All the properties you may have set on the link remain the same, so you do not have to set them again.
- If the link goes into a functoid, this will keep the order in which they are added. The order parameters are added to a functoid is important, so it is nice to not have to go in and change that order after deleting a link and adding a new one.
The window shown in Figure 3.4 has a toolbar at the top of the Mapper grid in the middle. This toolbar is new in the Mapper in BizTalk 2010 and contains some functionality that wasn’t available in earlier versions of BizTalk.
One of the new features is the search bar. If you enter something in the search text box, the Mapper finds occurrences of this text within the map. The search feature can search in the source schema, the destination schema, and properties of the functoids such as name, label, comments, inputs, and scripts. You use the Options drop-down to the right of the search text box to enable and disable what the search will look at. Once a search is positive, you get three new buttons between the search text box and the Options drop-down. The three buttons enable you to find the next match going up, find the next match going down, or to clear the search. The search features are marked in Figure 3.5.
Another new option is the zoom feature. You get the option to zoom out, allowing you to locate the place on the grid you want to look at. For zooming, you can use the horizontal bar in the Mapper, as shown in Figure 3.6, or you can hold down the Ctrl key while using the scroll wheel on your mouse.
To let the map know that a value from one node in the source is to be mapped into a specific node in the destination schema, you drag a link between the two nodes. When you drag a link between two record nodes, you get a list of options:
- Direct Link: This creates a direct link between the two records. This helps the compiler know what levels of the source hierarchy correspond to what levels in the hierarchy of the destination schema.
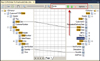
Figure 3.5 The search feature in a map.
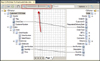
Figure 3.6 The zoom option in a map.
- Link by Structure: This lets the Mapper automatically create links between the child nodes of the two records you created the link between. The Mapper attempts to create the links based on the structure of the children.
- Link by Name: This lets the Mapper automatically create links between the child nodes of the two records you created the link between. The Mapper attempts to create the links based on the names of the children.
- Mass Copy: This adds a Mass Copy functoid that copies all subcontent of the record in the source to the record in the destination.
- Cancel: This cancels what you are doing.
)
)
This functionality is also new in BizTalk 2010. In earlier versions, there was a property on the map you could set before you dragged a link between two records.
Functoids and links can be moved between grid pages in two ways:
- After selecting one or more functoids/links, right-click them, and choose Move to Page or press Ctrl+M Ctrl+M. Doing so opens a small screen where you can choose between the existing pages or choose to create a new page to place the selected items on.
- Drag the selected items to the page tab of the page where you want them to appear. The page appears, and then you can place the items where you want them to be.
If you need a copy of a functoid, retaining all the properties of the functoid, you can also do this. Select a number of items and use the normal Windows shortcuts to copy, cut, and paste them. You can also right-click and choose Copy, Cut, or Paste. You can copy across grid pages, maps, and even maps in different instances of Visual Studio 2010. Some limitations apply to this, however, such as when links are copied and when not. For a full description, see refer to http://msdn.microsoft.com/en-us/library/ff629736(BTS.70).aspx.
For large schemas, it can be hard to keep track of which nodes are used in the map and in what context. To assist you, the Mapper has a feature called relevance tree view. This is a feature you can enable and disable on the source and destination schemas independently, and the feature is enabled or disabled using the highlighted button in Figure 3.7. As you can see, the relevance tree view is enabled for the destination schema and not for the source schema. The destination schema has some nodes coalesced to improve readability. This means that all the nodes in the Header record that are placed above the OrderDate node, which is the only node currently relevant for the map, are coalesced into one icon, showing that something is here but it is not relevant. You can click the icon to unfold the contents if you want. Records containing no nodes that are relevant for the map are not coalesced, but collapsed.
)
Figure 3.7 Relevance view.
If you have marked a field in the source schema and need to find the field in the destination schema to map it into, you can get some help from the Mapper, as well. This feature is called Indicate Matches. If you select a node in the source schema, you can either press Shift+Space to enable it, or you can right-click it and choose Indicate Matches. Figure 3.8 shows how the screen looks after enabling the Indicate Matches feature on the OrderDate node in the source schema. As you can see, the Mapper adds some potential links to the map, and the one the Mapper thinks is the most likely is highlighted and thus the currently chosen one. If none of the suggestions match, you can press the Escape key or click with the mouse anywhere that is not one of the suggested links. If one of the links the Mapper suggests is the one you want, you have two ways of actually adding the link to the map:
- Use the mouse to click the link you want added to the map. Note that you cannot click the node in the destination that the link points to; it has to be the link itself.
- Use the up- and down-arrow keys to switch between the suggested links, and press the Enter key when the right link is chosen and highlighted.
If the feature guesses right the first time, you can add the link simply by pressing Shift+Space and then Enter. And you did not have to find the right place in the destination schema yourself.
Unfortunately, functoids are not part of this feature, so if you want the source node to be mapped into a functoid, this feature provides no help. You will have to do that yourself.
After a link has been dragged, it shows up in the Mapper as one of three types of links:
- A solid line: This is used for links where both ends of the link are visible in the current view of the Mapper, meaning that none of the two ends are scrolled out of the view.
- A dashed line that is a little grayed out: This is used for links where only one of the ends is visible in the current Mapper view and the other end is scrolled out of view.
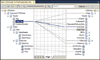
Figure 3.8 Illustration of the Indicate Matches feature.
- A dotted line that is grayed out: This is used for links where both ends are scrolled out of view but the link still goes through the current view of grid.
)
Figure 3.9 shows the different types of links.
)
Figure 3.9 The three types of links in a map.
Because there may be a lot of links that are of the third type, where none of the ends of the link is visible, you might want to choose to not have these links shown at all. To do this, you can use a feature on the toolbar called Show All/Relevant Links. This is enabled using a button, as shown in Figure 3.10.
)
Figure 3.10 Feature to show all or relevant links.
As you can see from Figure 3.10, one of links that was also present in Figure 3.9 is no longer shown in the Mapper. The link still exists and is valid. If one or both of the ends of the link come into view, the link reappears on the grid.
When a map gets filled up with functoids and links, it can get hard to keep track of which links and functoids are connected. To help you with this, the Mapper automatically highlights relevant links and functoids for you, if you select a link, a functoid, or a node in either the source or destination schema. For instance, take a look at Figure 3.11.
)
Figure 3.11 A map with lots of functoids.
Suppose you are troubleshooting to make sure the OrderDate in the destination schema is mapped correctly. If you click the OrderDate in the destination schema, you get the screen seen in Figure 3.12 instead. As you can see, the functoids and links that are relevant for mapping data into the OrderDate element have been highlighted and the rest of the links and functoids are now opaque, allowing you to focus on what is important. Had you clicked the link between the Equal functoid and the Value Mapping functoid, a subset of the links highlighted in Figure 3.12 would have been highlighted. If there are relevant links or functoids on another map page than the one currently shown, this is indicated by a small blue circle with an exclamation mark inside it to the left of the name of the page. Note also that the links have arrows on them, indicating the flow of data. This is also new in BizTalk 2010. In earlier versions of the Mapper, you could not have a functoid that gets its input from a functoid that was placed to the right of the first functoid on the grid. Now you can place your functoids where you want on the grid and the arrow will tell you which way the link goes. You cannot drag a link from a functoid to a functoid placed to the left of the first functoid, but after the link has been established, you can move the functoids around as you please.
)
Figure 3.12 The links and functoids relevant for mapping into the OrderDate element.
Another feature is the Auto Scrolling feature. This feature, which is enabled and disabled using the button shown in Figure 3.13, allows the Mapper grid to autoscroll to find relevant functoids given something you have selected. If all the functoids had been out of sight in the Mapper grid and you then clicked the OrderDate in the destination schema with this feature enabled, the grid would autoscroll to the view shown in Figure 3.14. The Auto Scroll feature also applies to other parts of the map than clicking a node in a schema. If you click a functoid, for instance, the Mapper highlights relevant links and functoids that are connected to the selected functoid and uses the Auto Scroll feature to bring them into view, if enabled.
)
Figure 3.13 Example of using the Auto Scroll feature.
Sometimes you want insert a default value into a field in the destination schema. You can do this by clicking the field in question and in the properties for the field finding the property called Value and setting a value here. Other than setting a value, you can use the drop-down to select the <empty> option. This lets the Mapper create an empty field in the output. As explained in Chapter 4, it can be useful to have a way of setting values in messages outside a transformation. Also, empty elements are needed for property demotion, as explained in Chapter 2, “Schemas.”
If you choose to set a default value in a field in the destination schema in the map, you can no longer map any values to this node in the destination. If you open the Extensible Markup Language Schema Definition (XSD) and set a default value on the field in the schema itself instead of setting it in the Mapper, the Mapper uses this value, but you are allowed to map a value to the field, which overwrites the value set in the XSD. Unfortunately, there is no built-in support for using the default value from the XSD if the field that is mapped to a node is optional and not present in the source at runtime. You have to do this with an If-Then-Else sort of structure, as discussed later in this chapter.
If you choose to set a default value in a field in the source schema, this value is used only when generating instances for testing the map from within Visual Studio 2010. The value is not used at runtime when the map is deployed.
If you click the map grid, you can see the properties of the map in the Properties window. If this window is not present, you can right-click the grid and choose Properties or just click the grid and press F4. Table 3.1 describes the available properties for the map.
Table 3.1. Properties of the Map
|
Property Name |
Description |
|
General |
|
|
Ignore Namespaces for Links |
Determines whether the map should be saved with information about the namespace of the nodes that are being linked. |
|
Script Type Precedence |
If a functoid that is used in the map can be both a referenced functoid or have (multiple) inline implementations, this property determines the order in which the implementations are to be preferred. |
|
Source Schema |
Read-only property that specifies the source schema to be used. |
|
Target Schema |
Read-only property that specifies the destination schema to be used. |
|
Compiler |
|
|
Custom Extension XML |
This property is used to point out a custom extension XML file that is used when providing your own XSLT instead of using the Mapper. This is explained more fully in the section "Custom XSLT." |
|
Custom XSL Path |
This property is used to point out a custom XSLT file that is used when providing your own XSLT instead of using the Mapper. This is explained more fully in the section "Custom XSLT." |
|
Custom Header |
|
|
CDATA section elements |
This property contains a whitespace-delimited list of element names that will have their values inside a CDATA construction to allow for otherwise-reserved characters. The whitespace can be a space or some other delimiter, but not, for instance, a comma. |
|
Copy Processing Instructions (PIs) |
Boolean value describing whether the map should copy any processing instructions from the source schema to the destination schema. Mostly used when transforming InfoPath documents. |
|
Doctype public |
Provides the value that will be written to the doctype-public attribute of the xsl:output element of the generated XSLT. |
|
Doctype system |
Provides the value that will be written to the doctype-system attribute of the xsl:output element of the generated XSLT. |
|
Indent |
Possible values are yes and no. If set to yes, the output of the map contains indentation to make the output more human-readable. Usually not needed, because systems often read the files and XML viewers show the XML nicely anyway. |
|
Media-Type |
Used to specify the value of the media-type attribute of the xsl:output element in the generated XSLT. This determines the MIME type of the generated XML. |
|
Method |
Possible values are xml, html and text. The value specified goes into the method attribute of the xsl:output element in the generated XSLT. |
|
Omit Xml Declaration |
Can be true (default) or false. Is used as the value for the omit-xmldeclaration attribute on the xsl:output element in the generated XSLT. Determines whether to omit the XML declaration at the top of the generated XML. |
|
Standalone |
Possible values are yes and no (default). Determines the value that is used in the standalone attribute of the xsl:output element in the generated XSLT. |
|
Version |
Specifies the value of the version attribute on the generated XML declaration, if any. |
|
XSLT Encoding |
This property contains a drop-down list of encodings. The chosen encoding is used to populate the encoding attribute of the xsl:output element. If you need another value than what is available, you can just enter it. The Mapper does not check the value, however, so check to make sure it is correct. |
If you click a link in the map grid, you can see and change some properties of the link. If the Properties window is not present, you can right-click the link and choose Properties or click the link and press F4. Table 3.2 describes the properties for links.
Table 3.2. Properties for Links
|
Property Name |
Description |
|
General |
|
|
Label |
In this property, you can specify a label that is used for this link. |
|
Link Source |
Read-only property that specifies the source of the link. |
|
Link Target |
Read-only property that specifies the target of the link. |
|
Compiler |
|
|
Source Links |
This property has three possible values: If you use the value Copy Text Value, the link copies the value from the source of the link to the destination of the link. If you choose Copy Name, the name of the source field is copied rather than its value. If you choose Copy Text and Sub Content Value, the source node and all its inner content is copied. This is like the InnerText property of a .NET System.Xml.XmlNode. |
|
Target Links |
This property determines the behavior of the link with regard to creating output nodes. Possible value are Flatten Links, Match Links Top Down, and Match Links Bottom Up. The value in this property allows the compiler to know how to match the source structure to the destination structure so that loops in the generated XSLT can be generated at the correct levels. Usually the default value is fine, but at times when you are mapping form recurring structures that are on different levels in the source and destination schemas, this can be useful. |
Clicking the map file in Solution Explorer reveals some properties that you can set on the Visual Studio 2010 project item. Table 3.3 describes these properties.
Table 3.3. Properties for the Visual Studio 2010 Project Item
|
Property Name |
Description |
|
Advanced |
|
|
Build Action |
This property determines what the compiler does with the .BTM file when building the project. A value of None instructs the compiler to ignore the file. A value of BtsCompile instructs the compiler to compile the map and include it in the assembly. |
|
Fully Qualified Name |
This is a read-only property displaying the fully qualified .NET name. It is a concatenation of the .NET namespace, a period, and the .NET type name. |
|
Namespace |
The .NET namespace this map belongs to. This has nothing to do with any namespaces used in schemas. As with normal code, the namespace is usually the same name as the project the file belongs to. Remember to change this if you move the .BTM file among projects. |
|
Type Name |
The .NET type name of the map. This corresponds to the class name of a class in a project. The type name is usually the same as the filename of the .BTM file. |
|
Misc |
|
|
File Name |
The filename of the map file. You can change this instead of renaming the file in Solution Explorer if you are so inclined. |
|
Full Path |
Read-only property containing the full path to the map file. |
|
Test Map |
|
|
TestMap Input |
Determines how Visual Studio 2010 can find a file to use as input when testing the map. A value of XML means that the file given in TestMap Input Instance is an XML file. A value of Native means that the file given in TestMap Input Instance is in the native format of the schema, which is in this case usually a flat file or an EDI schema, but it can also be XML. The last option is a value of Generated Instance, which lets Visual Studio 2010 generate an XML instance to be used for the test. |
|
TestMap Input Instance |
The full path to the file to be used for testing the map. This is used only if the TestMap Input property does not have a value of Generate Instance. |
|
TestMap Output |
Determines the format of the output from testing the map. Can be XML, which outputs the XML the map has produced, or Native, which translates the XML generated by the map into the destination format like EDI, flat file, or something else. |
|
TestMap Output Instance |
The full path of where to place the output from testing the map. If not specified, the output is generated in your temp folder, and the output window provides a link to the specific file when testing the map. |
|
Validate TestMap Input |
Boolean value that determines whether the input for the map should be validated against the source schema before performing the map. If you know the instance to be valid, there is no need for validation, because this will only take time. On the other hand, making sure every time you test the map that the input is valid will confirm that you haven't accidentally changed the instance or the schema. |
|
Validate TestMap Output |
Boolean value that determines whether the output of the map should be validated against the destination schema. When developing your map, you will usually want to turn this off, to view the result of the partially complete map you have built. Then turn it on when you want to actually test the map in its entirety. |